一个完整的python大作业,,由于能选择一个感兴趣
一个完整的python大作业,,由于能选择一个感兴趣
由于能选择一个感兴趣的网站进行数据分析,所以这次选择爬取的网站是新华网,其网址为"http://www.xinhuanet.com/",然后对其进行数据分析并生成词云
运行整个程序相关的代码包
import requestsimport refrom bs4 import BeautifulSoupfrom datetime import datetimeimport pandasimport sqlite3import jiebafrom wordcloud import WordCloudimport matplotlib.pyplot as plt
爬取网页信息
url = "http://www.xinhuanet.com/"f=open("css.txt","w+")res0 = requests.get(url)res0.encoding="utf-8"soup = BeautifulSoup(res0.text,"html.parser")newsgroup=[]for news in soup.select("li"): if len(news.select("a"))>0: print(news.select("a")[0].text) title=news.select("a")[0].text f.write(title)f.close()存入txt文件中,并进行字词统计
f0 = open(‘css.txt‘,‘r‘)qz=[]qz=f0.read()f0.close()print(qz)words = list(jieba.cut(qz))ul={‘:‘,‘的‘,‘"‘,‘、‘,‘”‘,‘“‘,‘。‘,‘!‘,‘:‘,‘?‘,‘ ‘,‘\u3000‘,‘,‘,‘\n‘}dic={}keys = set(words)-ulfor i in keys: dic[i]=words.count(i)c = list(dic.items())c.sort(key=lambda x:x[1],reverse=True)f1 = open(‘diectory.txt‘,‘w‘)for i in range(10): print(c[i]) for words_count in range(c[i][1]): f1.write(c[i][0]+‘ ‘)f1.close()存入数据库
df = pandas.DataFrame(words)print(df.head())with sqlite3.connect(‘newsdb3.sqlite‘) as db: df.to_sql(‘newsdb3‘,con = db)
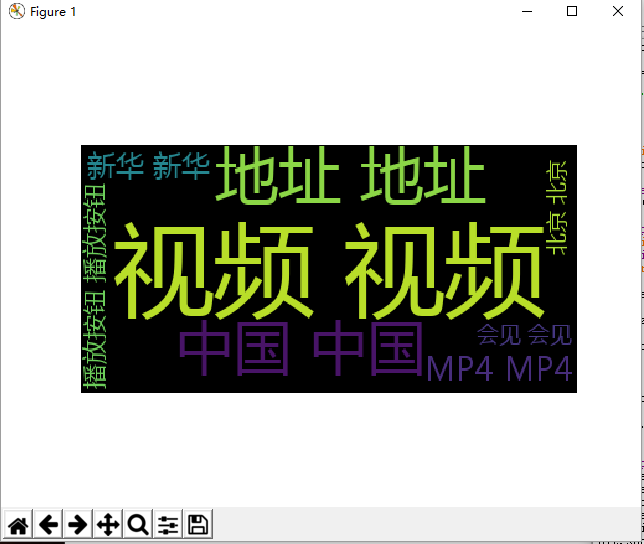
制作词云
f3 = open(‘diectory.txt‘,‘r‘)cy_file = f3.read()f3.close()cy = WordCloud().generate(cy_file)plt.imshow(cy)plt.axis("off")plt.show()最终成果



完整代码
import requestsimport refrom bs4 import BeautifulSoupfrom datetime import datetimeimport pandasimport sqlite3import jiebafrom wordcloud import WordCloudimport matplotlib.pyplot as plturl = "http://www.xinhuanet.com/" f=open("css.txt","w+")res0 = requests.get(url)res0.encoding="utf-8"soup = BeautifulSoup(res0.text,"html.parser")newsgroup=[]for news in soup.select("li"): if len(news.select("a"))>0: print(news.select("a")[0].text) title=news.select("a")[0].text f.write(title)f.close()f0 = open(‘css.txt‘,‘r‘)qz=[]qz=f0.read()f0.close()print(qz)words = list(jieba.cut(qz))ul={‘:‘,‘的‘,‘"‘,‘、‘,‘”‘,‘“‘,‘。‘,‘!‘,‘:‘,‘?‘,‘ ‘,‘\u3000‘,‘,‘,‘\n‘}dic={}keys = set(words)-ulfor i in keys: dic[i]=words.count(i)c = list(dic.items())c.sort(key=lambda x:x[1],reverse=True)f1 = open(‘diectory.txt‘,‘w‘)for i in range(10): print(c[i]) for words_count in range(c[i][1]): f1.write(c[i][0]+‘ ‘)f1.close()df = pandas.DataFrame(words)print(df.head())with sqlite3.connect(‘newsdb3.sqlite‘) as db: df.to_sql(‘newsdb3‘,con = db)f3 = open(‘diectory.txt‘,‘r‘)cy_file = f3.read()f3.close()cy = WordCloud().generate(cy_file)plt.imshow(cy)plt.axis("off")plt.show()一个完整的python大作业
相关内容
- Python——div函数的使用及理解,div公式,div函数就是对数
- Python 接口开发-泛微OA的SOAP接口,,一、功能需求泛微
- python照相机模型与增强现实,,这次试验主要实现以平
- python threading.current_thread().name和.getName()有什么区别,
- Python IDLE theme,,#转自 http:/
- Python可是写脚本的神器!相当牛逼!信息资产收集类脚
- python读取yaml文件,,yaml文件可以存储
- Python Kite 使用教程 轻量级代码提示,,1:概述今天升级
- python创建矩阵,,创建二维数组的办法直
- 零基础小白怎么用Python做表格?,,用Python操作E
评论关闭