你所写过的最好的Python脚本是什么?,最好的python脚本,未经许可,禁止转载!英文
你所写过的最好的Python脚本是什么?,最好的python脚本,未经许可,禁止转载!英文
本文由 编橙之家 - Jason GUO 翻译。未经许可,禁止转载!英文出处:quora。欢迎加入翻译组。
这是网友在 Quora 上提的同名问答帖,本文摘编了排名前两名的答案。得到最多赞的用户介绍了他写的在Facebook上面感谢好友的脚本。排名第二的答案介绍了他写的点击一次自动字幕下载的脚本、IMDb信息查找脚本、theoatmeal.com网站漫画下载脚本和someecards.com下载脚本。该用户也因为这些脚本而得到了一份工作。
Akshit Khurana的答案,3.4k个赞同
使用脚本在Facebook上感谢五百多个在我生日那天给我祝福的朋友:
那是我21岁的生日,在那天发生了三件使得那天值得纪念的事情。这是那天发生的最后一件。
我倾向于亲自评论那些给我的祝福,但是使用Python去做这个将会更好。
Python
; html-script: false ]
# Thanking everyone who wished me on my birthday
import requests
import json
# Aman's post time
AFTER = 1353233754
TOKEN = ' <insert token here> '
def get_posts():
"""Returns dictionary of id, first names of people who posted on my wall
between start and end time"""
query = ("SELECT post_id, actor_id, message FROM stream WHERE "
"filter_key = 'others' AND source_id = me() AND "
"created_time > 1353233754 LIMIT 200")
payload = {'q': query, 'access_token': TOKEN}
r = requests.get('https://graph.facebook.com/fql', params=payload)
result = json.loads(r.text)
return result['data']
def commentall(wallposts):
"""Comments thank you on all posts"""
#TODO convert to batch request later
for wallpost in wallposts:
r = requests.get('https://graph.facebook.com/%s' %
wallpost['actor_id'])
url = 'https://graph.facebook.com/%s/comments' % wallpost['post_id']
user = json.loads(r.text)
message = 'Thanks %s :)' % user['first_name']
payload = {'access_token': TOKEN, 'message': message}
s = requests.post(url, data=payload)
print "Wall post %s done" % wallpost['post_id']
if __name__ == '__main__':
commentall(get_posts())
为了让程序工作,你需要通过合适的权限从Graph API Explorer(需要梯子)获得一个令牌(token)。脚本假设在一个特定时间戳之后发布的所有信息都是生日祝福。
稍微改动一下commentall函数后我还可以给每个信息点赞。Shashwat Lal Das | Facebook看到了被我的「自动收报机」引爆的赞、评论和具有相似的结构的评论后很快辨认出我可能做了上文里我所说的事情。
这个不是我写过的最好的Python脚本,但是它简单、高效并且有趣!
这个想法是我和Sandesh Agrawal在网络实验室里讨论时想出来的。谢谢你不做实验室的项目而是浪费时间陪我。
Manoj Memana Jayakumar的答案,1.7k个赞同
更新:我因为这些脚本得到了工作!
阅读:Manoj Memana Jayakumar’s answer to Quora: Has anyone been offered a job because of their Quora participation?
1、点击一次下载电影电视剧的字幕
我们都有过类似的经历:打开subscene或者opensubtitles等字幕下载网站,搜索电影、电视剧的名字,选择正确的压制版本,下载字幕,解压,剪切并把它粘贴到电影的文件夹内,重命名字幕文件来匹配我们的电影文件。
非常的单调乏味对吗?我写了一个脚本去下载正确匹配电影/电视剧的字幕,并且在你放置电影的文件夹下面保存它。所有这些只需要点击一次。
不太明白我说的是什么?
自己看这个视频吧(需要梯子):
Movie/TV Series Subtitles downloader Python script
是的。仅仅需要点击一次,就像施了咒语一样达到了目的。
最匹配你的电影或者电视剧的字幕被下载到和视频文件一样的文件夹内,被重命名成和你的视频文件相同的名字。
所有这些将在4秒内完成!
