python与redis,pythonredis,1.什么是redis
python与redis,pythonredis,1.什么是redis
1.什么是redis
Redis 是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Python,Ruby,Erlang,PHP客户端,使用很方便。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
2、redis安装
windows-reidis服务端安装包下载:https://github.com/dmajkic/redis/downloads
python客户端使用redis安装:pip3 install redis
3、redis链接与连接池
redis连接
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
1 import redis,time2 #连接redis3 r=redis.Redis(host=‘127.0.0.1‘,port=6379,db=1)4 r.set(‘foo‘,‘bar,你好‘)5 x=r.get(‘foo‘) #得到bytes值6 print(str(x,encoding=‘utf-8‘))#转为字符串7 print(x)
结果:
bar,你好
b‘bar,\xe4\xbd\xa0\xe5\xa5\xbd‘
redis连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
1 pool=redis.ConnectionPool(host=‘127.0.0.1‘,port=6379,db=1,max_connections=10)2 r=redis.Redis(connection_pool=pool)3 r.set(‘foo‘,‘bar2,你好‘)4 x=r.get(‘foo‘) #得到bytes值5 print(str(x,encoding=‘utf-8‘))#转为字符串6 print(x)
结果:
bar2,你好
b‘bar2,\xe4\xbd\xa0\xe5\xa5\xbd‘
3-1 redis string操作api(字符串操作)
String操作,redis中的String在在内存中按照一个name对应一个value来存储
先连接:
1 r=redis.Redis(host=‘127.0.0.1‘,port=6379,db=1)
1 # set(name, value, ex=None, px=None, nx=False, xx=False) 2 # 在Redis中设置值,默认,不存在则创建,存在则修改 3 # 参数: 4 # ex,过期时间(秒) 5 # px,过期时间(毫秒) 6 # nx,如果设置为True,则只有name不存在时,当前set操作才执行 7 # xx,如果设置为True,则只有name存在时,岗前set操作才执行 8 r.set(‘name1‘,‘张三‘,ex=10,nx=True) 9 x=r.get(‘name1‘)10 print(str(x,encoding=‘utf-8‘))
结果:张三
1 # setnx(name, value)2 # 设置值,只有name不存在时,执行设置操作(添加)3 r.set(‘name1‘,‘张三‘,ex=5)4 r.setnx(‘name1‘,‘李四‘) #name1存在,不执行,name1中值仍然是‘张三’5 r.setnx(‘name2‘,‘王谷‘) #name2不存在,执行,name1中值是‘王谷’6 x=r.get(‘name1‘)7 x1=r.get(‘name2‘)8 print(str(x,encoding=‘utf-8‘))9 print(str(x1,encoding=‘utf-8‘))
结果:
张三
王谷
1 # setex(name, value, time)2 # 设置值,可设置过期时间3 # 参数:4 # time,过期时间(数字秒 或 timedelta对象)56 r.setex(‘name1‘,‘李四‘,2) 7 time.sleep(3)8 x=r.get(‘name1‘)9 print(str(x,encoding=‘utf-8‘))
结果:过期了
Traceback (most recent call last):
File "D:/learnpython/s16day11-1/redis/2.redis-string操作.py", line 33, in <module>
print(str(x,encoding=‘utf-8‘))
TypeError: decoding to str: need a bytes-like object, NoneType found
1 # psetex(name, time_ms, value)2 # 设置值3 # 参数:4 # time_ms,过期时间(数字毫秒 或 timedelta对象)5 r.set(‘name1‘,‘张三‘)6 r.psetex(‘name1‘,3,‘李四‘)7 time.sleep(0.001)8 x=r.get(‘name1‘)9 print(str(x,encoding=‘utf-8‘))
结果:李四
