关于pandas增加行时,索引名称的一些问题,
关于pandas增加行时,索引名称的一些问题,
学习pandas两天了,关于这个增加行的问题一直困扰着我,测试了几个代码,终于搞通了一点(昨天是因为代码敲错了。。。)
直接上代码:
1 dates = pd.date_range('20170101',periods=6) 2 df1 = pd.DataFrame(np.arange(24).reshape((6,4)),index = dates,columns=['A','B','C','D'])
创建了一个名为df1的DataFrame,其中数据为24为排列数,关键是index的取值,我这里用的pandas自带的日期序列函数生成的dates
生成的df1如图:
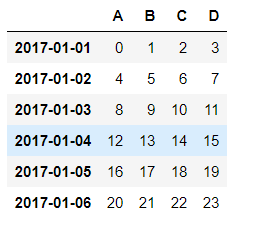
这里可以看到index的名称为date_time格式的
需要加入新的一行时,我采用了loc函数:
df1.loc[pd.to_datetime('20170108'),['A','B','C','D','E']] = [1,2,3,4,5]
按照之前的index的格式添加,显然增加的新行和之前行的形式是相同的:
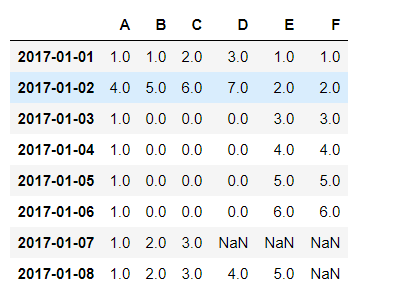
(这里图片多添加了一行,不牵扯)
但是如果,添加的index和之前的数据类型不同时,会报错么?
试一试:
df1.loc['20180108',['D','E']]=[1,2]
这里我将一个字符串’20180108‘,添加到新行的index,本以为会报错,结果:
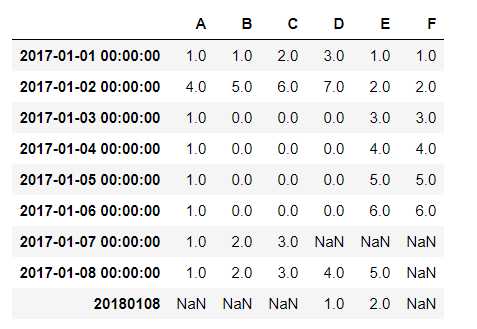
添加成功了,不过表格的格式也发生更改了,date_time原本隐藏的时间00:00:00显示出来。接着我添加相同名称的int32位变量试试:
df1.loc[20180108,['E','C']] = [1,3]
同样添加成功,神奇的一幕发生了:
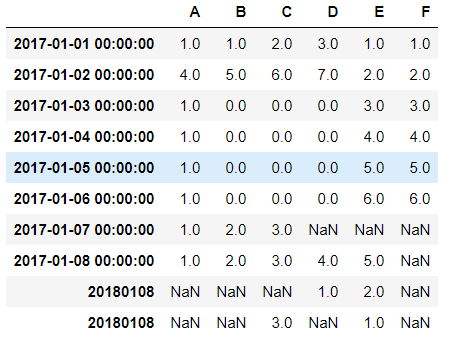
出现了两个完全相同的index:20180108
这是为什么呢?原来是因为,上面那行的20180108的数据类型是str,而下面那行的20180108数据类型是int32,系统判断是两个完全不同的数据,所以会出现两个完全相同的index在表格中
接着,再添加一个date_time格式的’20180108‘吧:
df1.loc[pd.to_datetime('20180108'),['A','B']] = [3,4]
结果不出所料:
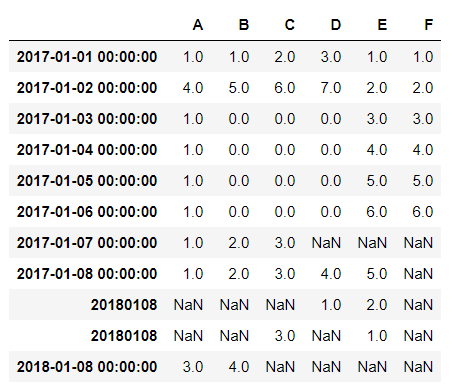
成功添加。
至此,pandas的添加行操作原理基本搞明白了,keep learning。
相关内容
- 暂无相关文章
评论关闭