"Hello world!" 混乱代码比赛第一名作品解析,hello第一名,未经许可,禁止转载!英文
"Hello world!" 混乱代码比赛第一名作品解析,hello第一名,未经许可,禁止转载!英文
本文由 编橙之家 - atupal 翻译,黄利民 校稿。未经许可,禁止转载!英文出处:earwig.github.io。欢迎加入翻译组。
几个月前,我在这届的 Code Golf 比赛中获得了第一名,这个比赛的主题是写出最怪异最混乱的「Hello world! 」打印程序。我决定写一篇文章解释它到底是怎么运行的。下面是我的代码,语言是 Python2.7:
Python
(lambda _, __, ___, ____, _____, ______, _______, ________:
getattr(
__import__(True.__class__.__name__[_] + [].__class__.__name__[__]),
().__class__.__eq__.__class__.__name__[:__] +
().__iter__().__class__.__name__[_____:________]
)(
_, (lambda _, __, ___: _(_, __, ___))(
lambda _, __, ___:
chr(___ % __) + _(_, __, ___ // __) if ___ else
(lambda: _).func_code.co_lnotab,
_ << ________,
(((_____ << ____) + _) << ((___ << _____) - ___)) + (((((___ << __)
- _) << ___) + _) << ((_____ << ____) + (_ << _))) + (((_______ <<
__) - _) << (((((_ << ___) + _)) << ___) + (_ << _))) + (((_______
<< ___) + _) << ((_ << ______) + _)) + (((_______ << ____) - _) <<
((_______ << ___))) + (((_ << ____) - _) << ((((___ << __) + _) <<
__) - _)) - (_______ << ((((___ << __) - _) << __) + _)) + (_______
<< (((((_ << ___) + _)) << __))) - ((((((_ << ___) + _)) << __) +
_) << ((((___ << __) + _) << _))) + (((_______ << __) - _) <<
(((((_ << ___) + _)) << _))) + (((___ << ___) + _) << ((_____ <<
_))) + (_____ << ______) + (_ << ___)
)
)
)(
*(lambda _, __, ___: _(_, __, ___))(
(lambda _, __, ___:
[__(___[(lambda: _).func_code.co_nlocals])] +
_(_, __, ___[(lambda _: _).func_code.co_nlocals:]) if ___ else []
),
lambda _: _.func_code.co_argcount,
(
lambda _: _,
lambda _, __: _,
lambda _, __, ___: _,
lambda _, __, ___, ____: _,
lambda _, __, ___, ____, _____: _,
lambda _, __, ___, ____, _____, ______: _,
lambda _, __, ___, ____, _____, ______, _______: _,
lambda _, __, ___, ____, _____, ______, _______, ________: _
)
)
)
字符串文字是不允许使用的,但为了让它更有趣,我还加了一些其他的限制。那就是它 必须得是一个使用尽可能少的内建函数和不使用整数常量的单独的表达式(所以没有print语句)
开始
因为我们不能使用print,我们可以将字符串写入stdout文件对象:
import sys
sys.stdout.write("Hello world!n")
但是让我们使用一些更底层的:os.write()。我们需要知道 stdout 的文件描述符, 也就是 1(你可以通过sys.stdout.fileno()来验证)
import os os.write(1, "Hello world!n")
我们想要一个单独的表达式,所以我们可以使用__import__():
__import__("os").write(1, "Hello world!n")
我们还想把write()变得更迷惑一点,所以我们可以 丢出getattr()
getattr(__import__("os"), "write")(1, "Hello world!n")
这只是开始,从现在开始所有的事情都是在混乱这三个字符串和这个整数。
用字符串组成字符串
“os” 和 “write” 非常简单,所以我们可以通过把一些内置的类的名字的一些部分 连接起来得到。有许多的方法来做这个,我的选择的方法如下:
- “o” 来自 bool 的第二个字母:
True.__class__.__name__[1] - “s” 来自 list 的第三个字母:
[].__class__.__name__[2] - “wr” 来自 wrapper_descriptor 的头两个字母,你可以在一个 CPython 的实现细节中找到这些内建类的方法(详情戳这):
().__class__.__eq__.__class__.__name__[:2] - “ite” 来自 tupleiterator 的第六到八个字母,对象的类型通过调用 Python 元组的
iter()方法得到:().__iter__().__class__.__name__[5:8]
我们已经完成一些了!
