python接口自动化23-token参数关联登录(登录拉勾网),python23-token,前言登录网站的时候,
python接口自动化23-token参数关联登录(登录拉勾网),python23-token,前言登录网站的时候,
前言
登录网站的时候,经常会遇到传token参数,token关联并不难,难的是找出服务器第一次返回token的值所在的位置,取出来后就可以动态关联了
登录拉勾网
1.先找到登录首页https://passport.lagou.com/login/login.html,输入账号和密码登录,抓包看详情
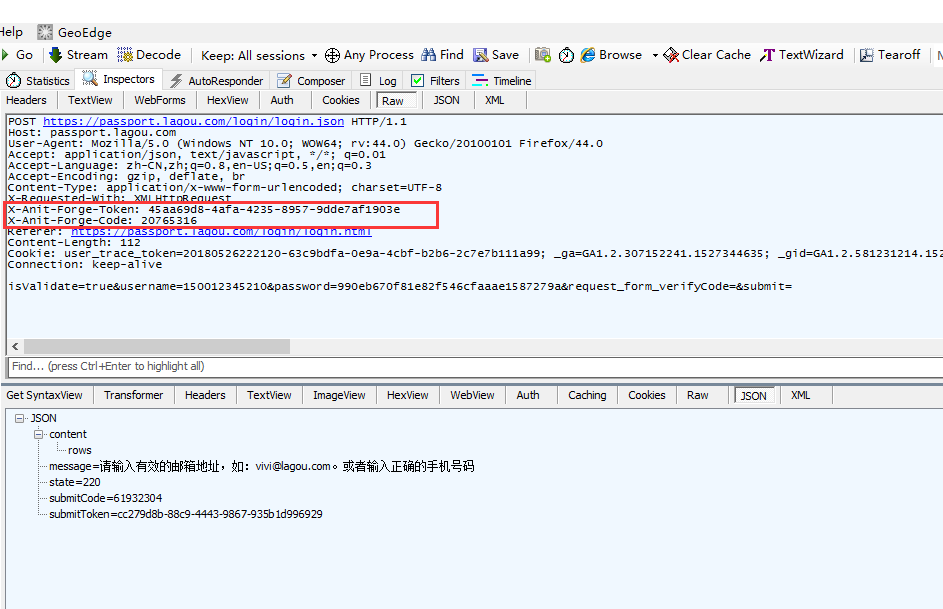
2.再重新登录一次抓包看的时候,头部有两个参数是动态的,token和code值每次都会不一样,只能用一次
X-Anit-Forge-Token: 45aa69d8-4afa-4235-8957-9dde7af1903eX-Anit-Forge-Code: 20765316
找到token生成的位置
1.打开登录首页https://passport.lagou.com/login/login.html,直接按F5刷新(只做刷新动作,不输入账号和密码),然后从返回的页面找到token生成的位置
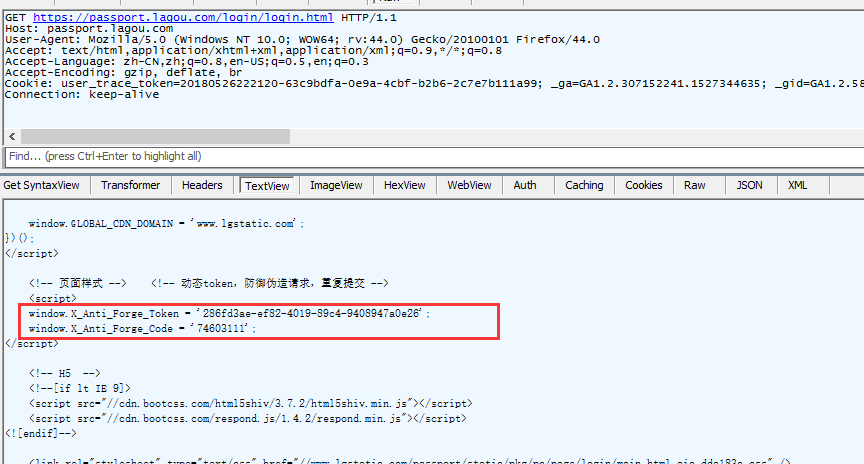
看注释内容:
</script> <!-- 页面样式 --> <!-- 动态token,防御伪造请求,重复提交 --> <script> window.X_Anti_Forge_Token = '286fd3ae-ef82-4019-89c4-9408947a0e26'; window.X_Anti_Forge_Code = '74603111';</script>
前端的代码,注释内容暴露了token位置,嘿嘿!
