python中re正则表达式,,1、re匹配的语法r
python中re正则表达式,,1、re匹配的语法r
1、re匹配的语法
re.math 从头开始匹配,没有匹配到返回None
re.seach 匹配包含,,没有匹配到返回None
re.findall 把所有匹配到的字符,以列表的形式返回,没有匹配到返回空列表[]
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
re.fullmath 全部匹配
s=‘adds231f‘print(re.match("[0-9]",s))print(re.search("[0-9]",s))print(re.findall("[0-9]",s))结果:None<_sre.SRE_Match object; span=(4, 5), match=‘2‘>[‘2‘, ‘3‘, ‘1‘]***注意****
match和search一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
group() 返回被 RE 匹配的字符串
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串
math、seach匹配到后返回的是一个对象,若要获取匹配到的值要取greap()
s=‘rasfd23fd5‘m=re.match("[0-9]",s)ss=re.search("[0-9]",s)if m: print("math方法:"+m.group())if ss: print("search方法:"+ss.group())结果:search方法:22、re常用表达式公式
‘.‘ 匹配除\n以外的任意一个字符(从左开始),2个 ‘.’ 就匹配2个字符
s=‘rasfd23fd5‘print(re.search(‘.‘,s).group())print(re.search(‘..‘,s).group())结果:rra
‘ ^‘匹配字符串开头。在多行模式中匹配每一行的开头
print(re.search(‘^r‘,‘rasfd23fd5‘)) print(re.match(‘r‘,‘rasfd23fd5‘))print(re.search(‘^rs‘,‘rasfd23fd5‘))结果:<_sre.SRE_Match object; span=(0, 1), match=‘r‘><_sre.SRE_Match object; span=(0, 1), match=‘r‘>None
‘$‘匹配字符串末尾,在多行模式中匹配每一行的末尾
print(re.search(‘d$‘,‘rasfdg‘))print(re.search(‘g$‘,‘rasfdg‘))结果:None<_sre.SRE_Match object; span=(5, 6), match=‘g‘>
‘*‘匹配前一个字符0或多次
print(re.search(‘a*‘,‘rarrdrg‘)) #要匹配a开关print(re.search(‘rar*‘,‘rarardrg‘))print(re.search(‘rar*‘,‘rarrdrg‘))print(re.search(‘rar*‘,‘rarrrdrg‘)) #匹配ra,rar,rarr,rarr,rarrr......等结果:<_sre.SRE_Match object; span=(0, 0), match=‘‘><_sre.SRE_Match object; span=(0, 3), match=‘rar‘><_sre.SRE_Match object; span=(0, 4), match=‘rarr‘><_sre.SRE_Match object; span=(0, 5), match=‘rarrr‘>
‘+‘匹配前一个字符1或多次
print(re.search(‘a+‘,‘rarrdrg‘)) print(re.search(‘rar+‘,‘sraardrg‘))print(re.search(‘rar+‘,‘srardrg‘))print(re.search(‘rar+‘,‘srarrdrg‘))print(re.search(‘rar+‘,‘srarrrdrg‘))结果:<_sre.SRE_Match object; span=(1, 2), match=‘a‘>None<_sre.SRE_Match object; span=(1, 4), match=‘rar‘><_sre.SRE_Match object; span=(1, 5), match=‘rarr‘><_sre.SRE_Match object; span=(1, 6), match=‘rarrr‘>
‘?‘ 匹配前一个字符1或0次
print(re.search(‘rar?‘,‘sraardrg‘))print(re.search(‘rar?‘,‘srardrg‘))print(re.search(‘rar?‘,‘srarrdrg‘))print(re.search(‘rar?‘,‘sarrdrg‘))结果:<_sre.SRE_Match object; span=(1, 3), match=‘ra‘><_sre.SRE_Match object; span=(1, 4), match=‘rar‘><_sre.SRE_Match object; span=(1, 4), match=‘rar‘>None
‘{m}匹配前一个字符m次
print(re.search(‘a{2}‘,‘sraardrg‘))print(re.search(‘a{2}‘,‘srarardrg‘))结果:<_sre.SRE_Match object; span=(2, 4), match=‘aa‘>None‘{n,m}匹配前一个字符n到m次
print(re.search(‘a{1,2}‘,‘sraardrg‘))print(re.search(‘a{1,2}‘,‘srarardrg‘))print(re.search(‘a{1,2}‘,‘sraaardrg‘))结果:<_sre.SRE_Match object; span=(2, 4), match=‘aa‘><_sre.SRE_Match object; span=(2, 3), match=‘a‘><_sre.SRE_Match object; span=(2, 4), match=‘aa‘>‘|‘ 匹配|右边或左边的字符
print(re.search(‘ar|dr‘,‘sraardrg‘))print(re.search(‘ar|dr‘,‘srdddrdrg‘))结果:<_sre.SRE_Match object; span=(3, 5), match=‘ar‘><_sre.SRE_Match object; span=(4, 6), match=‘dr‘>
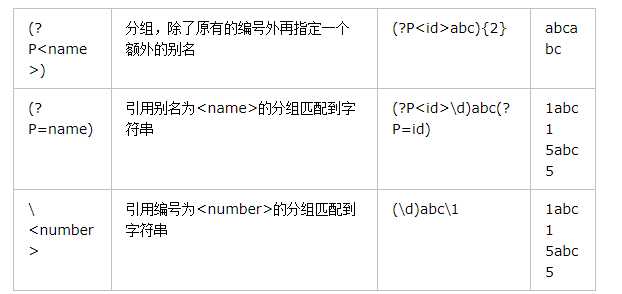
‘(....)’ 分组匹配,
被括起来的表达式将作为分组,从表达式左边开始没遇到一个分组的左括号“(”,编号+1.
分组表达式作为一个整体,可以后接数量词。表达式中的|仅在该组中有效。
k=re.search(‘([A-z]+)([0-9]+)‘,‘Terry913‘)k_group =k.group()k_groups =k.groups()print(k_group) #-->Terry913print(k_groups) #->(‘Terry‘, ‘913‘)
反斜杠\的作用:
反斜杠后边跟元字符去除特殊功能;(即将特殊字符转义成普通字符)
反斜杠后边跟普通字符实现特殊功能;(即预定义字符)
引用序号对应的字组所匹配的字符串。
\w | 匹配字母数字及下划线 |
\W | 匹配非字母数字及下划线 |
\s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
\S | 匹配任意非空字符 |
\d | 匹配任意数字,等价于 [0-9]. |
\D | 匹配任意非数字 |
\A | 匹配字符串开始 |
\Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
\z | 匹配字符串结束 |
\G | 匹配最后匹配完成的位置。 |
\b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b‘ 可以匹配"never" 中的 ‘er‘,但不能匹配 "verb" 中的 ‘er‘。 |
\B | 匹配非单词边界。‘er\B‘ 能匹配 "verb" 中的 ‘er‘,但不能匹配 "never" 中的 ‘er‘。 |
3 特殊分组
python中re正则表达式
相关内容
- Python中list的功能介绍,, List的功能介绍
- python数据类型,,方法字符串:strt
- -bash: /usr/bin/yum: /usr/bin/python: bad interpreter: No such file o
- python—mysql数据库读取表1获取name作为参数,传入访问表
- python map、join函数,,map()会根据提供
- Python爬虫爬取数据的步骤,,爬虫: 网络爬虫是
- python的pandas库读取csv,,首先建立test.c
- 利用Python编写一个会员管理系统,沉迷于编程的世界里
- centos7安装Python3,,1、安装前准备cen
- anaconda下安装pytorch,,anaconda下安
评论关闭