python中------decode解码出现的0xca问题解决方法,,一。错误:解决方法:
python中------decode解码出现的0xca问题解决方法,,一。错误:解决方法:
一。错误:
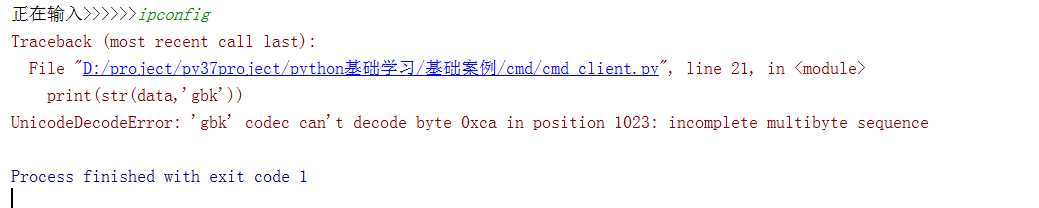
解决方法:
#源代码data = sk.recv(1024)print(str(data,‘gbk‘))#修改代码data = sk.recv(1024)print(str(data,‘gbk‘,‘ignore’))
二。常见错误整理
0x00 问题引出:
result = res.decode(‘utf-8‘) #当执行该语句的时候,会造成异常:
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xe5 in position 103339: invalid continuation byte
0x01 问题分析
该情况是由于出现了无法进行转换的 二进制数据 造成的,可以写一个小的脚本来判断下,是整体的字符集参数选择上出现了问题,还是出现了部分的无法转换的二进制块:
#python3#以读入文件为例:f = open("data.txt","rb")#二进制格式读文件while True: line = f.readline() if not line: break else: try: #print(line.decode(‘utf8‘)) line.decode(‘utf8‘) #为了暴露出错误,最好此处不print except: print(str(line))0x03 解决方法
修改字符集参数,一般这种情况出现得较多是在国标码(GBK)和utf8之间选择出现了问题。出现异常报错是由于设置了decode()方法的第二个参数errors为严格(strict)形式造成的,因为默认就是这个参数,将其更改为ignore等即可。例如:line.decode("utf8","ignore")python中------decode解码出现的0xca问题解决方法
相关内容
- 『Python』Numpy学习指南第十章_高端科学计算库scipy入门
- Python模拟页面调度LRU算法,,所谓LRU算法,是指
- python 函数 练习,,# 2、写函数,接收
- Python3中// 和/区别,," / "表示浮点数
- Python基础 之 数据类型,,一、运算符算数运算a
- 命令行运行python -m http.server报错,,最近在学习网站搭建
- python3.5过滤网址和图片的函数自己亲测可用,,def has_
- python函数参数*args **kwargs,,毕业多年,把C++都
- python数据结构和算法,,栈-先进后出clas
- python3的运算符,,1,Python的加
评论关闭