Python
getattr(
__import__(True.__class__.__name__[1] + [].__class__.__name__[2]),
().__class__.__eq__.__class__.__name__[:2] +
().__iter__().__class__.__name__[5:8]
)(1, "Hello world!n")
“Hello world!n” 更复杂一些。我们准备将它编码为一个大整数,通过把每个 字符的 ASCII 码乘以一个 256 的幂,幂指数为字母在 “Hello worldn” 中的索引 。换句话说,下面的和式:
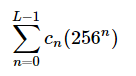
其中 L 是字符串的长度,cn 是字符串中第 n 个字符的 ASCII 码。如何生成这个数:
Python>>> codes = [ord(c) for c in "Hello world!n"] >>> num = sum(codes[i] * 256 ** i for i in xrange(len(codes))) >>> print num 802616035175250124568770929992
然后现在我们得把这个数转换回字符串。我们使用了一个简单的递归算法:
Python>>> def convert(num): ... if num: ... return chr(num % 256) + convert(num // 256) ... else: ... return "" ... >>> convert(802616035175250124568770929992) 'Hello world!n'
使用 lambda 表达式把它重写为一行:
Pythonconvert = lambda num: chr(num % 256) + convert(num // 256) if num else ""
现在我们使用匿名递归把它转变成一个单独的表达式。这需要 使用一个组合算子。如下:
Python>>> comb = lambda f, n: f(f, n) >>> convert = lambda f, n: chr(n % 256) + f(f, n // 256) if n else "" >>> comb(convert, 802616035175250124568770929992) 'Hello world!n'
现在我们只需要把函数定义替换到表达式中就得到了我们要的函数:
Python>>> (lambda f, n: f(f, n))( ... lambda f, n: chr(n % 256) + f(f, n // 256) if n else "", ... 802616035175250124568770929992) 'Hello world!n'
现在我们可以把它粘贴到我们之前的代码中了,然后做一些变量替换:f ->, n -> _:
Python
getattr(
__import__(True.__class__.__name__[1] + [].__class__.__name__[2]),
().__class__.__eq__.__class__.__name__[:2] +
().__iter__().__class__.__name__[5:8]
)(
1, (lambda _, __: _(_, __))(
lambda _, __: chr(__ % 256) + _(_, __ // 256) if __ else "",
802616035175250124568770929992
)
)
函数内部
在我们之前转换后的函数中还有一个 “” (记住:不允许使用字符串字面量), 和一个我们得用某种方法藏起来的整数。我们先从空字符串开始。我们可以 通过检查一些随机的函数的内件过程中制造一个:
Python>>> (lambda: 0).func_code.co_lnotab ''
我们这里真正做的事情是查找函数中代码对象的行号表。因为函数是匿名 的,所以没有行号,得到的字符串就是空的。通过把 0 替换为 _ 使得它 更具有迷惑性(这不影响,因为这个函数并没有被调用),然后把代码粘贴 到之前的代码中。我们还把 256 重构了一些,把它作为一个参数传递给我们的 混淆后的convert()。这只需要在组合算子中添加一个参数就可以了:
getattr(
__import__(True.__class__.__name__[1] + [].__class__.__name__[2]),
().__class__.__eq__.__class__.__name__[:2] +
().__iter__().__class__.__name__[5:8]
)(
1, (lambda _, __, ___: _(_, __, ___))(
lambda _, __, ___:
chr(___ % __) + _(_, __, ___ // __) if ___ else
(lambda: _).func_code.co_lnotab,
256,
802616035175250124568770929992
)
)
迂回
让我们来处理一下另外一个不同的问题吧,。我们想在我们的代码中混淆数字, 但每次要用的时候都重新混淆一遍很麻烦(而且一点都没意思)。如果我们能 实现,例如range(1, 9) == [1, 2, 3, 4, 5, 6, 7, 8],然后我们就 可以把我们现在做的包装到一个函数中,然后这个函数包含 1-8 这几个数字做 为函数参数,于是我们只需把代码体中相应的数字字面量替换成这些变量就可以了:
(lambda n1, n2, n3, n4, n5, n6, n7, n8:
getattr(
__import__(True.__class__.__name__[n1] + [].__class__.__name__[n2]),
...