1 # mset(*args, **kwargs) 2 # 3 # 批量设置值 4 # 如: 5 # mset(k1=‘v1‘, k2=‘v2‘) 6 # 或 7 # mget({‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘}) 8 9 # get(name)10 # 获取值11 12 # mget(keys, *args)13 #14 # 批量获取15 # 如:16 # mget(‘ylr‘, ‘Lily‘)17 # 或18 # r.mget([‘ylr‘, ‘Lily‘])19 20 r.mset(name1=‘李四‘,name2=‘张三‘)21 r.mset({‘name3‘:‘Lucy‘,‘name4‘:‘Lily‘})22 x=r.get(‘name3‘)23 x1=r.mget(‘name3‘,‘name2‘)24 print(x,x1)25 print(str(x1[0],encoding=‘utf-8‘),str(x1[1],encoding=‘utf-8‘))结果
b‘Lucy‘ [b‘Lucy‘, b‘\xe5\xbc\xa0\xe4\xb8\x89‘]
Lucy 张三
1 # getset(name, value)2 #3 # 设置新值并获取原来的值4 r.set(‘name1‘,‘Lucy‘)5 x=r.getset(‘name1‘,‘lily‘) #获取原来的值6 y=r.get(‘name1‘)#获取新值7 print(x)8 print(y)
结果
b‘Lucy‘
b‘lily‘
1 # getrange(key, start, end) 2 3 # 获取子序列(根据字节获取,非字符) 4 # 参数: 5 # name,Redis 的 name 6 # start,起始位置(字节) 7 # end,结束位置(字节) 8 # 如: "张三" ,0-3表示 "张" 9 r.set(‘name1‘,‘张三‘)10 r.set(‘name2‘,‘Lucy‘)11 x=r.getrange(‘name1‘,0,2)12 y=r.getrange(‘name2‘,0,2)13 print(x,y)14 print(str(x,encoding=‘utf-8‘))
结果
b‘\xe5\xbc\xa0‘ b‘Luc‘
张
1 # setrange(name, offset, value) 2 # 3 # # 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加) 4 # # 参数: 5 # # offset,字符串的索引,字节(一个汉字三个字节) 6 # # value,要设置的值 7 8 r.set(‘name1‘,‘张三‘) 9 r.set(‘name2‘,‘Lucy‘)10 r.setrange(‘name1‘,3,‘兔斯基‘)11 r.setrange(‘name2‘,1,‘hello‘)12 13 x=r.get(‘name1‘)14 y=r.get(‘name2‘)15 16 print(str(x,encoding=‘utf-8‘))17 print(x,y)
结果:
张兔斯基
b‘\xe5\xbc\xa0\xe5\x85\x94\xe6\x96\xaf\xe5\x9f\xba‘ b‘Lhello‘


1 # setbit(name, offset, value) 2 # 对name对应值的二进制表示的位进行操作 3 # 参数: 4 # name,redis的name 5 # offset,位的索引(将值变换成二进制后再进行索引) 6 # value,值只能是 1 或 0 7 8 # 注:如果在Redis中有一个对应: n1 = "foo", 9 # 那么字符串foo的二进制表示为:0110011010 # 0110111111 # 0110111112 # 所以,如果执行13 # setbit(‘n1‘, 7, 1),则就会将第7位设置为1,14 # 那么最终二进制则变成15 # 0110011116 # 0110111117 # 01101111,即:"goo"18 19 # 扩展,转换二进制表示:20 source = "张三"21 # source = "foo"22 23 for i in source:24 num = ord(i)25 print(bin(num).replace(‘b‘, ‘‘))26 # 结果:27 # 010111110010000028 # 010011100000100129 30 # 特别的,如果source是汉字31 # 怎么办?32 # 答:对于utf - 8,每一个汉字占3个字节,那么"张三"则有6个字节33 # 对于汉字,for循环时候会按照字节迭代,那么在迭代时,将每一个字节转换十进制数,然后再将十进制数转换成二进制34 35 # getbit(name, offset)36 37 # 获取name对应的值的二进制表示中的某位的值 (0或1)38 # bitcount(key, start=None, end=None)39 40 # 获取name对应的值的二进制表示中 1 的个数41 # 参数:42 # key,Redis的name43 # start,位起始位置44 # end,位结束位置45 46 47 # bitop(operation, dest, *keys)48 # 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值49 # 参数:50 # operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)51 # dest, 新的Redis的name52 # *keys,要查找的Redis的name53 54 # 如:55 # bitop("AND", ‘new_name‘, ‘n1‘, ‘n2‘, ‘n3‘)56 # 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name以下可不看,二进制操作1 # strlen(name)2 # 返回name对应值的字节长度(一个汉字3个字节)3 r.mset(name1=‘李四‘,name2=‘张三‘)4 x=r.strlen(‘name1‘)5 print(x)
