python3网页爬虫字节流编码问题,python3爬虫,正在做网页爬虫,得到许多
python3网页爬虫字节流编码问题,python3爬虫,正在做网页爬虫,得到许多
正在做网页爬虫,得到许多注入下列变量code的字符,想尝试将他们转换为utf-8的string输出到文件里,转换不成功,问题如下。
#Python 3.4.0#coding:utf-8import oscode = '\xe8\xb1\x86\xe7\x93\xa3'bytes = code.encode(encoding='utf-8')douban = str(bytes.decode('utf-8'))#print(str(bytes.decode('utf-8')))file_object = open('test.txt', 'w')file_object.write(douban)file_object.close()lz爬的是豆瓣吗?豆瓣用的就是utf-8
<meta charset="UTF-8">
我原来也爬过,豆瓣用的是UTF-8 根本也不用转啊
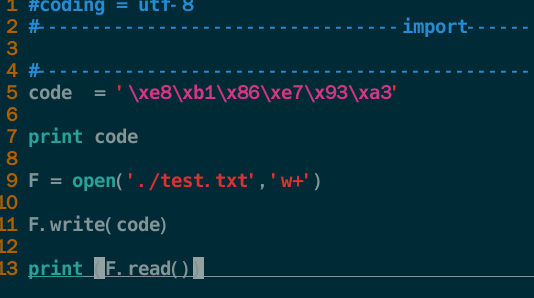

本人用的2.7
已经是utf-8了编码一次又解码一次做了跟没做有什么区别?
#coding:utf-8import oscode = b'\xe8\xb1\x86\xe7\x93\xa3'code = code.decode('utf-8')file_object = open('test.txt', 'w', encoding="utf-8")file_object.write(code)file_object.close()首先,我觉得你需要认识这么几个概念:
1. unicode:在本文中表示用4byte表示的unicode编码,也是python内部使用的字符串编码方式。
2. utf-8:在本文中只最少1byte表示的unicode编码方式。
其次,你需要知道decode和encode之间的关系。
可以看出,在python中,所有格式的中间编码方式就是unicode,需要从编码A转换为编码B,只需要string.decode("A").encode("B")就可以了。
有了上面的知识储备再回到你的问题。
你的code = '\xe8\xb1\x86\xe7\x93\xa3'根据我的经验看起来就是utf-8的编码方式(因为我看到的utf-8编码都是\xFF这种样式,但是我不确定这两者之间的绝对关系),所以这块应该使用u_code = code.decode("utf-8")来使得code解码为unicode,再将其编码为你需要的编码方式(例如gb18030)。
而,你的需求中写到,你希望写入文件的是utf-8的编码格式,所以你可以直接file_object.write(code)。这样你文件中的内容就是utf-8编码的。
如果你拿到一个字符串,你不知道他的编码方式,可以试试chardet,他会给出字符串的编码格式,和信赖度。可以作为你的参考。
文中有任何问题请联系我,欢迎指出问题。
编橙之家文章,
相关内容
- Python抓取数据显示正常,mysql入库后就乱码什么原因,
- 亿图 图示与Visio画一个流程图哪个更实用,图示visio画
- Python类型转换与python版本有关系吗?,python类型,num1 =
- python跨进程的数据结构有哪几种?类似set,pythonset,Pyth
- Python多线程学习哪本书最适合新手请推荐,python多线程
- django安装成功却还提示No module named django.core.management什
- Python 腾讯微信服务器xml数据包发送方式思路,pythonxm
- python处理xml文件,json格式化数据获取内容操作,pythonj
- py3+django rest framework+diango+mysql源码推荐?,py3django,最近
- Python post请求获取json数据方法是什么,pythonjson,用 Pyt
评论关闭