爬虫——json、jsonpath、xpath模糊查询,,发现一个问题,之前爬
爬虫——json、jsonpath、xpath模糊查询,,发现一个问题,之前爬
发现一个问题,之前爬的内容写入文件的方式错了,应该是“wb"! 啊,居然才发现,太蠢了!

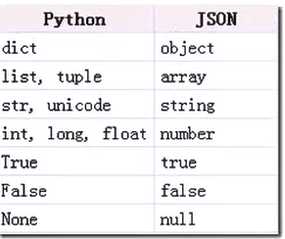
json.dump() : 将python内置类型序列转化为python对象后写入文件
json.load() : 将json形式的字符串元素转化成python类型
import urllib.requestimport jsonimport jsonpathurl = "https://www.lagou.com/lbs/getAllCitySearchLabels.json"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"}request = urllib.request.Request(url, headers=headers)html = urllib.request.urlopen(request).read()# html.decode("utf-8")# html = bytes(html, encoding="utf-8")# html = html.decode("gbk")with open("lagou.txt","wb") as f: f.write(html)# 把json形式的字符串转换成python形式的Unicode字符串unicodestr = json.loads(html)city_list = jsonpath.jsonpath(unicodestr, "$..name")for item in city_list: print(item)# dumps()默认中文为ascii编码格式# dumps直接操作,返回Unicode字符串array = json.dumps(city_list, ensure_ascii=False)with open("lagou.json","wb") as f: # unicode转化为utf-8 f.write(array.encode("utf-8"))xpath模糊查询:
//div[contains(@要查找的标签或者属性名,要匹配的字符串)]
爬虫——json、jsonpath、xpath模糊查询
相关内容
- Django admin 后台操作数据库以问卷调查为例,,Django的后
- windows7,python3使用time.strftime()函数报ValueError: embedded
- python爬取opgg的LOL英雄数据,,完整源码链接:htt
- python xpath 爬取豆瓣电脑版电影案例,,from lxml
- python-找出100以内的质数,,质数:就是只能被1和
- 【python】爬取糗事百科段子,,#-*-coding
- python 删除2天前后缀为.log的文件,,python脚本 删
- 7-45 jmu-python-涨工资 (10 分),,输入一组工资数据,写
- 窦小凤2020寒假学习心得,,2020年1-2月寒
- urllib:简单的贴吧页面爬取代码,,from urlli
评论关闭