python之多线程,,(首发于 2018
python之多线程,,(首发于 2018
(首发于 2018 年 8 月 1 日)
线程是进程中可以同时运行的不同程序,有时被称为轻量进程,是系统独立调度和分派的基本单位。多线程运行有很多优点:
可以把运行时间长的任务放到后台去处理。
程序的运行速度可能会加快。
用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
在一些需要等待的任务实现上,比如用户输入、文件读写好人网络收发数据等,线程就可以释放一些珍贵的系统资源,避免内存占用。
1. Python 中线程实现
python 中提供了两个模块:thread 和 threading 实现多进程,thread 是低级模块,threading 是高级模块,是对 thread 的封装。在绝大数情况下,我们只需要使用 threading 这个高级模块就能实现多线程。
使用 threading 实现多线程有两种方法,一种是把一个函数传入并创建 Thread 实例,然后调用 start 方法开始执行;另一种是直接继承 threading.Thread 类并创建自定义线程类,然后重写 __init__ 方法和 run 方法。下面就分别介绍这两种实现多线程的方法。
1.1 创建 Thread 实例
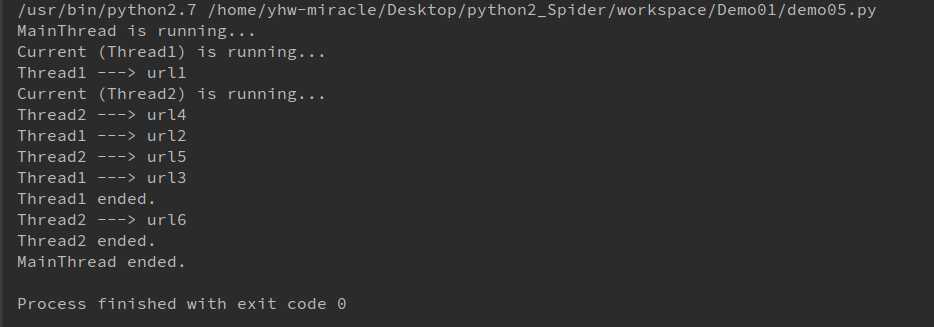
1 import random, time, threading 2 3 4 def thread_run(urls): 5 print(‘Current (%s) is running...‘ % threading.current_thread().name) 6 for url in urls: 7 print(‘%s ---> %s‘ % (threading.current_thread().name, url)) 8 time.sleep(random.random()) 9 print(‘%s ended.‘ % threading.current_thread().name)10 11 12 if __name__ == ‘__main__‘:13 print(‘%s is running...‘ % threading.current_thread().name)14 t1 = threading.Thread(target=thread_run, name=‘Thread1‘, args=([‘url1‘, ‘url2‘, ‘url3‘],))15 t2 = threading.Thread(target=thread_run, name=‘Thread2‘, args=([‘url4‘, ‘url5‘, ‘url6‘],))16 17 t1.start()18 t2.start()19 t1.join()20 t2.join()21 22 print(‘%s ended.‘ % threading.current_thread().name)
1.2 创建自定义线程类
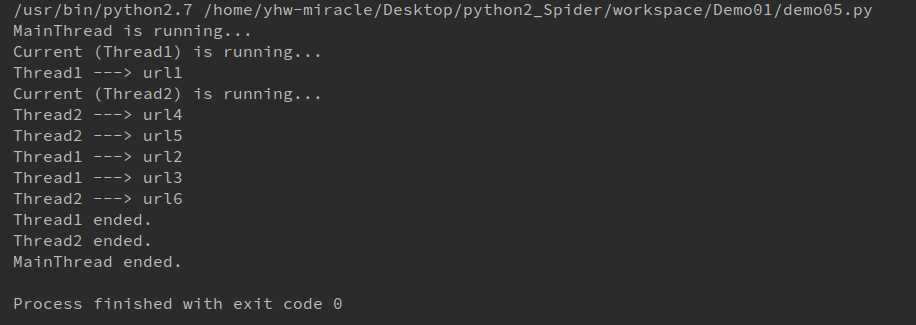
1 import random, threading, time 2 3 4 class MyThread(threading.Thread): 5 def __init__(self, name, urls): 6 threading.Thread.__init__(self, name=name) 7 self.urls = urls 8 9 def run(self):10 print(‘Current (%s) is running...‘ % threading.current_thread().name)11 for url in self.urls:12 print(‘%s ---> %s‘ % (threading.current_thread().name, url))13 time.sleep(random.random())14 print(‘%s ended.