python+selenium获取禅道所有Bug标题,,前言:对于一组很多的
python+selenium获取禅道所有Bug标题,,前言:对于一组很多的
前言:
对于一组很多的数据,一个页面加载不完,需要分页加载,比如禅道的Bug数,一页默认是20个(自己可以根据需求更改),这时就有了第二页,第三页等等。
这时如果要获取所有的Bug标题来怎么做呢?
点击下一页Bug,你会发现url的变化,就只有最后一个数字改变,如下图:
![]()
![]()
大体思路:
获取所有url→ddt驱动获取每一页的数据
步骤:
第一步:获取所有url
这里已经显示了总共有几页和当前所在的页面数,我们要获取的就后面的数字 ‘3’。
先定位到这个元素,在通过正则取出后面的 ‘3’,具体代码如下:
![]()
b=self.driver.find_element_by_xpath(".//*[@id=‘bugList‘]/tfoot/tr/td/div[2]/div/strong[2]")page=re.findall(r‘/(.+?)‘,b.text)total_page=page[0]print(‘总共的页数:‘,total_page)接下来就是要用到range函数了,获取所有的url地址了,代码如下:
for i in range(1,int(total_page)+1): Url=url+‘/zentao/bug-browse-1--unclosed-0--60-20-%s.html‘ % i print(Url)
最后控制台输出如下:
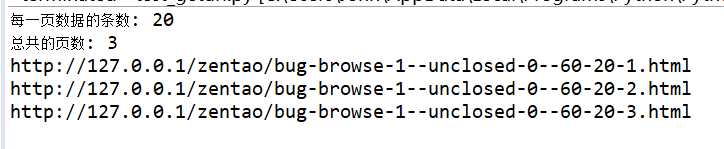
观察下,是不是只有后面的1,2,3在跟着变,其他无任何变化,这时就可以将这些url添加到一个list中去,用做接下来的ddt驱动的数据了
具体代码如下:
#coding:utf-8from selenium.webdriver.firefox.webdriver import WebDriver as Firefoximport re,timefrom selenium.webdriver.support.ui import WebDriverWaitclass GetUrl(): ‘‘‘获取所有URL页面‘‘‘ def get_url(self,url,username,psw): self.driver=Firefox() self.driver.maximize_window() self.driver.set_page_load_timeout(20) self.driver.implicitly_wait(20) self.driver.get(url+‘/zentao/user-login-L3plbnRhby8=.html‘) #输入网址 WebDriverWait(self.driver,20,1).until(lambda x:x.find_element_by_id("account")).send_keys(username) #输入账号 WebDriverWait(self.driver,20,1).until(lambda x:x.find_element_by_name("password")).send_keys(psw) #输入密码 WebDriverWait(self.driver,20,1).until(lambda x:x.find_element_by_id(‘submit‘)).click() #点击登录按钮 time.sleep(2) self.driver.find_element_by_xpath(".//*[@id=‘mainmenu‘]/ul/li[4]/a").click() time.sleep(2) self.driver.find_element_by_xpath(".//*[@id=‘modulemenu‘]/ul/li[2]/a").click() time.sleep(2) table=self.driver.find_element_by_id(‘bugList‘) #获取到bugList这个表格 table_rows=table.find_elements_by_tag_name(‘tr‘) #获取行数 print((‘每一页数据的条数:‘),(len(table_rows)-2)) #这里减2是减去表格最上面和最下面那行 b=self.driver.find_element_by_xpath(".//*[@id=‘bugList‘]/tfoot/tr/td/div[2]/div/strong[2]") #定位到页面显示总页数那个元素(1/3) page=re.findall(r‘/(.+?)‘,b.text) #通过正则取出后面那个总页数(也就是那个3) total_page=page[0] print(‘总共的页数:‘,total_page) a=[] #创建空list去接收生成的url for i in range(1,int(total_page)+1): Url=url+‘/zentao/bug-browse-1--unclosed-0--60-20-%s.html‘ % i a.append(Url) print(a) self.driver.close() return aif __name__==‘__main__‘: url=‘http://127.0.0.1‘ username=‘admin‘ psw=‘123456‘ a=GetUrl() a.get_url(url,username,psw)第二步:编写另一个类来执行
1.导入第一步的url结果
2.添加ddt驱动
3.将结果写入TXT中
具体代码如下:
#coding:utf-8import unittestimport ddtimport timefrom com.Practice.test_geturl import GetUrlfrom selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaiturl=‘http://127.0.0.1‘username=‘admin‘psw=‘123456‘test_url=GetUrl().get_url(url,username,psw)@ddt.ddtclass Test(unittest.TestCase): ‘‘‘获取所有Bug标题‘‘‘ @ddt.data(*test_url) def test_01(self,test_url): self.driver = webdriver.Firefox() self.driver.get(‘http://127.0.0.1/zentao/user-login-L3plbnRhby8=.html‘) WebDriverWait(self.driver,20,1).until(lambda x:x.find_element_by_id("account")).send_keys(‘admin‘) WebDriverWait(self.driver,20,1).until(lambda x:x.find_element_by_name("password")).send_keys(‘123456‘) WebDriverWait(self.driver,20,1).until(lambda x:x.find_element_by_id(‘submit‘)).click() time.sleep(1) self.driver.get(test_url) a=self.driver.find_elements_by_xpath(".//*[@id=‘bugList‘]/tbody/tr/td[4]/a") for i in a: print(i.text) try: with open(‘zendao.txt‘,‘a‘) as f: f.write(i.text+‘\n‘) except Exception as msg: print(‘写入时出错啦:%s‘ % msg) time.sleep(1) def tearDown(self): self.driver.close()if __name__==‘__main__‘: unittest.main()这里获取文本信息是通过table定位获取。
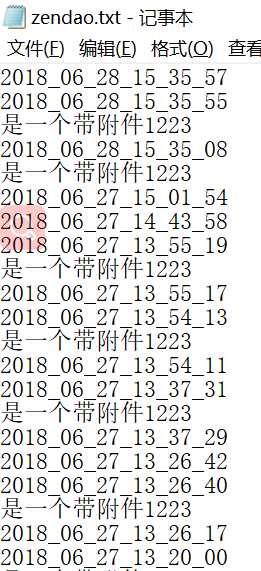
最后TXT打印结果(没截全):
![]()
![]()
这个是一个优惠券生成的网址,也是分页显示,原理和上面大体相同。
结语:
这个有点麻烦,应该还有更简单的方法。只可惜小白一枚,能力不足,暂时就只能先这样做了,欢迎大家提意见!!!
python+selenium获取禅道所有Bug标题
评论关闭