python多线程爬虫+批量下载斗图啦图片项目(关注、持续更新),,python多线程爬
python多线程爬虫+批量下载斗图啦图片项目(关注、持续更新),,python多线程爬
python多线程爬虫项目()
爬取目标:斗图啦(起始url:http://www.doutula.com/photo/list/?page=1)
爬取内容:斗图啦全网图片
使用工具:requests库实现发送请求、获取响应。
xpath实现数据解析、提取和清洗
threading模块实现多线程爬虫
爬取结果:
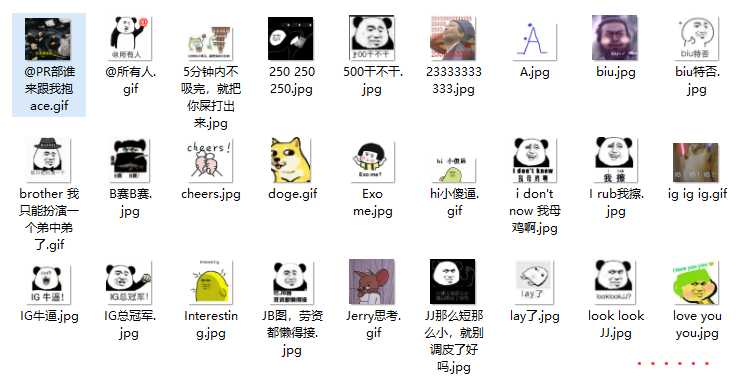
思路:由于该爬虫存在网络密集IO和磁盘密集IO,存在大量等待时间,遂采用多线程方式爬取。
设计:本文采用多为结构化代码的面向对象封装设计思路,使用生产消费者模型,完成多线程的调度、爬取。
直接放代码(详细说明在注释里,欢迎同行相互交流、学习~):
1 import os 2 import threading 3 import re 4 from queue import Queue 5 import requests 6 from urllib import request 7 from lxml import etree 8 9 # 定义一个全局变量,存储请求头headers数据10 headers = {11 "User-Agent": "Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)"12 }13 14 class Producter(threading.Thread):15 """16 生产者模型:负责从起始url队列中提取url,进行解析,将得到的图片地址放入img图片队列中17 """18 def __init__(self, page_queue, img_queue, *args, **kwargs):19 # 改写父类threading.Thread的__init__方法,添加默认值20 super(Producter, self).__init__(*args, **kwargs)21 # 添加对象属性22 self.page_queue = page_queue23 self.img_queue = img_queue24 25 def run(self):26 """27 实现消费者模型的主要业务逻辑28 """ 29 while True:30 # 当请求队列为空,生产者停止生产31 if self.page_queue.empty():32 break33 # 获取起始url队列的对象,进行页面解析34 url = self.page_queue.get()35 self.parse_url(url)36 37 def parse_url(self, url):38 """39 实现解析指定页面的功能40 :param url: 传入待处理的页面url41 """42 response = requests.get(url=url, headers=headers)43 html = etree.HTML(response.text)44 # 使用lxml库里HTML解析器进行数据解析,利用xpath语法解析得到指定数据,返回一个element对象列表45 url_gifs = html.xpath("//div[@class=‘page-content text-center‘]//img[@class!=‘gif‘]")46 for url_gif in url_gifs:47 # element.get(属性名)可以获取属性值48 url_name = url_gif.get("alt")49 # 正则表达式替换非法字符50 url_name = re.sub(r"[\!!\.\??]", "", url_name).strip()51 url_link = url_gif.get("data-original")52 # os模块中os.path.splitext()可以获取url的后缀名53 url_suffix = os.path.splitext(url_link)[1]54 filename = url_name + url_suffix55 # 队列的put()里面传的是元组或者列表56 self.img_queue.put((url_link, filename)) 57 58 class Consumer(threading.Thread):59 """60 消费者模型的主要业务逻辑61 """62 63 def __init__(self, page_queue, img_queue, *args, **kwargs):64 super(Consumer, self).__init__(*args, **kwargs)65 self.page_queue = page_queue66 self.img_queue = img_queue67 68 def run(self):69 """70 实现读取图片url内容的功能71 """72 while True:73 if self.page_queue.empty() and self.img_queue.empty():74 break75 url, filename = self.img_queue.get()76 # urllib库里面的request模块可以读取图片url内容77 request.urlretrieve(url, "GIF/" + filename)78 # 控制台输出提示信息79 print(filename + "-------下载完成!")80 81 def main():82 # 创建page队列,存放请求的起始url;创建img队列,存放图片data的url83 page_queue = Queue(100) # 设置队列的最大存储数量84 img_queue = Queue(1000) # 设置队列的最大存储数量85 for i in range(100):86 start_url_format = "http://www.doutula.com/photo/list/?page={}".format(i)87 # print(start_url_format) #调试代码用88 page_queue.put(start_url_format) #将获取的起始url放入队列中89 # 生成多线程对象(多个生产者、消费者)。实现发送请求,获取响应,解析页面,获取数据90 for i in range(10):91 t = Producter(page_queue, img_queue)92 t.start()93 for i in range(10):94 t = Consumer(page_queue, img_queue)95 t.start()96 97 if __name__ == ‘__main__‘:98 main()python多线程爬虫+批量下载斗图啦图片项目(关注、持续更新)
评论关闭