结果:
6
1 # incr(self, name, amount=1)2 # 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。3 # 参数:4 # name,Redis的name5 # amount,自增数(必须是整数)6 # 注:同incrby7 r.incr(‘x1‘,2)8 x=r.get(‘x1‘)9 print(x)
结果:每执行一次代码,自增一次
执行第一次时
b‘2‘
执行第二次:
b‘4‘
1 # incrbyfloat(self, name, amount=1.0)2 # 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。3 4 # 参数:5 # name,Redis的name6 # amount,自增数(浮点型)7 r.incrbyfloat(‘x1‘,1.1)8 x=r.get(‘x1‘)9 print(x)
结果:每执行一次代码,自增一次
执行第一次时
b‘1.1‘
执行第二次:
b‘2.2‘
1 # decr(self, name, amount=1) 2 # 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 3 4 # 参数: 5 # name,Redis的name 6 # amount,自减数(整数) 7 8 r.decr(‘x1‘,1) 9 x=r.get(‘x1‘)10 print(x)
结果:每执行一次代码,自减一次
执行第一次时
b‘1‘
执行第二次:
b‘0‘
1 # append(key, value)2 # 在redis name对应的值后面追加内容3 # 参数:4 # key, redis的name5 # value, 要追加的字符串6 r.set(‘x1‘,‘Hello‘)7 r.append(‘x1‘,‘,Lily‘)8 x=r.get(‘x1‘)9 print(x)
结果:
b‘Hello,Lily‘
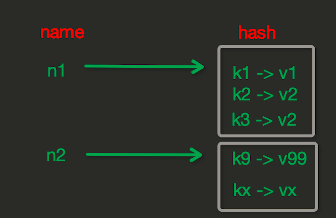
3-2 redisHash操作(哈希操作),redis中Hash在内存中的存储格式如下图:
1 # hset(name, key, value) 2 # name对应的hash中设置一个键值对(不存在,则创建;否则,修改) 3 # 参数: 4 # name,redis的name 5 # key,name对应的hash中的key 6 # value,name对应的hash中的value 8 # 注: 9 # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)10 11 # hget(name,key)12 # 在name对应的hash中获取根据key获取value13 r.hset(‘score‘,‘数学‘,‘90‘)14 x=r.hget(‘score‘,‘数学‘)15 print(x)
结果:
b‘90‘
# hmset(name, mapping)# 在name对应的hash中批量设置键值对# hmget(name, keys, *args)# 在name对应的hash中获取多个key的值# 参数:# name,redis的name# mapping,字典,如:{‘k1‘:‘v1‘, ‘k2‘: ‘v2‘}# keys,要获取key集合,如:[‘k1‘, ‘k2‘, ‘k3‘]# *args,要获取的key,如:k1,k2,k3r.hmset(‘score‘,{‘数学‘:60, ‘语文‘:99, ‘英语‘:100})x=r.hmget(‘score‘,[‘数学‘,‘语文‘])print(x)结果:
[b‘60‘, b‘99‘]
1 r.hmset(‘score‘,{‘数学‘:60, ‘语文‘:99, ‘英语‘:100}) 2 x=r.hmget(‘score‘,[‘数学‘,‘语文‘]) 3 print(x) 4 5 # hgetall(name) 6 # 获取name对应hash的所有键值 7 hgetall=r.hgetall(‘score‘) 8 print("r.hgetall(‘score‘):",hgetall) 9 10 # hlen(name)11 # 获取name对应的hash中键值对的个数12 hlen=r.hlen(‘score‘)13 print("r.hlen(‘score‘):",hlen)14 15 # hkeys(name)16 # 获取name对应的hash中所有的key的值17 hkeys=r.hkeys(‘score‘)18 print("r.hkeys(‘score‘):",hkeys)19 20 # hvals(name)21 # 获取name对应的hash中所有的value的值22 hvals=r.hvals(‘score‘)23 print("r.hvals(‘score‘):",hvals)24 25 # hexists(name, key)26 # 检查name对应的hash是否存在当前传入的key27 hexists=r.hexists(‘score‘,‘数学‘)28 print("r.hexists(‘score‘,‘数学‘):",hexists)29 30 # hdel(name,*keys)31 # 将name对应的hash中指定key的键值对删除32 #注意: *keys 用[k1,k2....]不生效,必须写成k1,k2...33 r.hdel(‘score‘,‘数学‘,‘英语‘)34 hdel=r.hmget(‘score‘,[‘数学‘,‘英语‘,‘语文‘])35 print(hdel)结果:
