Python 开发简单爬虫 - 基础框架,,1. 目标:开发轻量
Python 开发简单爬虫 - 基础框架,,1. 目标:开发轻量
1. 目标:开发轻量级爬虫(不包括需登陆的 和 Javascript异步加载的)
不需要登陆的静态网页抓取
2. 内容:
2.1 爬虫简介
2.2 简单爬虫架构
2.3 URL管理器
2.4 网页下载器(urllib2)
2.5 网页解析器(BeautifulSoup)
2.6 完整实例:爬取百度百科Python词条相关的1000个页面数据
3. 爬虫简介:一段自动抓取互联网信息的程序
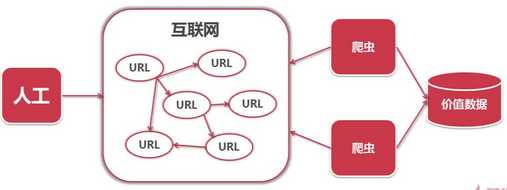
爬虫价值:互联网数据,为我所用。
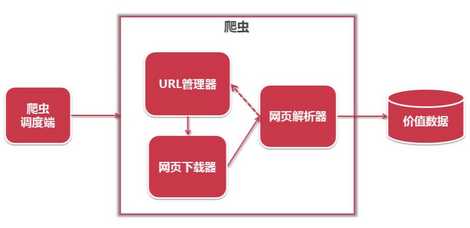
4. 简单爬虫架构:
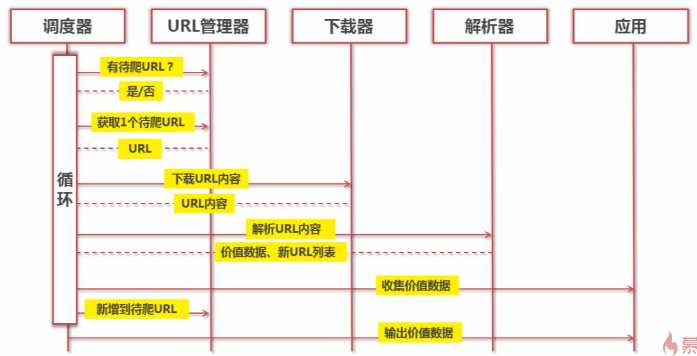
运行流程:
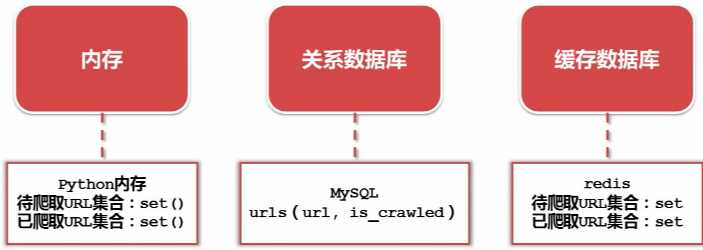
5. URL管理器:管理待抓取URL集合 和 已抓取URL集合
- 防止重复抓取、防止循环抓取
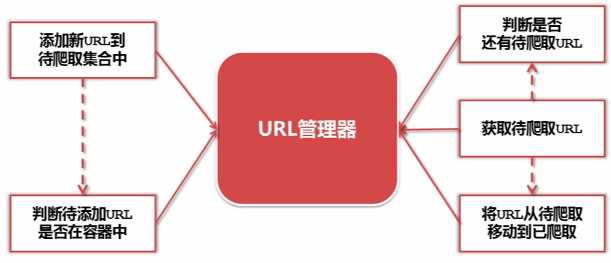
- 实现方式:
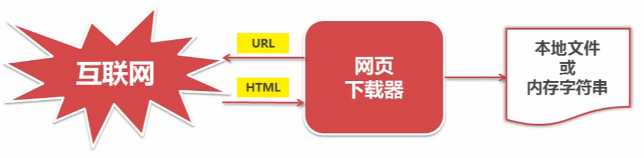
6. 网页下载器:将互联网URL对应的网页下载到本地的工具
- 分类:
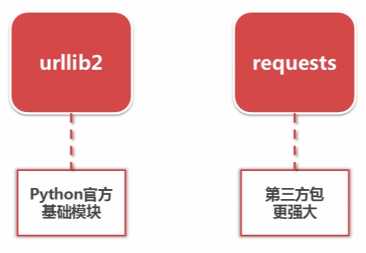
- urllib2 下载网页的方法:
1. 最简洁方法: url ===> urllib2.urlopen(url)
import urllib2# 直接请求response = urllib2.urlopen(‘http://www.baidu.com‘)# 获取状态码,如果是200表示获取成功print response.getcode()# 读取内容cont = response.read()
2. 添加data、http header: (url,data,header) ===> urllib2.Request ===> urllib2.urlopen(request)
import urllib2# 创建Request对象request = urllib2.Request(url)# 添加数据request.add_data(‘a‘, ‘1‘)# 添加http的headerrequest.add_header(‘User-Agent‘, ‘Mozilla/5.0‘)# 发送请求获取结果response = urllib2.urlopen(request)
3. 添加特殊情景的处理器:
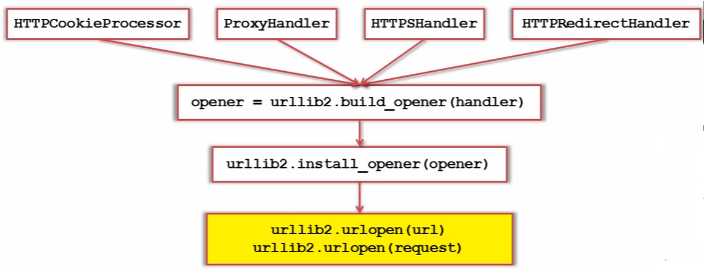
import urllib2, cookielib# 创建cookie容器cj = cookielib.CookieJar()# 创建1个openeropener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))# 给urllib2安装openerurllib2.install_opener(opener)# 使用带有cookie的urllib2访问网页response = urllib2.urlopen(“http://www.baidu.com/”)
