Python破解各路反爬措施,强势采集拉勾网数据!,上拉勾
Python破解各路反爬措施,强势采集拉勾网数据!,上拉勾
拉勾网这个网页的反爬机制:
保持cookie与网页来源的说明,如果不加网页的来源会造成一个IP频繁的假象。
为什么说是假象呢?因为当你用浏览器再次访问是哭正常访问的,自行测试即可。
不建议小白阅读此文,不建议不喜欢动手的人阅读此文,因为不做的话,永远不知道事情的真相。
由于网页源代码中并没有我们需要的信息:

那么我们进行抓包测试:
完整视频教程,请进此群。

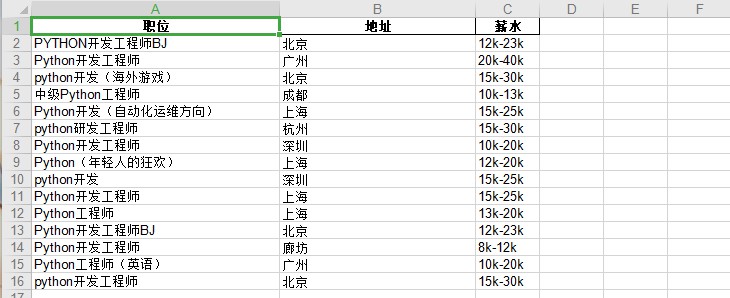
发现此包中的确包含了我们想要的信息。
注意:
这个post请求当中 表单数据first 是不变的,pn代表页码,当然kd代表我们需要查找的关键词。
请求这个url必须带上referer,这个报文代表我们的url来源。还有我们的浏览器来源user-agent用户代理也要添加!

这样请求,你会发现还是无法正常的获取到数据,那么别忘记我前面说的,保持cookie。在此处有人会直接复制cookie报文,但是别忘了cookie是有时效性的,所以怎么办?
最好的办法就是 提前访问此url的来源,从来源中把cookie取下来,添加到这个请求当中。
最好筛选数据即可:
这篇文章我不准备给出源代码,因为我希望还不会的可以自己去做一下。
更多技术文章,请关注公众号:

相关内容
- 暂无相关文章
评论关闭