[b‘60‘, b‘99‘]
r.hgetall(‘score‘): {b‘\xe8\xaf\xad\xe6\x96\x87‘: b‘99‘, b‘\xe6\x95\xb0\xe5\xad\xa6‘: b‘60‘, b‘\xe8\x8b\xb1\xe8\xaf\xad‘: b‘100‘}
r.hlen(‘score‘): 3
r.hkeys(‘score‘): [b‘\xe8\xaf\xad\xe6\x96\x87‘, b‘\xe6\x95\xb0\xe5\xad\xa6‘, b‘\xe8\x8b\xb1\xe8\xaf\xad‘]
r.hvals(‘score‘): [b‘99‘, b‘60‘, b‘100‘]
r.hexists(‘score‘,‘数学‘): True
[None, None, b‘99‘]
1 # hincrby(name, key, amount=1) 2 # 自增name对应的hash中的指定key的值,不存在则创建key=amount 3 # 参数: 4 # name,redis中的name 5 # key, hash对应的key 6 # amount,自增数(整数) 7 r.hincrby(‘当前值‘,‘num1‘,1) 8 num1=r.hget(‘当前值‘,‘num1‘) 9 print(num1)10 # hincrbyfloat(name, key, amount=1.0)11 # 自增name对应的hash中的指定key的值,不存在则创建key=amount12 # 参数:13 # name,redis中的name14 # key, hash对应的key15 # amount,自增数(浮点数)16 r.hincrbyfloat(‘当前值‘,‘num2‘,0.1)17 num2=r.hget(‘当前值‘,‘num2‘)18 print(num2)
结果:
执行第一次:
b‘1‘
b‘0.1‘
执行第二次:
b‘2‘
b‘0.2‘
1 # hscan(name, cursor=0, match=None, count=None) 2 # 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 3 # 参数: 4 # name,redis的name 5 # cursor,游标(基于游标分批取获取数据) 6 # match,匹配指定key,默认None 表示所有的key 7 # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 8 9 # 如:10 # 第一次:cursor1, data1 = r.hscan(‘xx‘, cursor=0, match=None, count=None)11 # 第二次:cursor2, data1 = r.hscan(‘xx‘, cursor=cursor1, match=None, count=None)12 # ...13 # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕14 15 r.hmset(‘XXX‘,{‘k1‘:1, ‘k2‘:2, ‘k3‘:3,‘xx‘:12345})16 cursor1,data1=r.hscan(‘XXX‘,cursor=0,match=‘k*‘,count=1)17 cursor2,data2=r.hscan(‘XXX‘,cursor=cursor1,match=‘k*‘,count=1)18 print(cursor1,data1)19 print(cursor2,data2)20 21 # hscan_iter(name, match=None, count=None)22 # 利用yield封装hscan创建生成器,实现分批去redis中获取数据23 24 # 参数:25 # match,匹配指定key,默认None 表示所有的key26 # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数27 28 # 如:29 # for item in r.hscan_iter(‘xx‘):30 # print item31 32 r.hmset(‘XXX‘,{‘k1‘:1,‘x1‘:‘x1‘, ‘k2‘:2, ‘k3‘:3,‘x2‘:‘x2‘})33 for item in r.hscan_iter(‘XXX‘,match=‘k*‘,count=2):34 print(item)结果:
0 {b‘k1‘: b‘1‘, b‘k2‘: b‘2‘, b‘k3‘: b‘3‘}
0 {b‘k1‘: b‘1‘, b‘k2‘: b‘2‘, b‘k3‘: b‘3‘}
(b‘k1‘, b‘1‘)
(b‘k2‘, b‘2‘)
(b‘k3‘, b‘3‘)
3-3 redis操作List(列表操作)
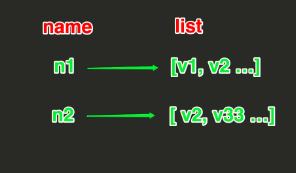
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
增操作
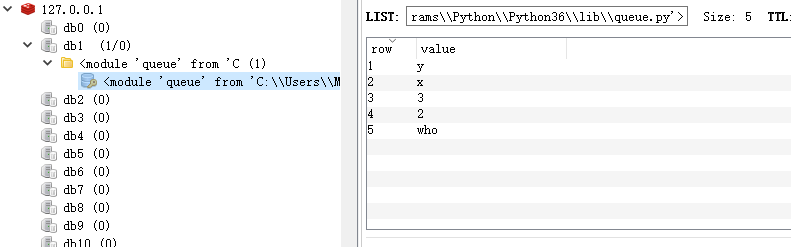