所以你现在所要做的就是打开电影,吃着爆米花并欣赏它。:)
源代码在GitHub上:subtitle-downloader
2、IMDb查找、Excel表格生成器
我是一个电影迷,我喜欢看电影。我收藏了大量的电影,因此我经常为选择看哪部电影而困扰。
所以我应该怎样做才能避免困惑并选择出今晚要看的电影?没错,上IMDb。
我打开http://imdb.com,输入电影的名字,看看得分,读读评论,然后弄清楚这部电影是否值得看。
但是我有太多电影了!谁会愿意在搜索框内输入我所有电影的名字呢?至少我不愿意,尤其是因为我认为「如果某件事是重复的,那么它可以被自动化」。
所以我用非官方的IMDb API写了一个Python脚本投抓取数据。下面是完成脚本后的结果。
我选择一个电影文件/文件夹,右击它,点击发送到,再点击IMDB.cmd。(顺便提一下,这样调用了我写的Python脚本)
瞧,那就是我们想要的!
我的浏览器打开了电影准确对应的IMDb页面!
所有这些,只需要点击一下按钮。
如果不明白这有多酷么,你可以节省多少时间,看看这个视频(需要梯子):
IMDb lookup python script
从现在开始你不需要打开浏览器,等待IMDb加载并且输入电影的名字。这个脚本帮你做好了这一切!
像之前一样,代码在GitHub上:imdb页面里面还有如何使用它的说明。当然,因为脚本需要去掉所有像”DVDRip, YIFY, BRrip”之类的无用的值,这个脚本使用时有着一定程度的误差。但是这个脚本在我测试的大多数电影中表现得很好。
