python 入门学习 载抄,,python入门解释
python 入门学习 载抄,,python入门解释
python入门
解释型语言 和编译型语言
计算机本身不能识别高级语言,当我们运行一个程序的时候,需要一个“翻译” 来把 高级语言转换成计算机能读懂的语言。 “翻译”过程分两种:
编译 编译型语言在执行程序前,首先会通过编译器执行一个编译的过程,把程序编译成机器语言。 之后,程序再次运行的时候,就不要“翻译”了,而是可以直接执行。比如C语言。 编译型语言的优点在于在运行程序的时候不用解释,可直接利用已经翻译过的文件。解释 解释型语言就没有编译的过程,而是在程序运行的时候,通过解释器逐行解释代码,然后运行。比如python。java等基于虚拟机的语言兴起之后,编程语言又不能单纯的在划分为编译型语言或解释型语言。 java是首先通过编译器将代码编译成字节码文件,然后在JVM执行java字节码,将其解释成机器语言。 所以我们说java是一种半编译半解释的语言。
C#,在第一次执行的时候,将代码编译成IL中间码文件,然后由JIT编译器编译成本地的机器码执行。 相当于编译了两次。
关于python,看下面详解。
第一个python程序
首先我们打开python 交互式解释器, 执行如下命令:

1 # python3 2 Python 3.5.1+ (default, Mar 30 2016, 22:46:26)3 [GCC 5.3.1 20160330] on linux4 Type "help", "copyright", "credits" or "license" for more information.5 >>> print("Hello World")6 Hello World然后我们 写一个最简单的python程序。 新建 first.py文件,文件内容如下:
1 print("First Hello World!")新建 second.py
import firstprint("Second Hello World!")然后我们喜欢执行第二个文件:
python second.py
输出:
First Hello World!Second Hello World!
python程序的执行过程
这个时候我们会发现生成了一个 pycache 目录; 目录下 有文件first.cpython-35.pyc。 如果python版本是2.x 则会在当前目录直接生成first.pyc。 我们说python是解释型语言 ,那这个pyc是什么文件呢? 按照一般的理解来说,pyc 中的c 应该是compile的意思, 既然是这样,那么python代码是如何被转换成一系列的机器指令呢?现在我们就好好深究一下这里的因果关系。 其实本质上python和java、C#是一样的,三者的 程序执行原理都可以用两个词概括——虚拟机、字节码。 在python中有一个非常核心的东西——interpreter,当我们在命令行敲入python,当我们在shell中敲入命令python的时候, 目的就是为了激活这个解释器; 当我们执行 python second.py的时候,python解释器立即被激活,然后执行python程序。在pyhton的解释器还要完成一个非常重要的工作——编译.py文件。
python解释器在执行程序的时候,首先就是对文件中的python源代码进行编译,生成一个python的字节码(byte code),然后 将字节码交给python虚拟机,虚拟机则按照顺序一条一条的执行字节码,直到程序执行完。 上面在执行python second.py时,我们发现只有second.py文件生成了pyc文件,原因我们不知道,但是我们可以猜测python在执行的时候,只对需要编译的文件进行编译。那什么是需要编译的文件呢? 比如说,first.py文件不只被 second.py调用, 还被其他的py文件调用,这个时候,如果把 first.py 进行编译,那下次就直接调用编译后的pyc文件,这样就加快了执行速度。
