python与冒泡排序,,上一篇文章,介绍了一
python与冒泡排序,,上一篇文章,介绍了一
上一篇文章,介绍了一个非常快的排序算法--桶排序,但是它的缺点就是太耗资源了,这次要实现的算法就不用太耗资源了,它就是冒泡排序。
问题提出:
将以下数据升序排列:9, 2, 8, 6, 4
冒泡排序原理:
冒泡排序就是遍历数据,每次只与下一个数字比较,如果这两个数顺序不对,则与交换过来。
就上面那个问题来说,因为要升序排列,所以数字越大越排在后面。则两个数比较的时候,如果后一个数比当前数小,则顺序不对,要将这两个数交换。遍历的过程如下图:
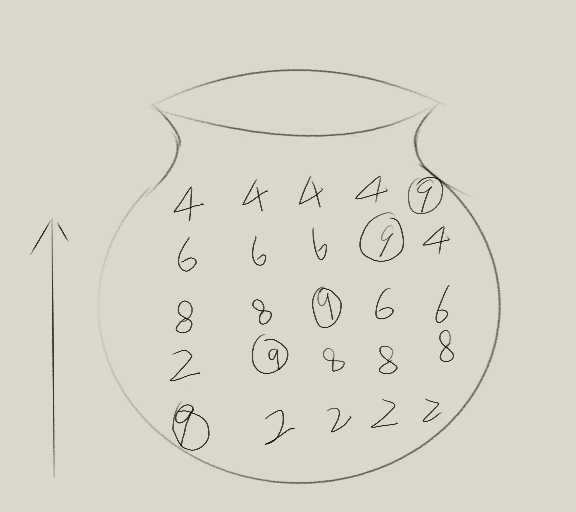
第一次比较第一和第二个数字,9与2相比较,9比2大,顺序不对,则交换位置。
第二次比较第二与第三个数字,因为9换到了第二位,则9与8比较,9大,顺序不对,则交换位置。
以此类推,最后9就像泡泡一样升到了最后一位,我们称这样为一趟,这一趟里面有多次比较。
由于一趟只归为一个数,则如果有n个数字,则需要进行n-1趟。
因为归位后的数字不用再比较了,所以每趟只需要比较n-1-i次(i为已执行的趟数)。
由上可以得出冒泡排序的关键步骤是两个循环:
1 for(i = 0; i < n-1; i++){2 for(j = 0; j < n-1-i; j++)3 if(a[j] > a[j+1]){4 temp = a[j];5 a[j] = a[j+1];6 a[j+1] = temp;7 }8 } python实现:
根据上述思路,用python实现也是把关键地方实现即可:
1 #假设变量已经全部定义好2 for i in range(len-1):3 for j in range(len-1-i):4 if a[j] > a[j+1]:5 a[j], a[j+1] = a[j+1], a[j]
以下是完整代码:(可以到github上下载https://github.com/DIGCreat/pythonAndAlgorithms.git)
1 #!/usr/bin/env python 2 # -*- coding:utf8 -*- 3 ‘‘‘ 4 简介:本程序主要是用python实现冒泡排序,程序的功能是实现 5 降序排列。 6 7 作者:King 日期:2016/08/01 版本1 8 ‘‘‘ 9 10 class BubbleSort(object):11 ‘‘‘12 self.datas: 要排序的数据列表13 self.datas_len: 数据急的长度14 _sort(): 排序函数15 show(): 输出结果函数16 17 用法:18 BubbleSort(datas) 实例化一个排序对象19 BubbleSort(datas)._sort() 开始排序,由于排序直接操作20 self.datas, 所以排序结果也21 保存在self.datas中22 BubbleSort(datas).show() 输出结果23 ‘‘‘24 def __init__(self, datas):25 self.datas = datas26 self.datas_len = len(datas)27 28 def _sort(self):29 #冒泡排序要排序n个数,由于每遍历一趟只排好一个数字,30 #则需要遍历n-1趟,所以最外层循环是要循环n-1次,而31 #每次趟遍历中需要比较每归位的数字,则要在n-1次比较32 #中减去已排好的i位数字,则第二层循环要遍历是n-1-i次33 for i in range(self.datas_len-1):34 for j in range(self.datas_len-1-i):35 if(self.datas[j] < self.datas[j + 1]):36 self.datas[j], self.datas[j+1] = 37 self.datas[j+1], self.datas[j]38 39 def show(self):40 print ‘Result is:‘,41 for i in self.datas:42 print i,43 print ‘‘44 45 if __name__ == ‘__main__‘:46 try:47 datas = raw_input(‘Please input some number:‘)48 datas = datas.split()49 datas = [int(datas[i]) for i in range(len(datas))]50 except Exception:51 pass52 53 bls = BubbleSort(datas)54 bls._sort()55 bls.show()
总结:
冒泡排序因为是在原数组上直接操作,所以它占的空间资源较少,在数据量不大的情况还是挺好的。但是由于算法涉及双重循环,所以在数据量大的情况下,程序运行的时间是相当长的,因为要一次一次地遍历数据。
最后有兴趣的同学可以关注我的微信公众号,可以随时及时方便看我的文章。*^_^*
扫码关注或者搜索微信号:King_diary

python与冒泡排序
相关内容
- 暂无相关文章
评论关闭