Python 入门,,一、编程语言分哪些种
Python 入门,,一、编程语言分哪些种
一、编程语言分哪些种类?
一:机器语言:机器语言是用二进制代码表示的计算机能直接识别和执行的一种机器指令的集合。
优点:灵活、直接执行和速度快。
缺点:不同型号的计算机其机器语言是不相通的,按着一种计算机的机器指令编制的程序,不能在另一种计算机上执行。二:汇编语言:汇编语言的实质和机器语言是相同的,都是直接对硬件操作,只不过指令采用了英文缩写的,标识符更容易识别和记忆。它同样需要编程者将每一步具体的操作用命令的形式写出来。
优点:能完成一般高级语言所不能实现的操作,而且源程序经汇编生成的可执行文件比较小,且执行速度很快。
缺点:源程序比较冗长、复杂、容易出错,而且使用汇编语言编程需要有更多的计算机专业知识。三:高级语言:明确地讲,高级语言就是说人话,用人类能读懂的(比如英文)字符编程。高级语言是绝大多数编程者的选择。和汇编语言相比,它不但将许多相关的机器指令合成为单条指令并且去掉了与具体操作有关但与完成工作无关的细节,例如使用堆栈、寄存器等。
优点:大大简化了程序中的指令。同时,由于省略了很多细节,编程者也就不需要有太多的专业知识。
缺点:高级语言所编制的程序不能直接被计算机识别,必须经过转换才能被执行。
按转换方式可将它们分为两类: 解释类:执行方式类似于我们日常生活中的“同声翻译”,应用程序源代码一边由相应语言的解释器“翻译”成目标代码(如python程序,先翻译/编译成字节码,然后由解释器解释执行,这个过程程序员都无需关心了,享受这种便利即可),一边执行
优点:这种方式比较灵活,调试程序极为方便,程序一旦出错,立即调试立即就可以测试结果
缺点:效率比较低,而且不能生成可独立执行的可执行文件,应用程序不能脱离其解释器。只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
编译类:编译是指在程序执行之前,就将程序源代码“翻译”成机器指令,并保存成二进制文件 优点:编译后的代码可以直接在机器上运行,运行速度比解释型要高。 缺点:调试程序麻烦,程序一旦需要修改,必须先修改源代码,再重新编译后才能执行。
总结:编程语言经历了:机器语言-------->汇编语言------------>高级语言(java,C#,php,ruby,python)
1:开发效率从低到高
2:执行效率从高到低
3:掌握难度从难到易
注解:执行效率不是问题,硬件已经足够用,于是开发效率成了关键,因而高级语言在当今世界大行其道。
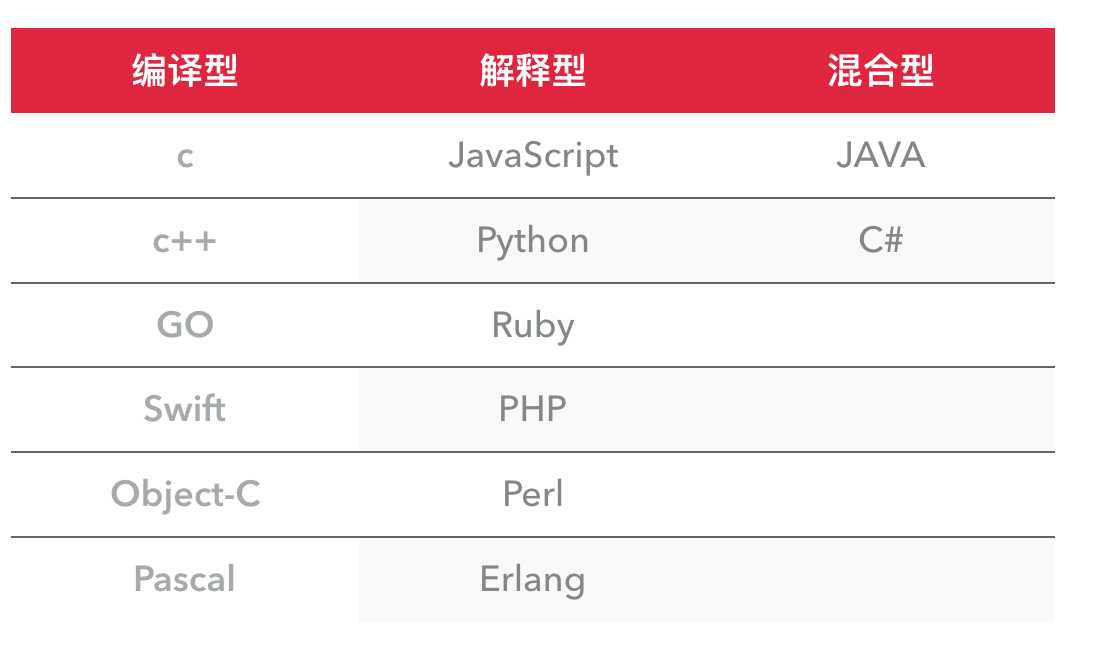
编译型vs解释型