‘ % threading.current_thread().name)15 16 17 if __name__ == ‘__main__‘:18 print(‘%s is running...‘ % threading.current_thread().name)19 t1 = MyThread(name=‘Thread1‘, urls=[‘url1‘, ‘url2‘, ‘url3‘])20 t2 = MyThread(name=‘Thread2‘, urls=[‘url4‘, ‘url5‘, ‘url6‘])21 22 t1.start()23 t2.start()24 t1.join()25 t2.join()26 27 print(‘%s ended.‘ % threading.current_thread().name)
2. 线程同步
如果多个线程共同对某个数据修改,则可能会出现不可预料的结果。为了保证数据的正确性,我们需要对多个进行同步。Python 中使用 Thread 对象的 Lock 和 RLock 对象实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于每次只允许一个线程操作的资源,可以将该资源放到 acquire 和 release 方法之间。
对于 Lock 对象,如果一个线程连续两次进行 acquire 操作,那么由于第一次 acquire 没有 release,第二次 require 将挂起线程,这会导致 Lock 对象永远不会 release,使得线程死锁。
RLock 对象允许一个线程多次对其进行 acquire 操作,因为在其内部通过一个变量 counter 维护线程 acquire 的次数,而且每一次的 acquire 操作必须有一个 release 操作与之对应,在所有的 release 操作完成后,别的线程才能申请该 RLock 对象。
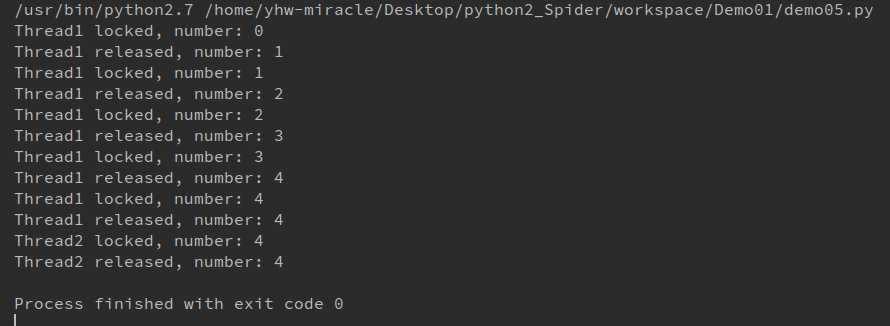
1 import threading, time 2 3 myLock = threading.RLock() 4 num = 0 5 6 7 class MyThread(threading.Thread): 8 def __init__(self, name): 9 threading.Thread.__init__(self, name=name)10 11 def run(self):12 global num13 while True:14 myLock.acquire()15 16 print(‘%s locked, number: %d‘ % (threading.current_thread().name, num))17 if num >= 4:18 myLock.release()19 print(‘%s released, number: %d‘ % (threading.current_thread().name, num))20 break21 num += 122 print(‘%s released, number: %d‘ % (threading.current_thread().name, num))23 24 time.sleep(1)25 26 myLock.release()27 28 29 if __name__ == ‘__main__‘:30 thread1 = MyThread(‘Thread1‘)31 thread2 = MyThread(‘Thread2‘)32 33 thread1.start()34 thread2.start()
3. 小结
在 python 的原始解释器中存在着 GIL(Global Interpreter Lock,全局解释器锁),因此在解释执行 python 代码时,会产生互斥锁来限制线程对共享资源的访问,直到解释器遇到 I/O 操作或者操作次数达到一定数目时才会释放 GIL。由于全局解释器锁的存在,在进行多线程操作时,不能调用多个 CPU 内核,只能利用一个内核,所以在进行 CPU 密集型操作的时候,不推荐使用多线程,更倾向于多进程;对于 IO 密集型操作,多线程可以明显提高效率。
python之多线程
评论关闭