更新(04-01-2014)
很多人认为每次找一部电影的详细介绍是笨拙的,他们问我是否可以写一个脚本以找到一个文件夹里所有电影的详细介绍。
我现在已经更新了脚本。这使得我们可以发送一个文件夹给脚本,让脚本分析文件夹里的所有子文件夹,从IMDb里抓取文件夹里所有电影的详细信息,并打开一个Excel文件,使得Excel里面的电影按照IMDb打分降序排列。
Excel文件里面也包含了像IMDb URL、年份、情节、类型、获奖情况、演员和其他任何你可能想在IMDb里找到的信息。
下面的图片展示了脚本执行后生成的Excel表格的样子。
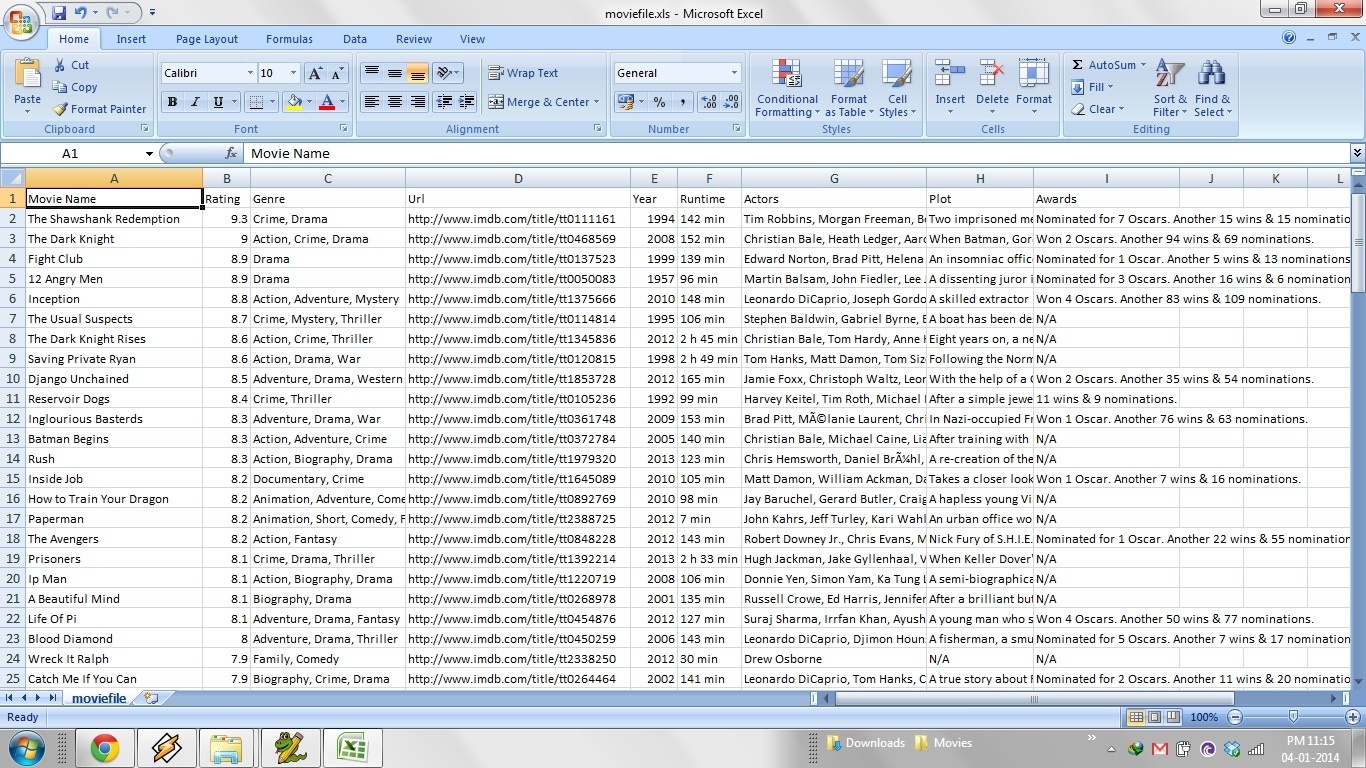
一个完全属于你自己的IMDb数据库!作为一个电影爱好者也不能要求得更多了;)
源代码在GitHub上:imdb。
编辑:
我正设法把这个脚本改成一个单页web应用,用户可以把多个文件夹拖曳放入网页,然后电影的详细信息将会显示在浏览器里的一个表格里。
如果有人愿意在这个项目中帮我创建应用的前端,包括基本的UI(基于基本的bootstrap就足够了)和拖曳窗口的话,我会很高兴。
如果你有兴趣加入这个项目,请通知我。:)
3、theoatmeal.com网站漫画下载器

我是Matthew Inman的漫画的忠实粉丝。他们的漫画极度有趣得同时发人深省。
然而,我厌倦了点击下一页并读每一页漫画。此外,人工下载他们是很困难的,因为每一份漫画都被分成了许多张图片。
