Python高级应用程序设计任务,,一、主题式网络爬虫设
Python高级应用程序设计任务,,一、主题式网络爬虫设
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
易车网奥迪汽车信息的爬取2.主题式网络爬虫爬取的内容与数据特征分析
爬取易车网奥迪汽车的基本信息(汽车名称、汽车的标题图片、参考价、厂商指导价、排量、油耗),分析汽车的性价比包含多个方面的的特征值,以下只分析汽车排量跟价格这两个特征量之间的关系进而来分析汽车的性价比。3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
整个框架分为六个模块:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器、数据可视化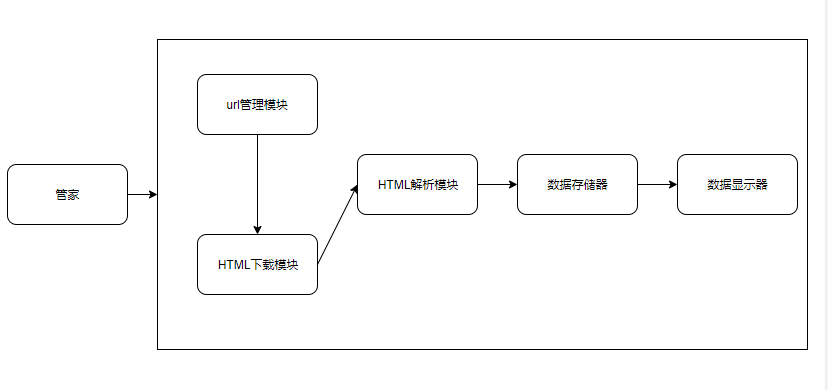
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
本文分别需要爬取奥迪汽车的列表页跟详情页,最后将详情页内的一重要数据存储在数据库中列表页:主要负责分析出详情页的请求地址,汽车名称,标题图片,厂商参考价详情页:主要负责分析其他的特征值2.Htmls页面解析
列表页:
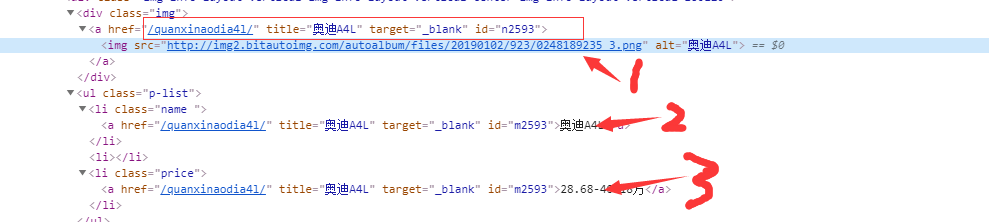
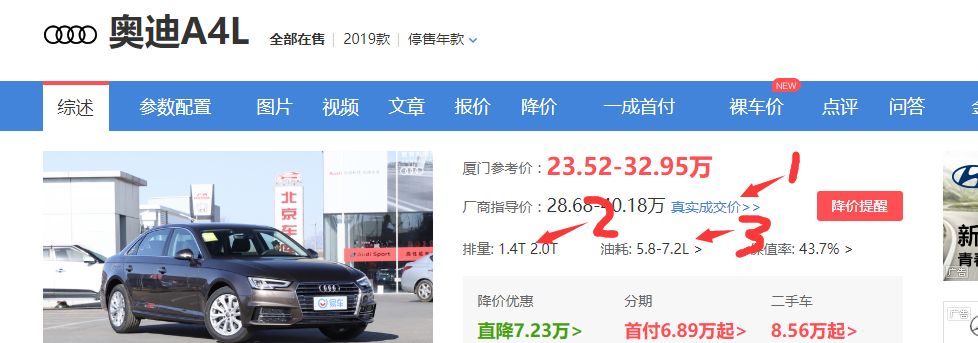
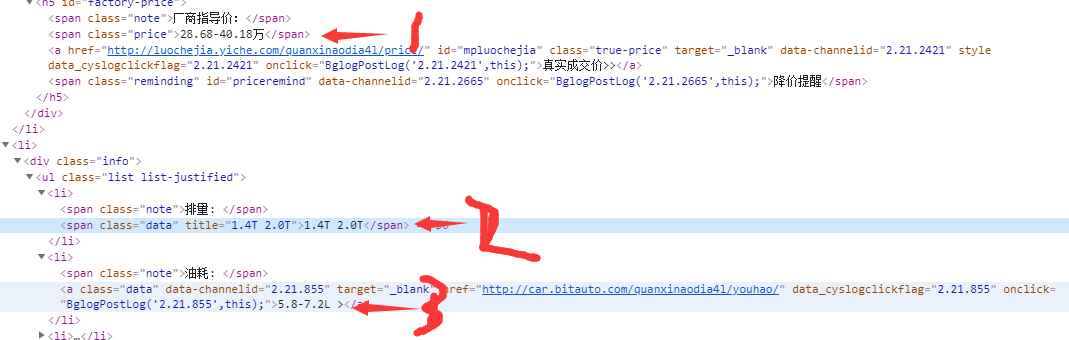
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)使用beautifulsoup模块遍历树的方法eg:获取标题图片的方法其他的类似
titleImgUrl = dataTag.find(‘div‘, class_=‘img‘).find(‘img‘)[‘src‘]

三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
①爬虫调度器模块
主要负责其他模块的协调工作
文件相对地址(文件名):奥迪/SpiderMan.py
#coding:utf-8from DataOutput import DataOutputfrom UrlManager import UrlManagerfrom HtmlParser import HtmlParserfrom SeabornShow import SeabornShowfrom HtmlDownloader import HtmlDownloaderimport seaborn as snsclass SpiderMan(object): def __init__(self): self.manager = UrlManager() self.downloader = HtmlDownloader() self.parser = HtmlParser() self.output = DataOutput() self.show = SeabornShow() def crawl(self,root_url): self.manager.add_new_url(root_url) while (self.manager.has_new_url() and self.manager.old_url_size() < 100): try: new_url = self.manager.get_new_url() print("》》开始下载页面内容") html = self.downloader.download(new_url) print("》》开始接解析下载的页面") new_urls,data = self.parser.parser(new_url,html) self.output.store_data(data) except: print("crawl failed") print("》》对解析的数据进行mysql数据库持久化操作") self.output.output_mysql() # 数据帧格式数据 df = self.output.mysql_to_pandas() print("》》散点图展示奥迪油耗跟价格的关系") self.show.show(df)if __name__ == "__main__": spider_man = SpiderMan() aodi = "http://car.bitauto.com/tree_chexing/mb_9/" # 奥迪列表页地址: spider_man.crawl(aodi)
② Url管理模块
维护爬取的url,跟未爬取的url地址
文件相对地址(文件名):奥迪/UrlManager.py
#coding:utf-8‘‘‘url管理器‘‘‘class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def has_new_url(self): ‘‘‘ 判断是否有url未被爬取 :return: ‘‘‘ return self.new_url_size() != 0 def get_new_url(self): ‘‘‘ 获取url :return: ‘‘‘ if self.has_new_url(): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url else: return None def add_new_url(self,url): ‘‘‘ 增加url :param url: :return: ‘‘‘ if url is None: return ‘‘‘ 增加时去重跟判断以处理的url避免重复处理出现死循环 ‘‘‘ if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self,urls): ‘‘‘ 增加一组url :param urls: :return: ‘‘‘ if urls is None or len(urls)==0: return for url in urls: self.add_new_url(url) def new_url_size(self): return len(self.new_urls) def old_url_size(self): return len(self.old_urls)