)(
...
)
)(*range(1, 9))
虽然我们还需要组成 256 和 802616035175250124568770929992, 但他们可以通过 这 8 个“基本的”的数字通过四则运算创造出来。1 到 8 的选择是任意的,这算一个 折中的方法。
我们可以通过一个函数的代码对象得到它的参数个数:
Python>>> (lambda a, b, c: 0).func_code.co_argcount 3
构建一个元组的参数个数为 1 到 8 的函数:
Python
funcs = (
lambda _: _,
lambda _, __: _,
lambda _, __, ___: _,
lambda _, __, ___, ____: _,
lambda _, __, ___, ____, _____: _,
lambda _, __, ___, ____, _____, ______: _,
lambda _, __, ___, ____, _____, ______, _______: _,
lambda _, __, ___, ____, _____, ______, _______, ________: _
)
使用递归算法,我们就能把这个转变成range(1, 9)的输出:
>>> def convert(L): ... if L: ... return [L[0].func_code.co_argcount] + convert(L[1:]) ... else: ... return [] ... >>> convert(funcs) [1, 2, 3, 4, 5, 6, 7, 8]
像前面一样,我们把这个变成 lambda 表达式:
Pythonconvert = lambda L: [L[0].func_code.co_argcount] + convert(L[1:]) if L else []
然后,变成匿名递归形式:
Python>>> (lambda f, L: f(f, L))( ... lambda f, L: [L[0].func_code.co_argcount] + f(f, L[1:]) if L else [], ... funcs) [1, 2, 3, 4, 5, 6, 7, 8]
为了更有趣,我们将把我们计算参数个数的操作变成一个额外的函数参数,然后混淆一些变量的名字:
Python
(lambda _, __, ___: _(_, __, ___))(
(lambda _, __, ___:
[__(___[0])] + _(_, __, ___[1:]) if ___ else []
),
lambda _: _.func_code.co_argcount,
funcs
)
现在新的问题来了: 我们得用某种方法来隐藏 0 和 1。我们可以通过 检查任意函数的局部变量的个数来得到 0 和 1:
Python>>> (lambda: _).func_code.co_nlocals 0 >>> (lambda _: _).func_code.co_nlocals 1
即使这两个函数的函数体是一样的,但前面一个函数中 _ 不是一个参数,它也不是在 函数中定义的,所以 Python 把它解释为一个全局变量:
Python
>>> import dis
>>> dis.dis(lambda: _)
1 0 LOAD_GLOBAL 0 (_)
3 RETURN_VALUE
>>> dis.dis(lambda _: _)
1 0 LOAD_FAST 0 (_)
3 RETURN_VALUE
这不管 _ 在全局域中被定义为啥都没关系。
把这些应用一下:
Python
(lambda _, __, ___: _(_, __, ___))(
(lambda _, __, ___:
[__(___[(lambda: _).func_code.co_nlocals])] +
_(_, __, ___[(lambda _: _).func_code.co_nlocals:]) if ___ else []
),
lambda _: _.func_code.co_argcount,
funcs
)
现在我们可以把funcs替换进去了,然后使用*来传递 最后得到的整数列表,也即被分割为了 8 个变量:
(lambda n1, n2, n3, n4, n5, n6, n7, n8:
getattr(
__import__(True.__class__.__name__[n1] + [].__class__.__name__[n2]),
().__class__.__eq__.__class__.__name__[:n2] +
().__iter__().__class__.__name__[n5:n8]
)(
n1, (lambda _, __, ___: _(_, __, ___))(
lambda _, __, ___:
chr(___ % __) + _(_, __, ___ // __) if ___ else
(lambda: _).func_code.co_lnotab,
256,
802616035175250124568770929992
)
)
)(
*(lambda _, __, ___: _(_, __, ___))(
(lambda _, __, ___:
[__(___[(lambda: _).func_code.co_nlocals])] +
_(_, __, ___[(lambda _: _).func_code.co_nlocals:]) if ___ else []
),
lambda _: _.func_code.co_argcount,
(
lambda _: _,
lambda _, __: _,
lambda _, __, ___: _,
lambda _, __, ___, ____: _,
lambda _, __, ___, ____, _____: _,
lambda _, __, ___, ____, _____, ______: _,
lambda _, __, ___, ____, _____, ______, _______: _,
lambda _, __, ___, ____, _____, ______, _______, ________: _