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
注解:java代码号称一次编译到处运行,因为java代理需要先编译成字节码(一种中间格式的代码),然后拿着字节码到处运行,每次运行都需要交给jvm去编译成机器指令后才能执行,因而java是混合型
而有的人会有疑问,python代码也是先编译成字节码然后交给python解释器去执行的啊,难道python不是混合型吗?当然不是
1. 首先需要知道,只有在import导入py文件时,才会产生pyc字节码文件,该字节码文件是可以代替源文件而直接执行的(导入的时候也会产生字节码)
2. 但每次执行py文件,产生的字节码并不会保留下来,也就是说,每次执行py文件,都是要重新经历一遍:py文件->字节码-->python解释器-->机器码,每次都是一个重新解释执行的过程。
二、Python入门
2.1 第一句python代码
1. 解释器:即时调试代码,代码无法永久保存
2. 文件:永久保存代码
在D:\python_test\目录下新建文件hello.py,编写代码如下
print(‘hello world‘)
执行hello.py,即pythonD:\python_test\hello.py
python内部执行过程如下:
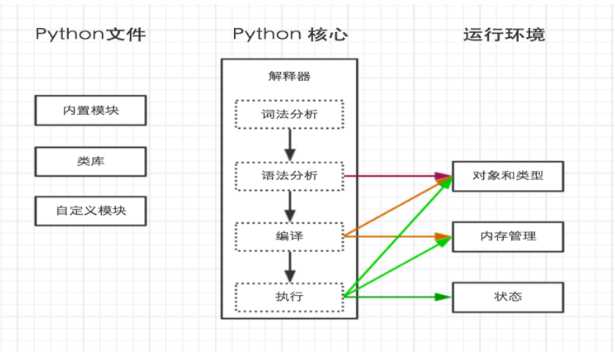
上一步中执行pythonD:\python_test\hello.py时,明确的指出 hello.py 脚本由 python 解释器来执行。
在linux平台中如果想要类似于执行shell脚本一样执行python脚本,例:./hello.py,那么就需要在 hello.py 文件的头部指定解释器,如下:
#!/usr/bin/env python #该行只对linux有效print(‘hello world‘)
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
#!/usr/bin/env python (用什么执行)# -*- coding: utf-8 -*-
2.2 注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
2.3 执行脚本传入参数
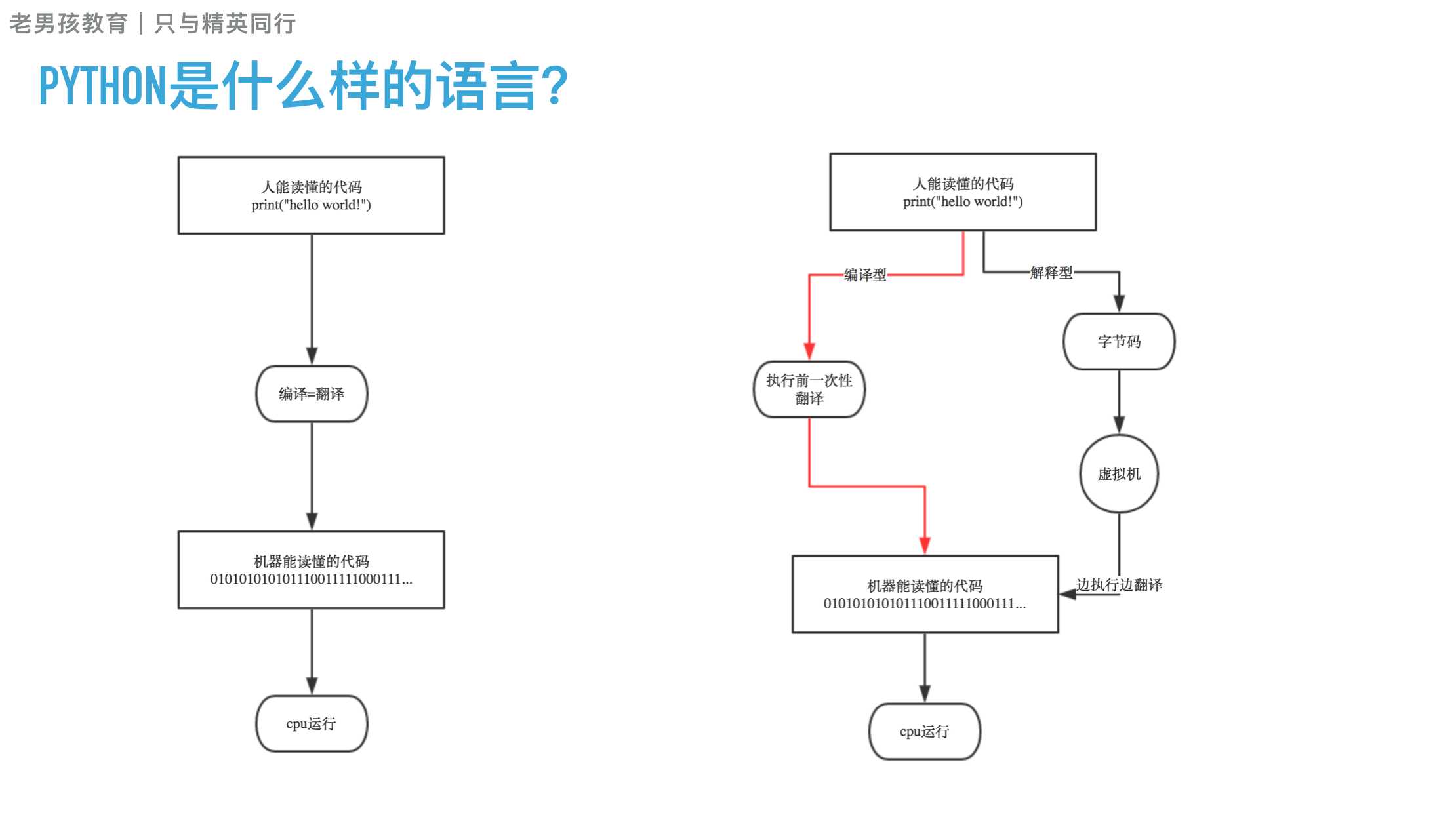
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
Python内部提供的模块业内开源的模块程序员自己开发的模块Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