③数据库操作工具
主要负责数据库的连接,管理增删改查
import pymysql as psimport pandas as pdclass MysqlHelper: def __init__(self, host, user, password, database, charset): self.host = host self.user = user self.password = password self.database = database self.charset = charset self.db = None self.curs = None # 数据库连接 def open(self): self.db = ps.connect(host=self.host, user=self.user, password=self.password,database=self.database) self.curs = self.db.cursor() # 数据库关闭 def close(self): self.curs.close() self.db.close() # 数据增删改 def aud(self, sql, params): self.open() try: row = self.curs.execute(sql, params) self.db.commit() self.close() return row except : print(‘cud出现错误‘) self.db.rollback() self.close() return 0 # 解析为pandas def findPandas(self,sql): self.open() try: df = pd.read_sql(sql=sql,con=self.db) return df except: print(‘解析为pandas出现错误‘)
④数据库实体对象
包含数据库的个个字段之间的映射
class AODIItems(object): def __init__(self,name,titleImgUrl,referencePrice,guidePrice,displacement,oilConsumption): self.name = name self.titleImgUrl = titleImgUrl self.referencePrice = referencePrice self.guidePrice = guidePrice self.displacement = displacement self.oilConsumption = oilConsumption
1.数据爬取与采集
负责下载url管理器中提供的未爬url链接并在html
文件相对地址(文件名):奥迪/HtmlDownloader.py
#coding:utf-8import requestsimport chardet‘‘‘html下载器‘‘‘class HtmlDownloader(object): def download(self,url): try: if url is None: return sessions = requests.session() sessions.headers[ ‘User-Agent‘] = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36‘ r = sessions.get(url) if (r.status_code == 200): r.encoding = chardet.detect(r.content)["encoding"] return r.text return None except: print("downloader failed")if __name__ == "__main__": pass2.对数据进行清洗和处理
解析下载器的html页面,并解析出有效数据,也可以解析跟进的url链接
内嵌一个小的详情页爬虫,包括DetailsParser.py,DetailsDownloader.py
文件相对地址(文件名):奥迪/HtmlParser.py
#coding:utf-8import reimport urlparserimport urllibimport urllib3from bs4 import BeautifulSoup‘‘‘奥迪详情html解释器‘‘‘class DetailsParser(object): def parser(self,page_url,html_cont): try: if page_url is None and html_cont is None: return soup = BeautifulSoup(html_cont, "html.parser") new_datas = self._get_new_data(page_url, soup) return new_datas except: print("DetailsParser failed") ‘‘‘ 获取奥迪详细信息 ‘‘‘ def _get_new_data(self, page_url, soup): contTag = soup.find(‘h5‘,id=‘factory-price‘).find_parent().find_parent() data = {} # 指导价格 data[‘guidePrice‘] = soup.find(‘h5‘,id=‘factory-price‘).find(‘span‘,class_=‘price‘).string # 排量 data[‘displacement‘] = contTag.find_next_sibling().select(‘li:nth-of-type(1)‘)[0].find(‘span‘,class_=‘data‘).string # 油耗 data[‘oilConsumption‘] = contTag.find_next_sibling().select(‘li:nth-of-type(2)‘)[0].find(‘a‘,class_=‘data‘).string return data if __name__ == "__main__": pass详情页内容下载与解析
文件相对地址(文件名):奥迪/DetailsDownloader.py
#coding:utf-8import requestsimport chardetclass DetailsDownloader(object): def download(self, url): try: if url is None: return sessions = requests.session() sessions.headers[ ‘User-Agent‘] = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36‘ r = sessions.get(url) if (r.status_code == 200): r.encoding = chardet.detect(r.content)["encoding"] return r.text return None except: print("DetailsDownloader failed") if __name__ == "__main__": pass文件相对地址(文件名):奥迪/DetailsParser.py
#coding:utf-8import reimport urlparserimport urllibimport urllib3from bs4 import BeautifulSoup‘‘‘奥迪详情html解释器‘‘‘class DetailsParser(object): def parser(self,page_url,html_cont): try: if page_url is None and html_cont is None: return soup = BeautifulSoup(html_cont, "html.parser") new_datas = self._get_new_data(page_url, soup) return new_datas except: print("DetailsParser failed") ‘‘‘ 获取奥迪详细信息 ‘‘‘ def _get_new_data(self, page_url, soup): contTag = soup.find(‘h5‘,id=‘factory-price‘).find_parent().find_parent() data = {} # 指导价格 data[‘guidePrice‘] = soup.find(‘h5‘,id=‘factory-price‘).find(‘span‘,class_=‘price‘).string # 排量 data[‘displacement‘] = contTag.find_next_sibling().select(‘li:nth-of-type(1)‘)[0].find(‘span‘,class_=‘data‘).string # 油耗 data[‘oilConsumption‘] = contTag.find_next_sibling().select(‘li:nth-of-type(2)‘)[0].find(‘a‘,class_=‘data‘).string return data if __name__ == "__main__": pass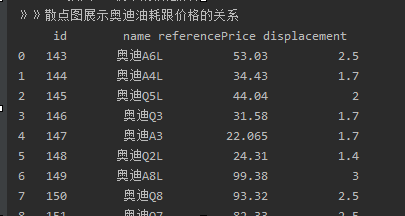
3.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
文件相对地址(文件名):奥迪/SeabornShow.py
import seaborn as snsimport pandas as pdimport pymysql as psimport numpy as npimport scipy.stats as sciimport matplotlib.pyplot as pltimport re# seaborn构建散点图class SeabornShow(object): ‘‘‘ 奥迪油耗参考价数据的展示函数 ‘‘‘ def show(self,data): sns.set(style="dark") # 数据整理 for i in range(len(data)): # 油耗 取算数平均值 data.iloc[i, 5] = self.ave(self.analyticalFigures(data.iloc[i, 5])) # 参考价 取算数平均值 data.iloc[i, 3] = self.ave(self.analyticalFigures(data.iloc[i, 3])) print(data[[‘id‘,‘name‘,‘referencePrice‘,‘displacement‘]]) sns.jointplot(x=‘displacement‘,y=‘referencePrice‘,data=data) plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] plt.ylabel("油耗-价格对照表") plt.show() def analyticalFigures(self,str): return re.compile(r‘[\d.]