)
)
)
移位
快要完成了!我们将把n{1..8}这几个变量替换成, _,, _等等。 这会使得我们内部函数使用的变量更具有迷惑性。这不会有问题,因为作用域规则 保证了我们每次使用的都是正确的变量。这也是我们为啥把 256 移出到 _ 等于 1 的地方而不是在convert()函数内部的一个原因。代码更长了,所以我只贴了 第一部分:
(lambda _, __, ___, ____, _____, ______, _______, ________:
getattr(
__import__(True.__class__.__name__[_] + [].__class__.__name__[__]),
().__class__.__eq__.__class__.__name__[:__] +
().__iter__().__class__.__name__[_____:________]
)(
_, (lambda _, __, ___: _(_, __, ___))(
lambda _, __, ___:
chr(___ % __) + _(_, __, ___ // __) if ___ else
(lambda: _).func_code.co_lnotab,
256,
802616035175250124568770929992
)
)
)
现在只剩两件事了。我们先从容易的一个开始: 256 = 2^8, 所以我们可以通过把它 重写为1 << 8得到(使用左移运算),或者使用我们混淆后的变量:_ << ________。
我们对 802616035175250124568770929992 也使用同样的方法。一个简单的分治法就能 把它拆成一些数的和,这些数本身也是一起位移的一些数的和。举个例子,如果我们有 112,我们可以把它拆成 96 + 16 即 (3 << 5) + (2 << 3)。我喜欢使用位移是因为 << 让我想起 C++ 中的std::cout << "foo"和 Python 中的 print chevron(print >>)。 它们都是带有误导性的另类 I/O 方法。
这个数字可以有多种分解方法,没有标准答案(毕竟我们也可以把它 分解为 (1<<0) + (1<<0) + …, 但是太没意思了)。我们应该有一些 大量的嵌套,但是我们仍会使用大部分我们的数字变量。显然,人工来做 是没意思的,所以我们想出一个算法,伪代码如下:
Python
func encode(num):
if num <= 8:
return "_" * num
else:
return "(" + convert(num) + ")"
func convert(num):
base = shift = 0
diff = num
span = ...
for test_base in range(span):
for test_shift in range(span):
test_diff = |num| - (test_base << test_shift)
if |test_diff| < |diff|:
diff = test_diff
base = test_base
shift = test_shift
encoded = "(" + encode(base) + " << " + encode(shift) + ")"
if diff == 0:
return encoded
else:
return encoded + " + " + convert(diff)
convert(802616035175250124568770929992)
我们的基本思路是测试在一个确定区间的不同的数字组合,直到我们找到 一个组合使得以一个为基数,一个为移位长度,然后是最接近 num 的(也就是 他们差的绝对值最小)。我们使用我们的分治法来分解成最好的基数和移位长度, 然后循环这个过程直到等于零,最后在每一步中加上得到数就可以了。
其中range()的参数:span,代表我们搜索的空间的宽度。这个数不能太大, 不然我们会得到 num 为基数,0 为移位长度的结果(因为 diff 是 0),并且因为 基数不可能是一个单独的变量,它会一直循环,无限递归。如果太小了,我们有可能 最后得到的是像上面说的(1<<0) + (1<<0) + ...这样的结果。实际上,我们想 随着递归深度的增加 span 随之变小。通过试错,我发现下面这个方程工作得很好:
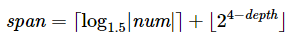
把伪代码转换成 Python 代码,然后做一些调整(支持 depth 参数以及调用负数的警告),如下:
Python
from math import ceil, log
def encode(num, depth):
if num == 0:
return "_ - _"
if num <= 8:
return "_" * num
return "(" + convert(num, depth + 1) + ")"
def convert(num, depth=0):
result = ""
while num:
base = shift = 0
diff = num
span = int(ceil(log(abs(num), 1.5))) + (16 >> depth)
for test_base in xrange(span):
for test_shift in xrange(span):
test_diff = abs(num) - (test_base << test_shift)
if abs(test_diff) < abs(diff):
diff = test_diff
base = test_base
shift = test_shift
if result:
result += " + " if num > 0 else " - "
elif num < 0:
base = -base
if shift == 0:
result += encode(base, depth)
else:
result += "(%s << %s)" % (encode(base, depth),
encode(shift, depth))
num = diff if num > 0 else -diff