7. urllib2 实例代码演示:
# -*- coding: utf-8 -*-"""Created on Tue Feb 14 10:31:06 2017@author: Wayne"""import urllib2, cookieliburl = "http://www.baidu.com"print "the 1st method"response1 = urllib2.urlopen(url)print response1.getcode()print len(response1.read())print "the 2nd method"request = urllib2.Request(url)request.add_header("user-agent", "Mozilla/5.0")response2 = urllib2.urlopen(request)print response2.getcode()print len(response2.read())print "the 3rd method"cj = cookielib.CookieJar()opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))response3 = urllib2.urlopen(url)print response3.getcode()print cjprint response3.read()8. 网页解析器:从网页中提取有价值数据的工具
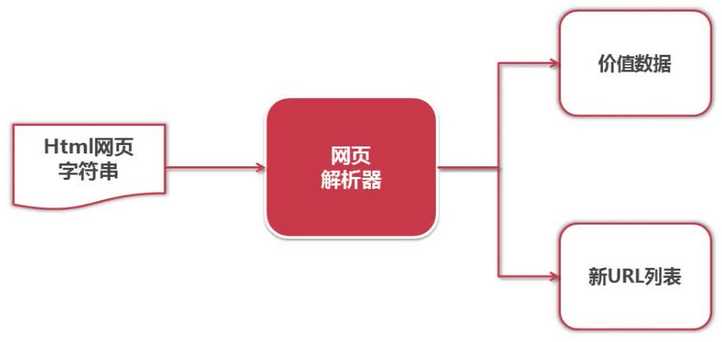
python 的网页解析器:
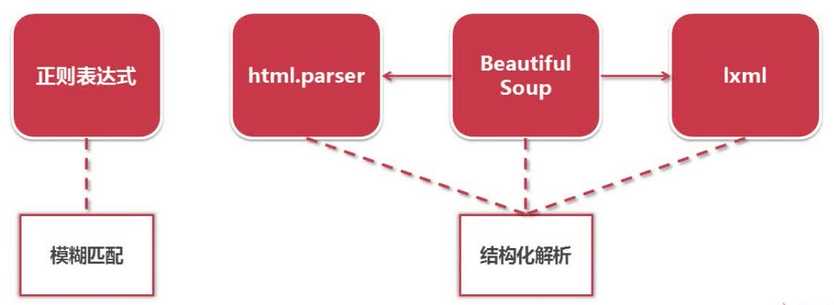
结构化解析 - DOM ( Document Object Model) 树:
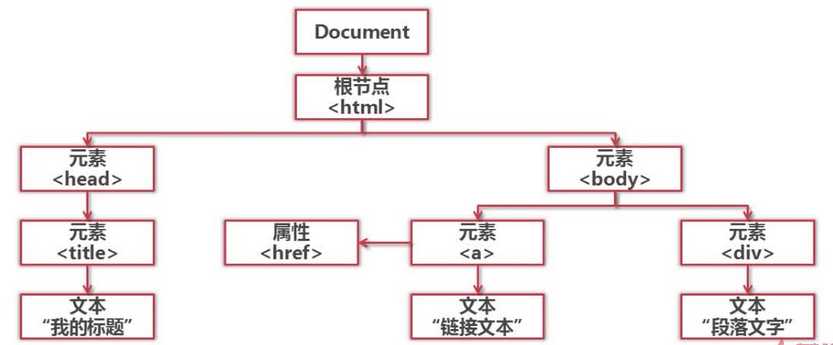
9. 网页解析器 - Beautiful Soup
9.1 Beautiful Soup
- Python 第三方库,用于从HTML或XML中提取数据
- 官网:http://www.crummy.com/software/BeautifulSoup
9.2 安装并测试 beautifulsoup4
- 安装:pip install beautifulsoup4
- 测试:import bs4
9.3 Beautiful Soup语法
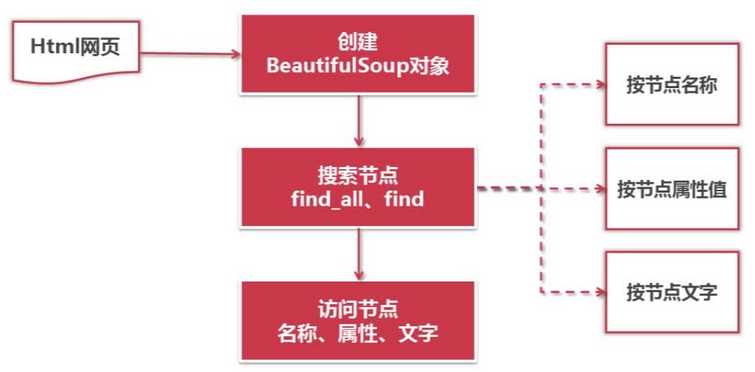

9.4 创建 BeautifulSoup 对象
from bs4 import BeautifulSoup# 根据 HTML 网页字符串创建 BeautifulSoup 对象soup = BeautifulSoup( html_doc, # HTML文档字符串 ‘html.parser‘ # HTML解析器 from_encoding=‘utf-8‘ # HTML文档的编码 )
