Python 信息提取-爬虫,爬虫提取数据, import re
Python 信息提取-爬虫,爬虫提取数据, import re

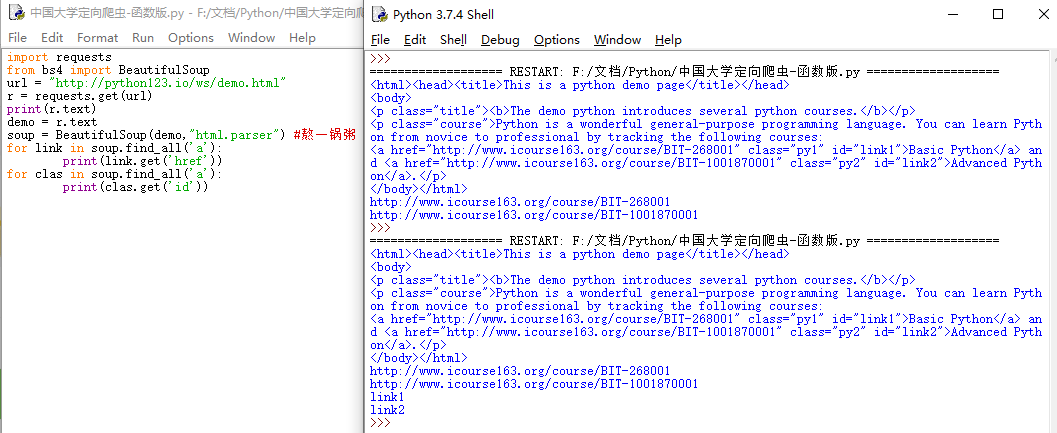

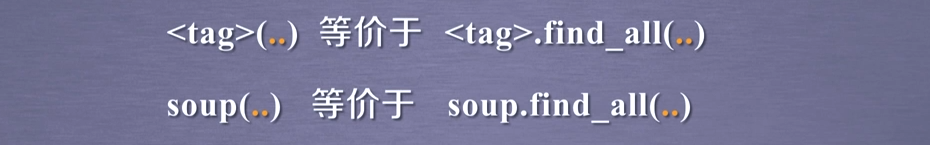
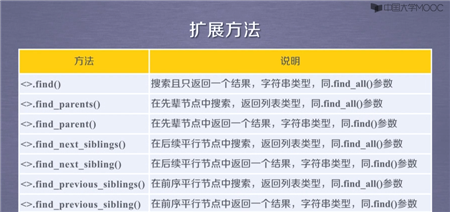
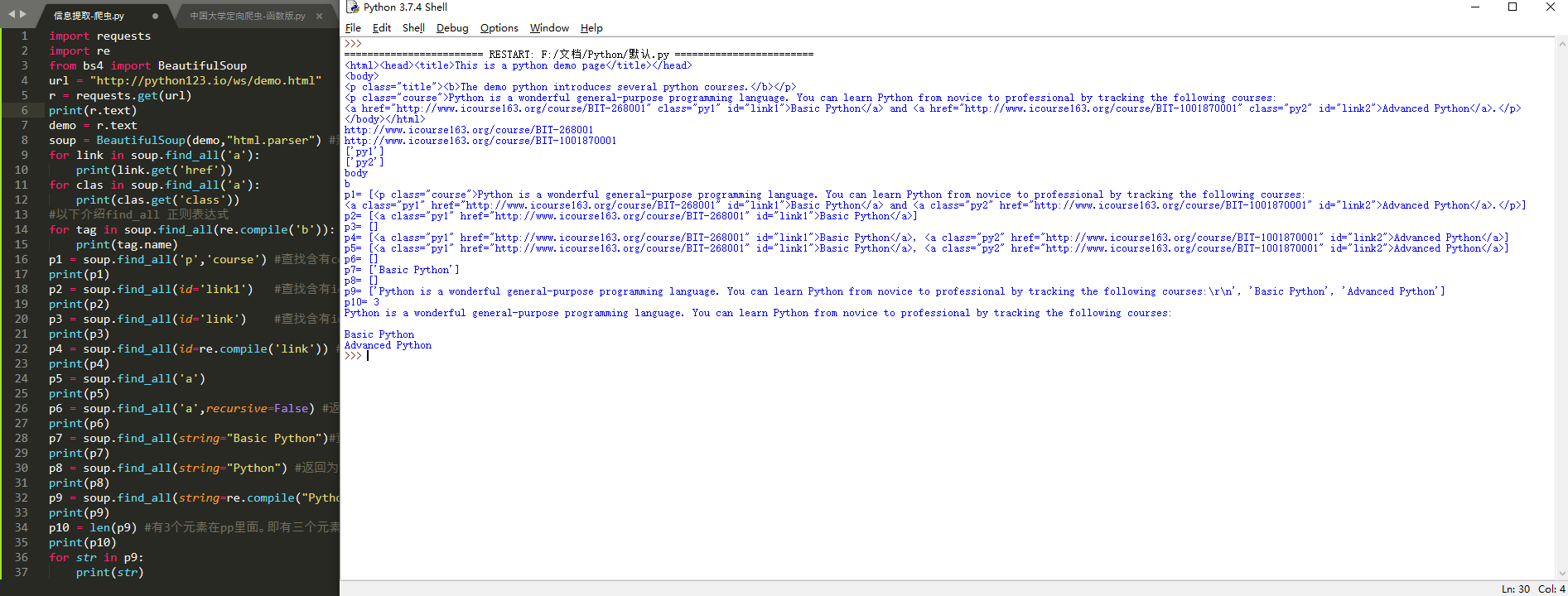
import requestsimport refrom bs4 import BeautifulSoupurl = "http://python123.io/ws/demo.html"r = requests.get(url)print(r.text)demo = r.textsoup = BeautifulSoup(demo,"html.parser") #熬一锅粥for link in soup.find_all(‘a‘): print(link.get(‘href‘))for clas in soup.find_all(‘a‘): print(clas.get(‘class‘))#以下介绍find_all 正则表达式for tag in soup.find_all(re.compile(‘b‘)): #查找所有以b开头的标签,第一个属性 print(tag.name)p1 = soup.find_all(‘p‘,‘course‘) #查找含有course的p标签内容print(p1)p2 = soup.find_all(id=‘link1‘) #查找含有id=‘link1‘属性的标签内容,注意:属性不等于文本print(p2)p3 = soup.find_all(id=‘link‘) #查找含有id=‘link‘属性的标签内容,没有,所以返回未空,即[]print(p3)p4 = soup.find_all(id=re.compile(‘link‘)) #使用正则表达式查找id属性含有link的内容print(p4)p5 = soup.find_all(‘a‘) #返回不为空,说明soup的子孙节点含有a标签print(p5)p6 = soup.find_all(‘a‘,recursive=False) #返回为空,说明soup的子节点无a标签print(p6)p7 = soup.find_all(string="Basic Python")#查找正文为且仅为Basic Python的元素print(p7)p8 = soup.find_all(string="Python") #返回为空print(p8)p9 = soup.find_all(string=re.compile("Python")) #正则表达式查找含有Python的元素,返回列表类型print(p9)p10 = len(p9) #有3个元素在pp里面。即有三个元素含Pythonprint(p10)for str in p9: print(str)Python 信息提取-爬虫
相关内容
- python10行代码,让你成功伪装逃过反爬虫程序,python简
- 推荐几本高质量的Python书籍--附github下载路径,github怎
- python读csv格式文档并用matplotlib绘制图表,pythonmatplot,
- python学习--quote()函数,,屏蔽特殊的字符、比如
- python语句结构(if判断语句),,一、python语句
- python安装第三方模块,python第三方库安装,模块分类1、
- Python—端口检测,检测端口,#!/usr/bin
- 数据标准化 (data normalization) 的原理及实现 (Python sklea
- python二进制转换,python将十进制转为二进制,题目描述:
- 一:python (int & str 的方法),python的int,1.变量:
评论关闭