return result
然后我们调用convert(802616035175250124568770929992),我们得到一个很好的分解:
>>> convert(802616035175250124568770929992) (((_____ << ____) + _) << ((___ << _____) - ___)) + (((((___ << __) - _) << ___) + _) << ((_____ << ____) + (_ << _))) + (((_______ << __) - _) << (((((_ << ___) + _)) << ___) + (_ << _))) + (((_______ << ___) + _) << ((_ << ______) + _)) + (((_______ << ____) - _) << ((_______ << ___))) + (((_ << ____) - _) << ((((___ << __) + _) << __) - _)) - (_______ << ((((___ << __) - _) << __) + _)) + (_______ << (((((_ << ___) + _)) << __))) - ((((((_ << ___) + _)) << __) + _) << ((((___ << __) + _) << _))) + (((_______ << __) - _) << (((((_ << ___) + _)) << _))) + (((___ << ___) + _) << ((_____ << _))) + (_____ << ______) + (_ << ___)
用这个替换 802616035175250124568770929992, 把所有部分组合起来:
Python
(lambda _, __, ___, ____, _____, ______, _______, ________:
getattr(
__import__(True.__class__.__name__[_] + [].__class__.__name__[__]),
().__class__.__eq__.__class__.__name__[:__] +
().__iter__().__class__.__name__[_____:________]
)(
_, (lambda _, __, ___: _(_, __, ___))(
lambda _, __, ___:
chr(___ % __) + _(_, __, ___ // __) if ___ else
(lambda: _).func_code.co_lnotab,
_ << ________,
(((_____ << ____) + _) << ((___ << _____) - ___)) + (((((___ << __)
- _) << ___) + _) << ((_____ << ____) + (_ << _))) + (((_______ <<
__) - _) << (((((_ << ___) + _)) << ___) + (_ << _))) + (((_______
<< ___) + _) << ((_ << ______) + _)) + (((_______ << ____) - _) <<
((_______ << ___))) + (((_ << ____) - _) << ((((___ << __) + _) <<
__) - _)) - (_______ << ((((___ << __) - _) << __) + _)) + (_______
<< (((((_ << ___) + _)) << __))) - ((((((_ << ___) + _)) << __) +
_) << ((((___ << __) + _) << _))) + (((_______ << __) - _) <<
(((((_ << ___) + _)) << _))) + (((___ << ___) + _) << ((_____ <<
_))) + (_____ << ______) + (_ << ___)
)
)
)(
*(lambda _, __, ___: _(_, __, ___))(
(lambda _, __, ___:
[__(___[(lambda: _).func_code.co_nlocals])] +
_(_, __, ___[(lambda _: _).func_code.co_nlocals:]) if ___ else []
),
lambda _: _.func_code.co_argcount,
(
lambda _: _,
lambda _, __: _,
lambda _, __, ___: _,
lambda _, __, ___, ____: _,
lambda _, __, ___, ____, _____: _,
lambda _, __, ___, ____, _____, ______: _,
lambda _, __, ___, ____, _____, ______, _______: _,
lambda _, __, ___, ____, _____, ______, _______, ________: _
)
)
)
然后大功告成。
相关内容
- Eric Raymond对于几大开发语言的评价,ericraymond,他的《大
- 人们对Python在企业级开发中的10大误解,python企业级,未
- 为什么数据科学家们选择了Python语言?,科学家python
- Python 3.5发布:新增模块,性能优化,对开发者更友好,
- 为什么会有 Python 3 的存在?,python,未经许可,禁止转
- Python 之父谈论 Python 的未来,python谈论,未经许可,禁止
- 学习Python的三种境界,python三种境界,此第一境也
- 不要再写出不能在 Python 4 中运行的程序了,写出pytho
- Python 是慢,但我无所谓,python我无所谓,对不了解我的
- 你该学习 Python 的 7 个理由,你该python, 诚然,它有点老
评论关闭