1 import redis 2 3 r=redis.Redis(host=‘127.0.0.1‘,port=6379,db=1) 4 ###############################增############################### 5 6 # lpush(name,values) 7 # 在name对应的list中添加元素-多个,每个新的元素都添加到列表的最左边 8 9 # 扩展:10 # rpush(name, values) 表示从右向左操作11 r.lpush(queue,1,2,3)12 13 # lpushx(name, value)14 # 在name对应的list中添加元素-单个,只有name已经存在时,值添加到列表的最左边15 # 更多:16 # rpushx(name, value) 表示从右向左操作17 r.lpush(queue,"x")18 19 # linsert(name, where, refvalue, value))20 # 在name对应的列表的某一个值前或后插入一个新值21 # 参数:22 # name,redis的name23 # where,BEFORE或AFTER24 # refvalue,标杆值,即:在它前后插入数据25 # value,要插入的数据26 r.linsert(queue,‘BEFORE‘,‘x‘,‘y‘) #在queue列表中‘x’值前插入‘y’27 28 # r.lset(name, index, value)29 # 对name对应的list中的某一个索引位置重新赋值30 31 # 参数:32 # name,redis的name33 # index,list的索引位置34 # value,要设置的值35 r.lset(queue,-1,‘who‘) #给queue的最后一个值重新赋值为‘who’36 37 38 39 # llen(name)40 # name对应的list元素的个数41 x=r.llen(queue)42 print(x)
结果:
5
redis中显示
删操作
1 ###############################删############################### 2 #先在列表中插入一些数据 3 r.lpush(‘list1‘,1,1,2,3,4,5) 4 r.lpush(‘list2‘,1,1,2,3,4,5) 5 print(‘list1的长度为:%s,list2的长度为:%s,‘ %(r.llen(‘list1‘), r.llen(‘list2‘))) 6 # r.lrem(name, value, num) 7 # 在name对应的list中删除指定的值 8 # 参数: 9 # name,redis的name10 # value,要删除的值11 # num, num=0,删除列表中所有的指定值;12 # num=2,从前到后,删除2个;13 # num=-2,从后向前,删除2个14 r.lrem(‘list1‘,1,0) #删除list中所有的值=1的数据15 16 # lpop(name)17 # 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素18 # 更多:19 # rpop(name) 表示从右向左操作20 r.lpop(‘list1‘) #删除左侧第一个元素21 22 23 # ltrim(name, start, end)24 # 在name对应的列表中移除没有在start-end索引之间的值25 # 参数:26 # name,redis的name27 # start,索引的起始位置28 # end,索引结束位置29 r.ltrim(‘list1‘,0,1) #删除list中索引值不在0-1之间的数据30 31 # blpop(keys, timeout)32 # 将多个列表排列,按照从左到右去pop对应列表的元素33 # 参数:34 # keys,redis的name的集合35 # timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞36 # 更多:37 # r.brpop(keys, timeout),从右向左获取数38 for i in range(5):39 r.blpop((‘list1‘,‘list2‘),1) #循环删除列表‘list1’的数据,如果‘list1’中所有的值都被删除了,则开始删除列表‘list2’中的数据,直到循环结束40 41 #打印列表的长度42 print(‘list1的长度为:%s,list2的长度为:%s,‘ %(r.llen(‘list1‘), r.llen(‘list2‘)))
结果:
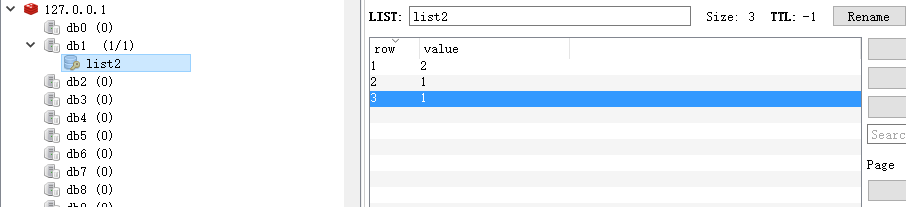
list1的长度为:6,list2的长度为:6,
list1的长度为:0,list2的长度为:3,
redis结果:
其它操作