9.5搜索节点(find_all, find)
# 方法:find_all(name, attrs, string)# 查找所有标签为 a 的节点soup.find_all(‘a‘)# 查找所有标签为 a,链接符合 /view/123.htm 形式的节点soup.find_all(‘a‘, href=‘/view/123.htm‘)soup.find_all(‘a‘, href=re.compiler(r‘/view/\d+\.htm‘))# 查找所有标签为div, class为abc,文字为Python的节点soup.find_all(‘div‘, class_=‘abc‘, string=‘Python‘)
9.6访问节点信息
# 得到节点: <a href=‘1.html‘>Python</a># 获取查找到的节点的标签名称node.name# 获取查找到的a节点的href属性node[‘href‘]# 获取查找到的a节点的链接文字node.get_text()
10. BeautifulSoup 实例测试
# -*- coding: utf-8 -*-"""Created on Tue Feb 14 11:00:42 2017@author: Wayne"""from bs4 import BeautifulSoupimport rehtml_doc = """<html><head><title>The Dormouse‘s story</title></head><body><p class="title"><b>The Dormouse‘s story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>"""soup = BeautifulSoup(html_doc, ‘html.parser‘, from_encoding=‘urf-8‘)print ‘\n## Get all the links‘links = soup.find_all(‘a‘)for link in links: print link.name, link[‘href‘], link.get_text() print ‘\n## Get the links include "lacie"‘link_node = soup.find(‘a‘, href=‘http://example.com/lacie‘)print link_node.name, link_node[‘href‘], link_node.get_text()print ‘\n## RE matching‘link_node = soup.find(‘a‘, href=re.compile(r"ill"))print link_node.name, link_node[‘href‘], link_node.get_text()print ‘\n## Get "P" Paragraph Text‘p_node = soup.find(‘p‘, class_=‘title‘)print p_node.name, p_node.get_text()
Python 开发简单爬虫 - 基础框架
评论关闭