2.接下来从返回的html里面解析出token和code两个参数的值
# coding:utf-8import requestsimport refrom bs4 import BeautifulSoup# 作者:上海-悠悠 QQ交流群:512200893def getTokenCode(s): ''' 要从登录页面提取token,code, 然后在头信息里面添加 <!-- 页面样式 --><!-- 动态token,防御伪造请求,重复提交 --> <script type="text/javascript"> window.X_Anti_Forge_Token = 'dde4db4a-888e-47ca-8277-0c6da6a8fc19'; window.X_Anti_Forge_Code = '61142241'; </script> ''' url = 'https://passport.lagou.com/login/login.html' h = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0", } # 更新session的headers s.headers.update(h) data = s.get(url, verify=False) soup = BeautifulSoup(data.content, "html.parser", from_encoding='utf-8') tokenCode = {} try: t = soup.find_all('script')[1].get_text() print(t) tokenCode['X_Anti_Forge_Token'] = re.findall(r"Token = '(.+?)'", t)[0] tokenCode['X_Anti_Forge_Code'] = re.findall(r"Code = '(.+?)'", t)[0] except: print("获取token和code失败") tokenCode['X_Anti_Forge_Token'] = "" tokenCode['X_Anti_Forge_Code'] = "" return tokenCode模拟登陆
1.登陆的时候这里密码参数虽然加密了,但是是固定的加密方式,所以直接复制抓包的加密后字符串就行了
# coding:utf-8import requestsimport refrom bs4 import BeautifulSoup# 作者:上海-悠悠 QQ交流群:512200893def login(s, gtoken, user, psw): ''' function:登录拉勾网网站 :param s: 传s = requests.session() :param gtoken: 上一函数getTokenCode返回的tokenCode :param user: 账号 :param psw: 密码 :return: 返回json ''' url2 = 'https://passport.lagou.com/login/login.json' h2 = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "X-Requested-With": "XMLHttpRequest", "X-Anit-Forge-Token": gtoken['X_Anti_Forge_Token'], "X-Anit-Forge-Code": gtoken['X_Anti_Forge_Code'], "Referer": "https://passport.lagou.com/login/login.html", } # 更新s的头部 s.headers.update(h2) body = { "isValidate":'true', "username": user, "password": psw, "request_form_verifyCode": "", "submit": "" } r2 = s.post(url2 , data=body, verify=False) print(r2.text) return r2.json()密码加密
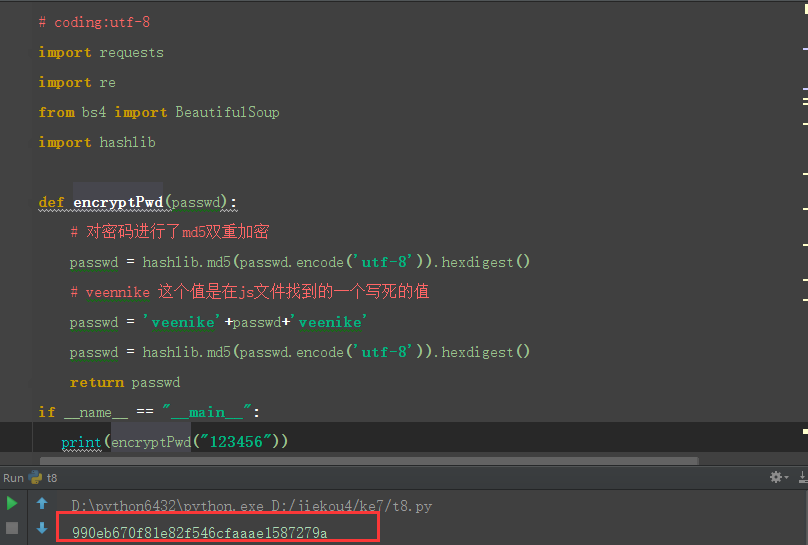
1.这里密码是md5加密的(百度看了其它大神的博客,才知道的)
# coding:utf-8import requestsimport refrom bs4 import BeautifulSoupimport hashlibdef encryptPwd(passwd): # 作者:上海-悠悠 QQ交流群:512200893 # 对密码进行了md5双重加密 passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest() # veennike 这个值是在js文件找到的一个写死的值 passwd = 'veenike'+passwd+'veenike' passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest() return passwdif __name__ == "__main__": # 测试密码123456 print(encryptPwd("123456"))输出结果:
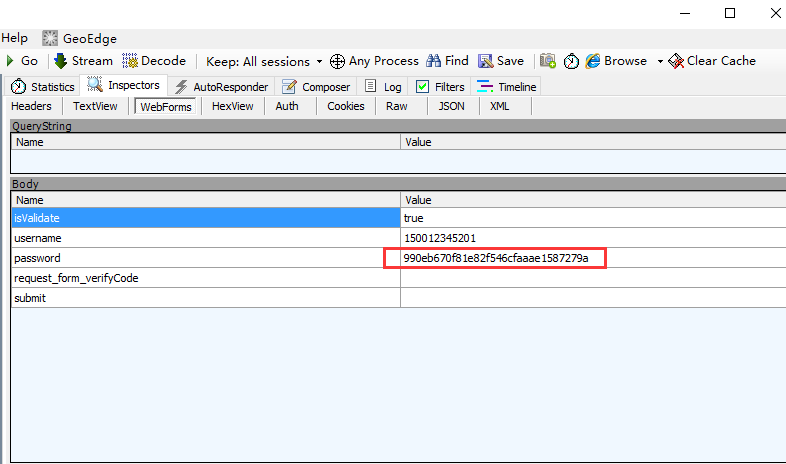
2.跟抓包的数据对比,发现是一样的,说明加密成功
参考代码:
# coding:utf-8import requestsimport refrom bs4 import BeautifulSoupimport urllib3import hashliburllib3.disable_warnings()# 作者:上海-悠悠 QQ交流群:512200893class LoginLgw(): def __init__(self, s): self.s = s def getTokenCode(self): ''' 要从登录页面提取token,code, 然后在头信息里面添加 <!-- 页面样式 --><!-- 动态token,防御伪造请求,重复提交 --> <script type="text/javascript"> window.X_Anti_Forge_Token = 'dde4db4a-888e-47ca-8277-0c6da6a8fc19'; window.X_Anti_Forge_Code = '61142241'; </script> ''' url = 'https://passport.lagou.com/login/login.html' h = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0", } # 更新session的headers self.s.headers.update(h) data = self.s.get(url, verify=False) soup = BeautifulSoup(data.content, "html.parser", from_encoding='utf-8') tokenCode = {} try: t = soup.find_all('script')[1].get_text() print(t) tokenCode['X_Anti_Forge_Token'] = re.findall(r"Token = '(.+?)'", t)[0] tokenCode['X_Anti_Forge_Code'] = re.findall(r"Code = '(.+?)'", t)[0] return tokenCode except: print("获取token和code失败") tokenCode['X_Anti_Forge_Token'] = "" tokenCode['X_Anti_Forge_Code'] = "" return tokenCode def encryptPwd(self,passwd): # 对密码进行了md5双重加密 passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest() # veennike 这个值是在js文件找到的一个写死的值 passwd = 'veenike'+passwd+'veenike' passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest() return passwd def login(self, user, psw): ''' function:登录拉勾网网站 :param user: 账号 :param psw: 密码 :return: 返回json ''' gtoken = self.getTokenCode() print(gtoken) print(gtoken['X_Anti_Forge_Token']) print(gtoken['X_Anti_Forge_Code']) url2 = 'https://passport.lagou.com/login/login.json' h2 = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "X-Requested-With": "XMLHttpRequest", "X-Anit-Forge-Token": gtoken['X_Anti_Forge_Token'], "X-Anit-Forge-Code": gtoken['X_Anti_Forge_Code'], "Referer": "https://passport.lagou.com/login/login.html", } # 更新s的头部 self.s.headers.update(h2) passwd = self.encryptPwd(psw) body = { "isValidate":'true', "username": user, "password": passwd, "request_form_verifyCode": "", "submit": "" } r2 = self.s.post(url2 , data=body, verify=False) try: print(r2.text) return r2.json except: print("登录异常信息:%s" % r2.text) return Noneif __name__ == "__main__": s = requests.session() lgw = LoginLgw(s) lgw.login("15221000000", "123456")python接口自动化23-token参数关联登录(登录拉勾网)
相关内容
- 【Python 数据分析】module ‘numpy‘ has no attribute ‘array‘
- python中文编码&json中文输出问题,,python2.x版
- 用 Python 实现武科大教务处自动抢课,python武科,首先分
- 揭开Python科学计算的面纱,python科学计算面纱,春牛春杖
- 如何用VSCode愉快的写Python,vscodepython, 在学习Pytho
- Python练习_考试第二次,python练习第二次,一. 选择题(3
- Python3-递归函数,python3-递归,什么是递归?递归,就
- python错误异常,python错误,错误错误分为语法错误
- Python-控制流语句,python-流语句,控制流语句在 Pyt
- Python爬虫通过替换http request header来欺骗浏览器实现登录
评论关闭