1 ############################其他########################### 2 strList=r.rpush(‘strlist‘,‘a‘,‘b‘,‘c‘) 3 numList=r.rpush(‘numlist‘,1,2,3) 4 # lrange(name, start, end) 5 # 在name对应的列表分片获取数据 6 # 参数: 7 # name,redis的name 8 # start,索引的起始位置 9 # end,索引结束位置10 str=r.lrange(‘strlist‘,0,1) #获取strlist 中0~1间的值11 print(str)12 13 # rpoplpush(src, dst)14 # 从一个列表移除最右边的元素,同时将其添加至另一个列表的最左边15 # 参数:16 # src,要取数据的列表的name17 # dst,要添加数据的列表的name18 r.rpoplpush(‘strlist‘,‘numlist‘) #从strlist取出最右边的元素,添加到numlist的左边19 20 21 # brpoplpush(src, dst, timeout=0)22 # 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧23 24 # 参数:25 # src,取出并要移除元素的列表对应的name26 # dst,要插入元素的列表对应的name27 # timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞28 r.brpoplpush(‘strlist‘,‘numlist‘,0)##与rpoplpush不同的是,有超时时间
结果:
[b‘a‘, b‘b‘]
redis结果:

3-4、redis set操作api(集合操作)
1 # Set操作,Set集合就是不允许重复的列表 2 3 import redis 4 5 r=redis.Redis(host=‘127.0.0.1‘,port=6379,db=1) 6 7 # sadd(name,values) 8 # name对应的集合中添加元素 9 r.sadd(‘set1‘,1,2,3,‘汉字‘)10 r.sadd(‘set2‘,1,‘a‘,‘b‘)11 # scard(name)12 # 获取name对应的集合中元素个数13 num=r.scard(‘set1‘)14 print(‘set1中元素的个数:%d‘%num)15 16 # sdiff(keys, *args)17 # 在第一个name对应的集合中且不在其他name对应的集合的元素集合18 x1=r.sdiff(‘set1‘,‘set2‘)19 for i in x1:20 print(‘x1:‘+str(i,encoding=‘utf-8‘))21 22 # sdiffstore(dest, keys, *args)23 # 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中24 r.sdiffstore(‘newset‘,‘set1‘,‘set2‘)25 26 # sinter(keys, *args)27 # 获取多个name对应集合的并集28 x2=r.sinter(‘set1‘,‘set2‘)29 for i in x2:30 print(‘x2:‘+str(i,encoding=‘utf-8‘))31 32 # sinterstore(dest, keys, *args)33 # 获取多个name对应集合的并集,再讲其加入到dest对应的集合中34 r.sinterstore(‘newset‘,‘set1‘,‘set2‘)35 36 # sismember(name, value)37 # 检查value是否是name对应的集合的成员38 x5=r.sismember(‘set1‘,1)39 print(x5)40 41 # smembers(name)42 # 获取name对应的集合的所有成员43 x6=r.smembers(‘set1‘)44 for i in x6:45 print(‘x6:‘+str(i,encoding=‘utf-8‘))46 47 # smove(src, dst, value)48 # 将某个成员从一个集合中移动到另外一个集合49 r.smove(‘set1‘,‘set2‘,0)50 51 # spop(name)52 # 从集合的右侧(尾部)移除一个成员,并将其返回53 54 x7=r.spop(‘set1‘)55 print(‘set1中移除的成员是:%s‘ %x7)56 57 # srandmember(name, numbers)58 # 从name对应的集合中随机获取 numbers 个元素59 x8=r.srandmember(‘set1‘,3)60 for i in x8:61 print(‘x8:%s‘,str(i,encoding=‘utf-8‘))62 63 # srem(name, values)64 # 在name对应的集合中删除某些值65 r.srem(‘set1‘,1,2)66 67 # sunion(keys, *args)68 # 获取多一个name对应的集合的并集69 x10=r.sunion(‘set1‘,‘set2‘)70 for i in x10:71 print(‘x10:%s‘,str(i,encoding=‘utf-8‘))72 73 # sunionstore(dest,keys, *args)74 # 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中75 r.sunionstore(‘set3‘,‘set1‘,‘set2‘)76 77 # sscan(name, cursor=0, match=None, count=None)78 # sscan_iter(name, match=None, count=None)79 # 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
结果:
set1中元素的个数:4
x1:汉字
x1:3
x1:2
x2:1
True
x6:汉字
x6:1
