python_正则表达式,python正则表达式详解,字符组:[] 写再
python_正则表达式,python正则表达式详解,字符组:[] 写再
字符组:[] 写再括号中的内容,若出现,都可以被匹配到。
[0-9] 匹配数字
[a-z] 匹配小写字母
[A-Z] 匹配大写字母
[a-zA-Z] 匹配所有的大写和小写的字母
[a-zA-Z0-9] 匹配所有的大写和小写的字母和数字
[a-zA-Z0-9_] 匹配所有的大写和小写的字母和数字和下划线
[0-9a-fA-F] 可以匹配水族,大小写形式的a~f,用来验证十六进制字符
元字符:
\w 匹配数字字母下划线 [a-zA-Z0-9_]
\d 匹配数字 [0-9]
\s 匹配所有的空白符 包括:换行符(回车)、制表符(Tab)、空格
\t 匹配制表符(Tab)
\n 匹配换行符(回车)
空格匹配空格~
\W 匹配非数字字母下划线和\w取反
\D 匹配非数字和\d取反
\S 匹配非空白符和\s取反
[\s\S] [\w\W] [\d\D] 是三组全集 匹配所有字符
\b 表示单词的边界(开头或者结尾)
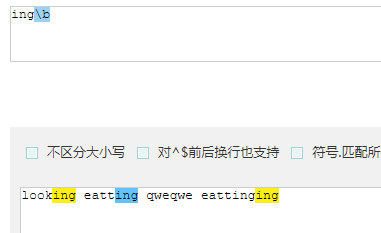 匹配所有ing结尾的单词的边界
匹配所有ing结尾的单词的边界
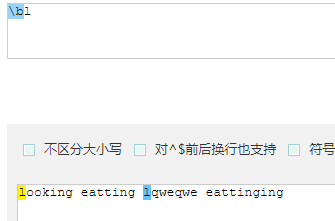 匹配所有以l开头的单词的边界
匹配所有以l开头的单词的边界
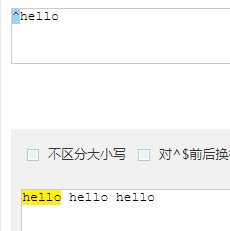
^ 匹配一个字符串的开始
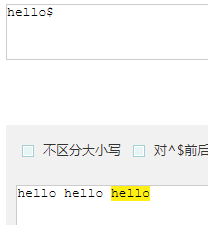
$ 匹配一个字符串的结束
. ‘‘点‘‘表示匹配除了换行符之外的所有字符
[] 只有出现在中括号中的内容都可以被匹配
有一些有特殊意义的元字符进入字符组中回回复它本来的意义:.、|、 [、 ]、(、 )、
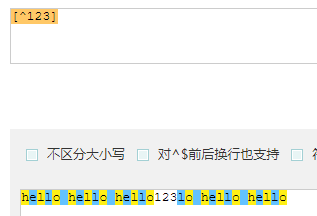
[^] 匹配除了中括号中的所有内容
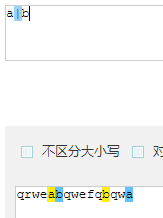
| 或
 复合a规则或者b规则的都可以被匹配
复合a规则或者b规则的都可以被匹配
如果a规则是b规则的一部分,且a规则比b规则要苛刻\长,就把a规则写在前面,将更复杂的\更长的规则写在最前面。
() 分组 表示给几个字符加上量词约束需求的时候,就给这些量词分在一个组。
量词:
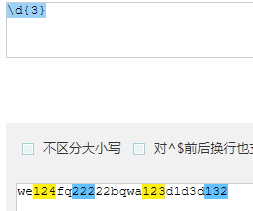
{n} 表示这个量词之前的字符出现n次,且只能出现n次。
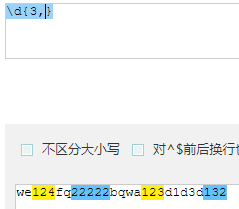
{n,} 表示这个量词之前的字符至少出现n次。
{n,m} 表示这个量词之前的字符出现n到m次。
? 表示匹配这个量词之前的字符出现0次或者1次。当表示某个字符可有可无时。
+ 表示匹配量词之前的字符出现1次或者多次。
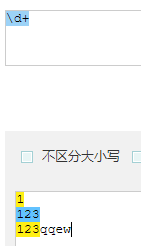
* 表示匹配量词之前的字符出现0次或者多次。
python_正则表达式
评论关闭