+‘).findall(str) def ave(self,numList): result = 0 sum = 0.0 for num in numList: sum = sum + float(num) result = sum / len(numList) return resultif __name__ == ‘__main__‘: seabornShow = SeabornShow() # seabornShow.show() rs = np.random.RandomState(2) df = pd.DataFrame(rs.randn(200, 2), columns=[‘A‘, ‘B‘]) # print(df) sns.jointplot(x=‘A‘,y=‘B‘,data=df,kind=‘reg‘)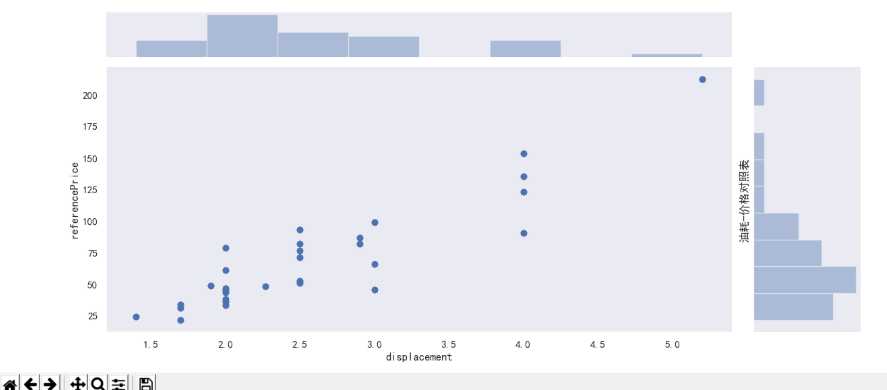
4.数据持久化
将解析器解析处理的数据持久化化到mysql数据库
文件相对地址(文件名):奥迪/DataOutput.py
#coding:utf-8import codecsfrom MysqlHelper import MysqlHelperclass DataOutput(object): def __init__(self): self.datas=[] self.host = "localhost" self.user = "root" self.password = "" self.database = "ai_info" self.charset = "utf-8" self.mh = MysqlHelper(self.host,self.user,self.password,self.database,self.charset) def store_data(self,data): if data is None: return self.datas = data # 在mysql数据库持久化 def output_mysql(self): TABLE_NAME = "ad_data" sql = "insert into " + TABLE_NAME + " (name, titleImgUrl, referencePrice, guidePrice, displacement, oilConsumption) values(%s,%s,%s,%s,%s,%s)" rows = 0 for data in self.datas: name = data[‘name‘] titleImgUrl = data[‘titleImgUrl‘] referencePrice = data[‘referencePrice‘] guidePrice = data[‘guidePrice‘] displacement = data[‘displacement‘] oilConsumption = data[‘oilConsumption‘] params = (name, titleImgUrl, referencePrice, guidePrice, displacement, oilConsumption) row = self.mh.aud(sql,params) rows = rows + row print("*******插入%s 辆车的信息成功!" % rows) ‘‘‘ 取轿车信息并转化为pandas 的数据帧类型存储 ‘‘‘ def mysql_to_pandas(self): TABLE_NAME = "ad_data" sql = "select * from " + TABLE_NAME return self.mh.findPandas(sql)
表ad_data
id | Int | 自增主键 |
name | Varchar(255) | 汽车名称 |
titleImgURl | Varchar(255) | 镖旗图片 |
referencePrice | Varchar(255) | 参考价 |
guidePrice | Varchar(255) | 厂商价 |
Displacement | Varchar(255) | 排量 |
OilConsumption | Varchar(255) | 油耗 |
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
2T的排气量的奥迪普遍比较贵
2.对本次程序设计任务完成的情况做一个简单的小结。
克服了很多困难,百度找教程,请教他人,最后与组员一起终于完成了这次的程序设计。
感觉收获到很多东西,纸上得来终觉浅”,只有去实践了才能真正的掌握牢知识!
Python高级应用程序设计任务
相关内容
- 如何在python使用mysql的增删改查,,非原创1、建立一张表
- 用Python处理Unix信号,,UNIX / Lin
- python基础知识--标志位的设定,,在单层循环的退出中,
- python中的装饰器,python常用装饰器,0、闭包想要理解p
- python基础 文件操作,python文件读取,文件操作1 1 #文
- 七个python gui图形界面开发框架,python框架,Kivy这是一个
- python3 pexpect模块,python模块,pexpectimp
- Python编程练习(一),,学习中,都是从书上找
- Python_base_函数返回值,返回值函数,返回值介绍print
- python读csv格式文档并用matplotlib绘制图表,pythonmatplot,
评论关闭