x6:3
x6:2
set1中移除的成员是:b‘1‘
x8:%s 汉字
x8:%s 2
x8:%s 3
x10:%s 汉字
x10:%s a
x10:%s 1
x10:%s b
x10:%s 3
3-5 有序set redis api(有序集合操作)
1 import redis 2 # 有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较, 3 # 所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。 4 r=redis.Redis(host=‘127.0.0.1‘,port=6379,db=1) 5 6 # zadd(name, *args, **kwargs) 7 # 在name对应的有序集合中添加元素 8 # 如: 9 # zadd(‘zz‘, ‘n1‘, 1, ‘n2‘, 2) 10 # 或 11 # zadd(‘zz‘, n1=11, n2=22) 12 r.zadd(‘score‘,语文=55,数学=60,英语=70,) 13 r.zadd(‘age‘,黎明=30,张小花=30,高原=30,李丽=30,英语=30) 14 # zcard(name) 15 # 获取name对应的有序集合元素的数量 16 x1=r.zcard(‘score‘) 17 print(‘s1对应集合的元素的数量%d‘ %x1) 18 19 # zcount(name, min, max) 20 # 获取name对应的有序集合中分数 在 [min,max] 之间的个数 21 x2=r.zcount(‘score‘,50,60) 22 print(‘s2对应集合中分数 在 [50,60] 之间的个数:%d‘ %x2) 23 24 # zincrby(name, value, amount) 25 # 为有序集合name的成员value的score加上增量amount 26 r.zincrby(‘score‘,‘语文‘,30) 27 28 29 # r.zrange(name, start, end, desc=False, withscores=False, score_cast_func=float) 30 # 按照索引范围获取name对应的有序集合的元素 31 # 参数: 32 # name,redis的name 33 # start,有序集合索引起始位置(非分数) 34 # end,有序集合索引结束位置(非分数) 35 # desc,排序规则,默认按照分数从小到大排序 36 # withscores,是否获取元素的分数,默认只获取元素的值 37 # score_cast_func,对分数进行数据转换的函数 38 39 # 更多: 40 # 从大到小排序 41 # zrevrange(name, start, end, withscores=False, score_cast_func=float) 42 43 x1=r.zrange(‘score‘,0,2,desc=True,withscores=True,score_cast_func=float) 44 for i in x1: 45 print(x1) 46 47 48 # 按照分数范围获取name对应的有序集合的元素 49 # zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float) 50 51 x2=r.zrangebyscore(‘score‘,60,90,start=0,num=2,withscores=True,score_cast_func=float) 52 for i in x2: 53 print(i) 54 # 从大到小排序 55 # zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float) 56 57 58 # zrank(name, value) 59 # 获取某个值在 name对应的有序集合中的排行(从 0 开始) 60 x3=r.zrank(‘score‘,‘语文‘) 61 print("语文的分数在集合中的排行是:%d" %x3) 62 # 更多: 63 # zrevrank(name, value),从大到小排序 64 65 66 # zrangebylex(name, min, max, start=None, num=None) 67 # 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员 68 # 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大 69 # 参数: 70 # name,redis的name 71 # min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间 72 # min,右区间(值) 73 # start,对结果进行分片处理,索引位置 74 # num,对结果进行分片处理,索引后面的num个元素 75 76 # 如: 77 # ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga 78 # r.zrangebylex(‘myzset‘, "-", "[ca") 结果为:[‘aa‘, ‘ba‘, ‘ca‘] 79 80 # 更多: 81 # 从大到小排序 82 # zrevrangebylex(name, max, min, start=None, num=None) 83 # zrem(name, values) 