python爬虫 ----文章爬虫(合理处理字符串中的\n\t\r........),,import url
python爬虫 ----文章爬虫(合理处理字符串中的\n\t\r........),,import url
import urllib.requestimport reimport timenum=input("输入日期(20150101000):")def openpage(url): html=urllib.request.urlopen(url) page=html.read().decode(‘gb2312‘) return pagedef getpassage(page): passage = re.findall(r‘<p class="MsoNormal" align="left">([\s\S]*)</FONT>‘,str(page)) passage1=re.sub("</?\w+[^>]*>", "", str(passage)) passage2=passage1.replace(‘\\r‘, ‘\r‘).replace(‘\\n‘, ‘ \n‘).replace(‘\\t‘,‘\t‘).replace(‘]‘,‘‘).replace(‘[‘,‘‘).replace(‘ ‘,‘ ‘) print(passage2) with open(load,‘a‘,encoding=‘utf-8‘) as f: f.write("-----------------------------"+"日期"+str(date)+"---------------------------------\n"+passage2+"----------------------------------------------------\n")for i in range(1,32): date=int(num)+int(i) print(date) load="C:/Users/home/Desktop/新建文本文档.txt" url=("http://www.hbuas.edu.cn/news/xyxw/news_"+str(date)+".htm")
try: page=openpage(url) getpassage(page) print("第"+str(i)+"号有文章,----已下载") except: print("第"+str(i)+"号无文章。") time.sleep(2)写了一个爬学校新闻网的爬虫,
主要涉及 re正则 urllib.request 文件的写入
在爬取文章时通常会返回很多影响美感的代码
如下:
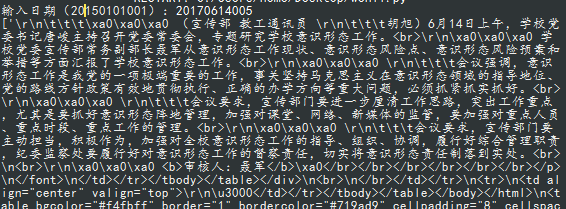
优化:
两次正则
passage = re.findall(r‘<p align="left">([\s\S]*)</FONT>‘,str(page)) #第一次匹配字段 passage1=re.sub("</?\w+[^>]*>", "", str(passage)) # 第二次去掉html标签
替换
passage2=passage1.replace(‘\\r‘, ‘\r‘).replace(‘\\n‘, ‘ \n‘).replace(‘\\t‘,‘\t‘).replace(‘]‘,‘‘).replace(‘[‘,‘‘).replace(‘ ‘,‘ ‘)
效果如下:
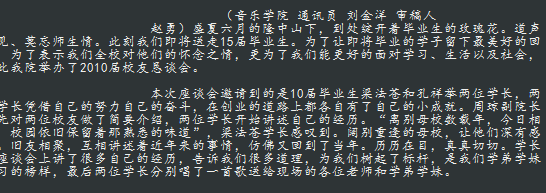
over!
python爬虫 ----文章爬虫(合理处理字符串中的\n\t\r........)
相关内容
- Python-OpenCV —— 基本操作详解,,OpenCV是一个基
- 如何用python 在视频上添加自己的logo,,头条号:https:
- Python3安装geohash,,Geohash是一个
- 用python进行对乒乓球的比赛分析,并且将该程序进行封
- python+selenium常见问题解决方式,pythonselenium,1、启动不了
- Python爬虫教程:爬取付费电影,告别费钱的日子,,今天
- Python小白必备的8个最常用的内置函数,,Python给我们内
- Python—模块-time、random,,import 1、执
- Python之Flak入门,pythonflak,文件名vsearch
- Python 安装第三方库,python第三方库,cmd进入Pytho
评论关闭