Python——爬虫学习1,,爬虫了解一下网络爬虫
Python——爬虫学习1,,爬虫了解一下网络爬虫
爬虫了解一下
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
Python的安装
本篇教程采用Python3 来写,所以你需要给你的电脑装上Python3才行。注意选择正确的版本,一般下载并且安装完成,pip也一起安装好了。
链接:https://pan.baidu.com/s/1xxM09dmiXjTIiqABsIZxTQ 密码:mjqc
安装过程就不在赘言。
python插件的安装
爬虫用到的插件可以通过强大的pip下载(一个用于下载插件的程序),位置在C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\Scripts\pip.exe
用到的插件包括lxml,beautifulsoup4,requests
按住win+r,输入cmd,安装插件的语法为:pip install 插件名称
运行cmd

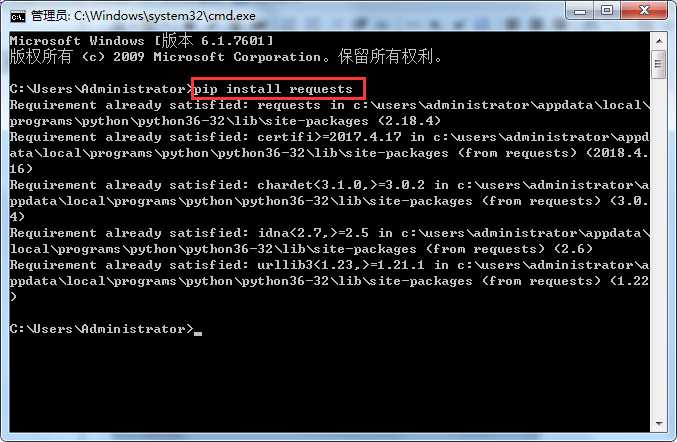
安装requests
输入pip install requests
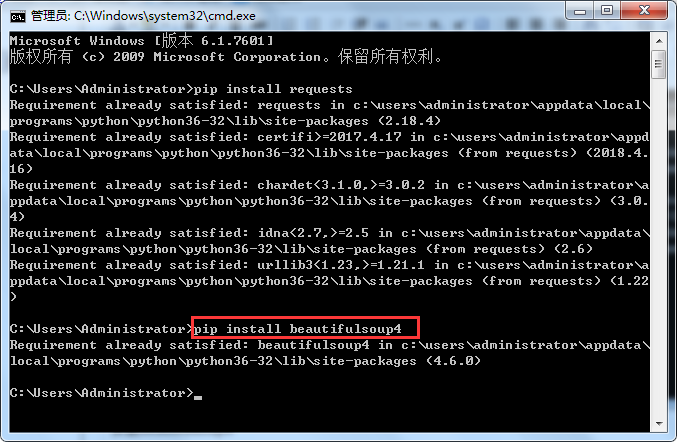
安装beautifulsoup4
输入pip install beautifulsoup4
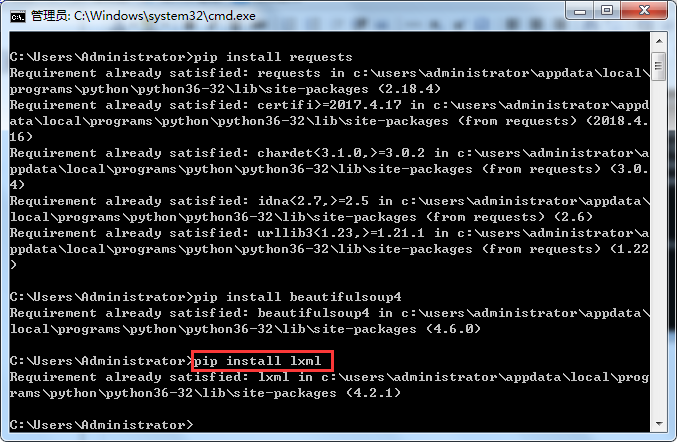
安装lxml
输入pip install lxml
注意:pip安装的插件的位置在C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\Lib\site-packages
正式编程工作
新建一个.py文件,输入代码如下:
#!/usr/bin/env python3#-*- coding:utf-8 -*-import requests #导入requestsfrom bs4 import BeautifulSoup #导入bs4中的BeautifulSoupimport os #导入os#浏览器的请求头(大部分网站没有这个请求头会报错,请务必加上)headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1‘}all_url = ‘http://www.mzitu.com/all‘ #开始的URL地址##使用requests中的get方法来获取all_url的内容 ,headers为上面设置的请求头,请参考requests的文档start_html = requests.get(all_url, headers=headers)##打印出start_html(请注意,打印网页内容请使用text,concent是二进制的数据,一般用于下载图片,视频,音频等多媒体内容时才使用)print(start_html.text)运行一下就会得到网页的内容了,嘻嘻(*^__^*) 嘻嘻

Python——爬虫学习1
评论关闭