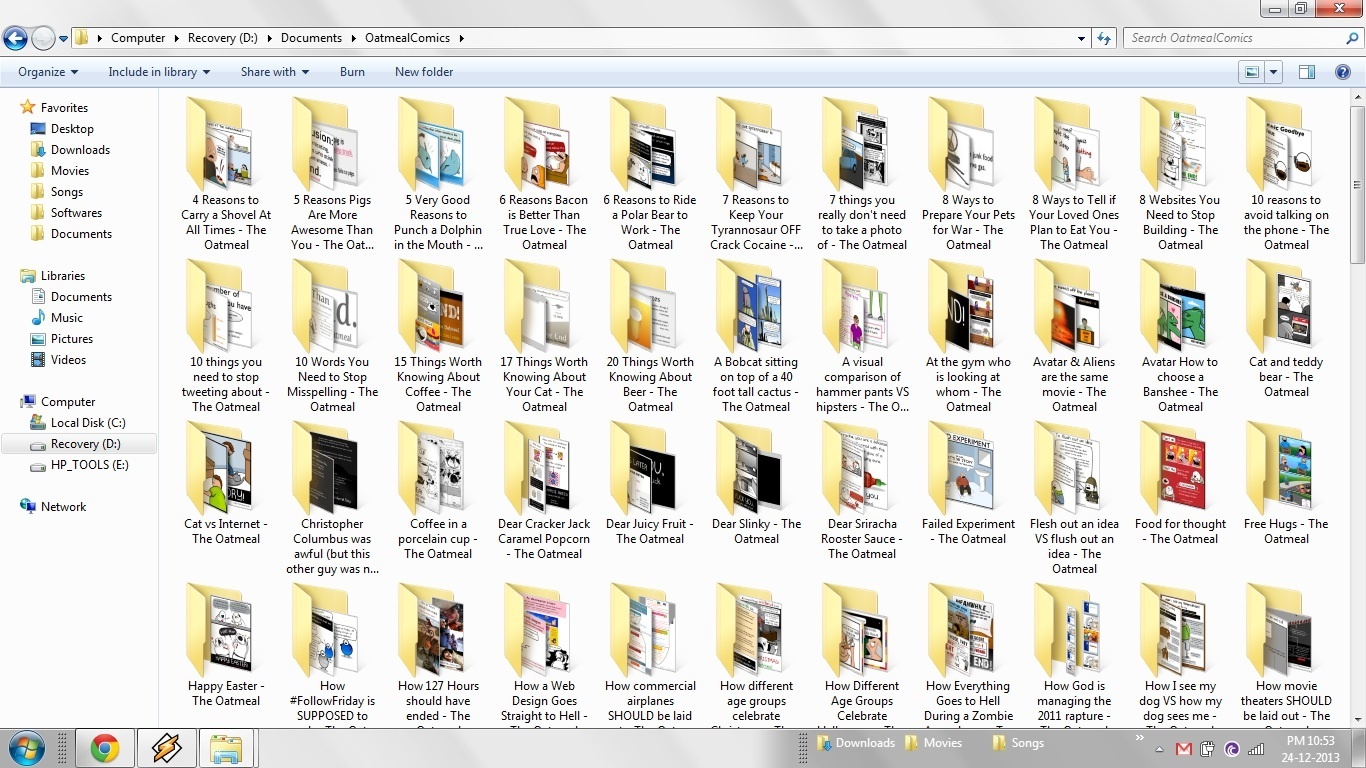
所以我写了一个Python脚本从这个网站上下载所有漫画。这个脚本使用BeautifulSoup (http://www.crummy.com/software/B… )去解析HTML数据,因此你在尝试运行这个脚本之前需要确认你已经安装了BeautifulSoup。
oatmeal下载器的源代码在GitHub上:theoatmeal.com-downloader
这是下载完后文件夹的样子:D
4、someecards.com下载器
在我成功从http://www.theoatmeal.com下载下漫画后,我想知道我是否能在另一个我最喜欢网站——十分滑稽、独一无二http://www.someecards.com上做相同的事情并且下载一些东西。

someecards的问题在于网站的图片是随机命名的,它们的排列没有特定的顺序,每个分类下面都有大量的照片。并且网站里有52个这样的分类。
我意识到由于网站里有大量数据需要解析并下载,因此如果我的脚本是多线程的的话那就再好不过了。于是我在每一个分类下的每一页分配了一个线程。
脚本从网站的每一个分类下下载下来了所有滑稽的电子卡片。每一个分类被放在单独的一个文件夹。
现在我拥有了这个星球上最有趣的电子卡片作为我的私人收藏。
这是当下载完成后文件夹的样子。
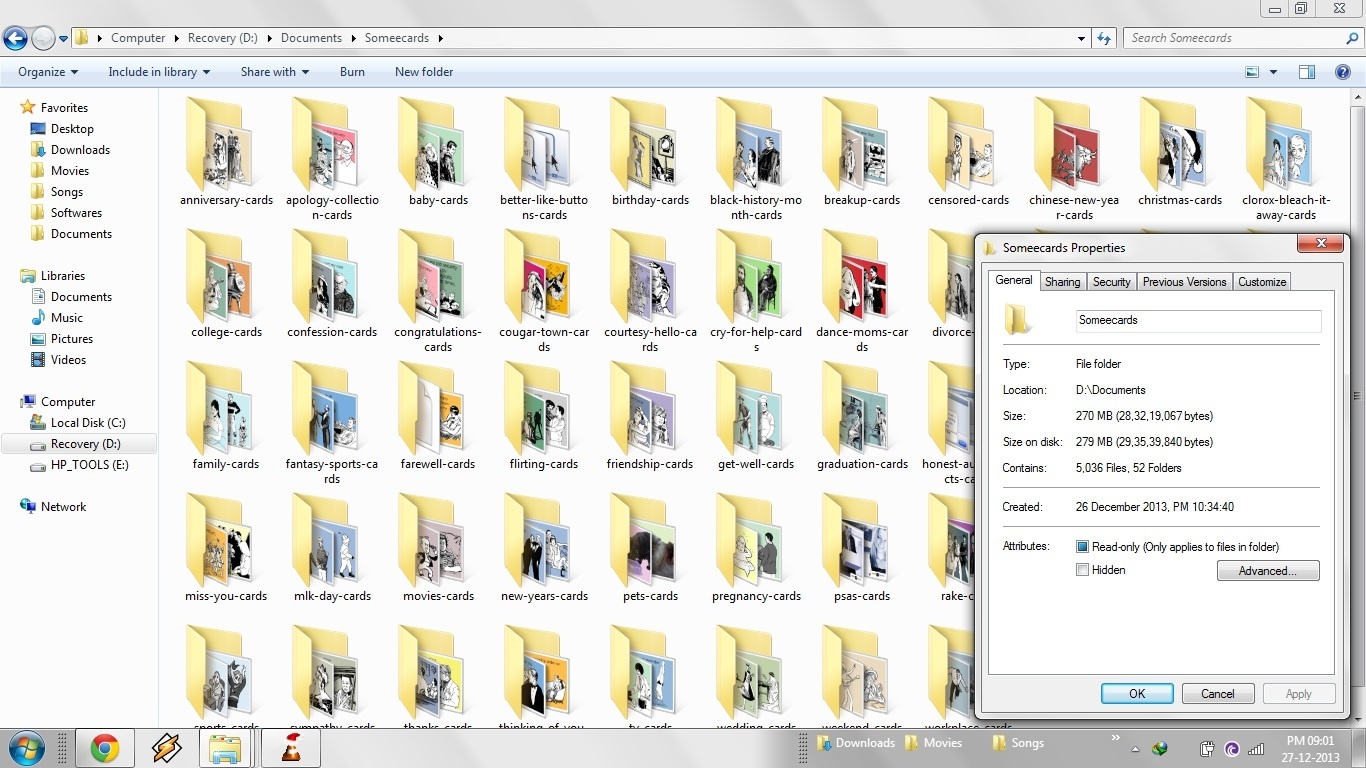
OK。我的私人收藏里有52种类型,5036张电子卡片。
源代码在这里:someecards.com-downloader
编辑:很多人问我我是否可以提供我下载的所有文件。因为我的网络非常不稳定,所以我不能把文件上载到一个网络硬盘,但是我已经上传了相同文件的种子,你可以在这里下载它:somecards.com Site Rip torrent。
播种并扩散爱!:)
如果你运行脚本时遇到麻烦请在这里评论或者发信息给我。我一向乐于助人。
Python王道\m/
相关内容
- Python中何时使用断言,Python使用断言,未经许可,禁止转
- Python 代码性能优化技巧,python性能优化技巧,如何进行
- 写给已有编程经验的 Python 初学者的总结,写给python,未
- Python 2.7.x 和 3.x 版本的重要区别,python2.7.x,未经许可,
- 理解 Python 字节码,理解python字节码,未经许可,禁止转
- 通过示例学习Python列表推导,示例python推导,未经许可,
- Python中setup.py一些不为人知的技巧,pythonsetup.py,未经许
- 在Python中正确使用Unicode,python使用unicode,未经许可,禁
- Python自然语言处理,,未经许可,禁止转载!英文
- Python中的并发编程,Python并发编程,未经许可,禁止转载
评论关闭