| 123456 | #!/usr/bin/env python |
执行
C:\Users\Administrator>python D:\python_test\hello.py arg1 arg2 arg3[‘D:\\python_test\\hello.py‘, ‘arg1‘, ‘arg2‘, ‘arg3‘]
2.4 了解pyc文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
三、变量
3.1 为何要有变量
程序执行的本质就是一系列状态的变化,变量二字的核心一个是变,一个是量,‘变‘正好对应程序的变化,‘量‘即计量,反映的是某种状态,
比如一款游戏中的人物初始等级:level=1,过了一段时间后升级了:level=10
3.2 变量的声明与引用
#!/usr/bin/env pythonname=‘egon‘ #变量的声明
name #通过变量名,引用变量的值
print(name) #引用并且打印变量名name对应的值,即‘egon‘
3.3 标识符命令规范:
变量名只能是 字母、数字或下划线的任意组合变量名的第一个字符不能是数字以下关键字不能声明为变量名[‘and‘, ‘as‘, ‘assert‘, ‘break‘, ‘class‘, ‘continue‘, ‘def‘, ‘del‘, ‘elif‘, ‘else‘, ‘except‘, ‘exec‘, ‘finally‘, ‘for‘, ‘from‘, ‘global‘, ‘if‘, ‘import‘, ‘in‘, ‘is‘, ‘lambda‘, ‘not‘, ‘or‘, ‘pass‘, ‘print‘, ‘raise‘, ‘return‘, ‘try‘, ‘while‘, ‘with‘, ‘yield‘]
3.4 变量的赋值
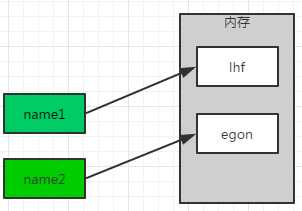
#!/usr/bin/env pythonname1=‘lhf‘name2=‘egon‘
#!/usr/bin/env pythonname1=‘lhf‘name2=name1
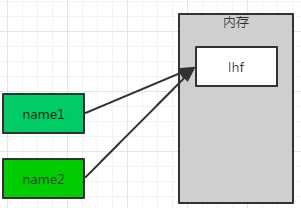

#!/usr/bin/env python#一个游戏人物的等级由1级升到2级level=1level=2#一个游戏帐号的密码由‘123‘改成‘456‘passwd=‘123‘passwd=‘456‘#一个人的名字有‘lhf‘改成‘egon‘name=‘lhf‘name=‘egon‘
Python 入门
评论关闭