Python3标准库:statistics统计计算,
Python3标准库:statistics统计计算,
1. statistics统计计算
statistics模块实现了很多常用的统计公式,允许使用Python的各种数值类型(int、float、Decimal和Fraction)来完成高效计算。
1.1 平均值
共支持3种形式的平均值:均值(mean),中值或中位数(median),以及众数(mode)。可以用mean()计算算术平均值。
from statistics import * data = [1, 2, 2, 5, 10, 12] print('{:0.2f}'.format(mean(data)))
对于整数和浮点数,这个函数的返回值总是float。对于Decimal和Fraction输入数据,结果与输入的类型相同。
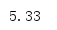
可以使用mode()计算一个数据集中最常见的数据点。
from statistics import * data = [1, 2, 2, 5, 10, 12] print(mode(data))
其返回值总是输入数据集的一个成员。由于mode()把输入处理为一个离散值集合,并且统计出现次数,所以实际上输入不必是数值。
计算中值(或中位数)有4种变形。 前三种是一般算法的简单版本,只是在处理元素个数为偶数的数据集时采用了不同方法。
from statistics import * data = [1, 2, 2, 5, 10, 12] print('median : {:0.2f}'.format(median(data))) print('low : {:0.2f}'.format(median_low(data))) print('high : {:0.2f}'.format(median_high(data)))
median()会查找中间的值。如果数据集包含偶数个值,则取两个中间元素的平均值。median_low()总是返回输入数据集中的一个值,对于有偶数个元素的数据集,会返回两个中间元素中较小的一个。median_high()与之类似,不过会返回两个中间元素中较大的一个。

中值计算的第4个版本是median_grouped(),它会把输入看作连续数据。这个函数计算50%百分位数(即中值)的做法是首先是要所提供的间隔宽度找出中值区间,然后使用落入该区间的数据集中的具体值位置在该区间中插值。
from statistics import * data = [10, 20, 30, 40] print('1: {:0.2f}'.format(median_grouped(data, interval=1))) print('2: {:0.2f}'.format(median_grouped(data, interval=2))) print('3: {:0.2f}'.format(median_grouped(data, interval=3)))
随着间隔宽度的增加,为相同数据集计算的中值会改变。

1.2 方差
统计使用两个值描述一个值集相对于均值的分散度。方差(variance)是各个值与均值之差平方的平均,标准偏差或标准差(standard deviation)是方差的平方根(这很有用,因为取平方根可以使标准差与输入数据有相同的单位)。如果方差或标准差的值很大,这说明一个数据集是分散的,而如果这个值很小,则说明数据在靠近均值聚集。
import statistics x =[1,2,3,4,5,10,9,8,7,6] y1 = statistics.pvariance(x) print(y1) y2 = statistics.pstdev(x) print(y2) y3 = statistics.variance(x) print(y3) y4 = statistics.stdev(x) print(y4)
Python包括两组函数来计算方差和标准差,具体取决于数据集是表示总体还是总体中的一个样本。这个例子首先pvariance()和pstdev()计算总体的方差和标准哈。然后使用variance()和stdev()计算一个子集的样本方差和标准差。

相关内容
- 暂无相关文章
评论关闭