84 85 86 # 删除name对应的有序集合中值是values的成员 87 # 如:zrem(‘zz‘, [‘s1‘, ‘s2‘]) 88 r.zrem(‘score‘,[‘数学‘]) 89 90 # zremrangebyrank(name, min, max) 91 # 根据排行范围删除 92 r.zremrangebyscore(‘age‘,0,2) 93 94 # zremrangebyscore(name, min, max) 95 # 根据分数范围删除 96 x5=r.zremrangebyscore(‘score‘,30,55) 97 print(‘删除个数是x5=%d‘ %x5) 98 99 # zscore(name, value)100 # 获取name对应有序集合中 value 对应的分数101 x4=r.zscore(‘score‘,‘语文‘)102 print("语文的分数是:%d" %x4)103 104 # zinterstore(dest, keys, aggregate=None)105 # 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作106 # aggregate的值为: SUM MIN MAX107 108 r.zinterstore(‘inter‘,[‘score‘,‘age‘],aggregate=‘SUM‘)#交集保存在集合inter中109 110 # zunionstore(dest, keys, aggregate=None)111 # 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作112 # aggregate的值为: SUM MIN MAX113 r.zunionstore(‘outer‘,[‘score‘,‘age‘],aggregate=‘SUM‘)#交集保存在集合outer中114 115 # zscan(name, cursor=0, match=None, count=None, score_cast_func=float)116 # zscan_iter(name, match=None, count=None, score_cast_func=float)117 # 同redis-hash中的scan操作相似,相较于字符串新增score_cast_func,用来对分数进行操作结果:
s1对应集合的元素的数量3
s2对应集合中分数 在 [50,60] 之间的个数:2
[(b‘\xe8\xaf\xad\xe6\x96\x87‘, 85.0), (b‘\xe8\x8b\xb1\xe8\xaf\xad‘, 70.0), (b‘\xe6\x95\xb0\xe5\xad\xa6‘, 60.0)]
[(b‘\xe8\xaf\xad\xe6\x96\x87‘, 85.0), (b‘\xe8\x8b\xb1\xe8\xaf\xad‘, 70.0), (b‘\xe6\x95\xb0\xe5\xad\xa6‘, 60.0)]
[(b‘\xe8\xaf\xad\xe6\x96\x87‘, 85.0), (b‘\xe8\x8b\xb1\xe8\xaf\xad‘, 70.0), (b‘\xe6\x95\xb0\xe5\xad\xa6‘, 60.0)]
(b‘\xe6\x95\xb0\xe5\xad\xa6‘, 60.0)
(b‘\xe8\x8b\xb1\xe8\xaf\xad‘, 70.0)
语文的分数在集合中的排行是:2
删除个数是x5=0
语文的分数是:85
4、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
管道(pipeline)是redis在提供单个请求中缓冲多条服务器命令的基类子类。通过减少服务器-客户端之间反复的TCP数据库包,从而大大提高了执行批量命令的功能。
默认的情况下,管道里执行的命令可以保证执行的原子性,将transaction设置为False:_pipe = rcon.pipeline(transaction=False)可以禁用这一特性。
1 import redis 2 3 pool = redis.ConnectionPool(host=‘127.0.0.1‘, port=6379,db=1) 4 5 r = redis.Redis(connection_pool=pool) 6 7 #pipe = r.pipeline(transaction=False) 8 pipe = r.pipeline(transaction=True) #默认为True 9 10 pipe.set(‘name‘,‘黎明‘)11 pipe.set(‘age‘, ‘40‘)12 13 pipe.execute()
python与redis
相关内容
- Python3——坦克大战,python3坦克大战,# coding=u
- python-字典练习,python-字典,备注:此次练习使用3
- python_turtlr,,Python tur
- Python实现的字典值比较功能示例,python示例
- python Socket之客户端和服务端握手详解,pythonsocket
- 详谈python http长连接客户端,详谈python
- python3实现TCP协议的简单服务器和客户端案例(分享),
- python3实现UDP协议的服务器和客户端,python3实现udp协议
- python比较两个列表大小的方法,python两个列表大小
- Python实现比较两个文件夹中代码变化的方法,
评论关闭