那么有人就要问了,如果我修改了first.py文件,下次调用first.pyc的时候不就不是最新的代码了吗,对于这个我们并不需要担心。pyc文件中包含自身创建的时间,在python程序执行的时候,首先会尝试加载pyc文件,在加载的过程中,python会比对py文件和 pyc文件的时间,如果pyc文件时间早于py文件时间,就会重新编译py文件,生成新的pyc文件, 否则就会直接调用py从文件。
python整体架构
了解了python程序的执行过程,那么也应该了解python的整体架构是什么。 python的整体架构可以分为三个主要的部分。
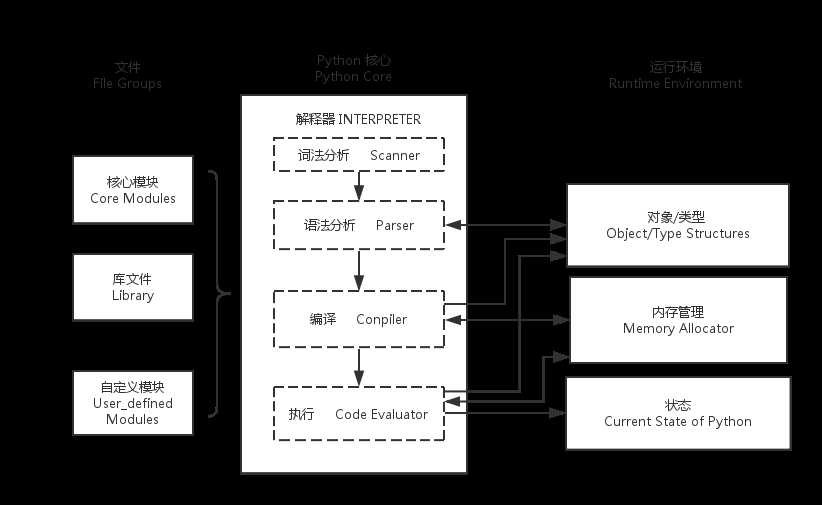
python程序文件头部的 #!
#!/usr/bin/env python print("Hello World!")Shebang 是一个由井号和叹号构成的字符串行(#!), 其出现在文本文件的第一行的前两个字符. 在文件中存在Shebang的情况下, 类Unix操作系统的程序载入器会分析Shebang后的内容, 将这些内容作为解释器指令, 并调用该指令, 并将载有Shebang的文件路径作为该解释器的参数。#!先用于帮助内核找到Python解释器, 但是在导入模块时, 将会被忽略. 因此只有被直接执行的文件中才有必要加入#!.
文件编码
什么是文件编码 (了解的可忽略)
我们在显示器看见的文字图片等信息在电脑上存储的时候并不是我们看到的样子。如果你拆开硬盘,把里面的盘片拿出来用显微镜来看就会看到上面有很多凹凸的地方。和我们平时见到的光盘类似。凹凸的位置分别表示0和1。这是因为在电脑中电信号只有两种状态,有电和没电。在存储数据的时候,如果我们要保存一个字母“A”,那么就可以用一定长度的0和1来表示。比如说用“01000001”来表示A。有了这样的对应关系,我们就可以保存我们平时见到的一些字符了。 于是就是有ASCII(美国(国家)信息交换标准(代)码),使用7个或8个二进制位进行编码的方案,最多可以给256个字符。使用了ASCII码,不同的计算机之间就可以实现数据的标准化。 但是ASCII使用的时候有一些限制。他最多之可以表示256个字符。如果有其他的字符就无能为力了。ASCII只能表示26个基本的拉丁字母、阿拉伯数字和英式标点。因此也只能用于显示现代美国英语。 后来计算机世界开始有了其他语言,ASCII码已经无法满足需求。后来不同语言的人各自为自己定制了一套属于自己的编码,同时与ASCII保持兼容。这些编码统称MBCS,到了这里大家都开始好似用双字节。(中国的叫GB*,比如GBK). 在后来有人开始觉得,这么多编码,有些编码之间还不兼容,太让人头大了,于是有这么一群人就坐在一起想出了一个办法:所有的语言都使用同一种编码,这种编码就是Unicode。 Unicode使用最少2个字节(1个字节=1BYTE=8bit=一个长度为8的二进制数) 来表示字母和符号等,有时候是4个字节。这样就解决了上面遇到的问题。 Unicode又叫万国码,是业界的一种标准。但是有人又觉得如果我要表示一个ASCII里的字符,使用unicode来表示不是太浪费空间了吗,于是就有人想出了另外一种解决方案——UTF-8。 UTF-8是对Unicode编码的压缩和优化,最大的特点是它采用了变长的编码方式,他不再是最少使用2个字节,而是将所有的字符进行分类。ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存…
不同编码之间的关系
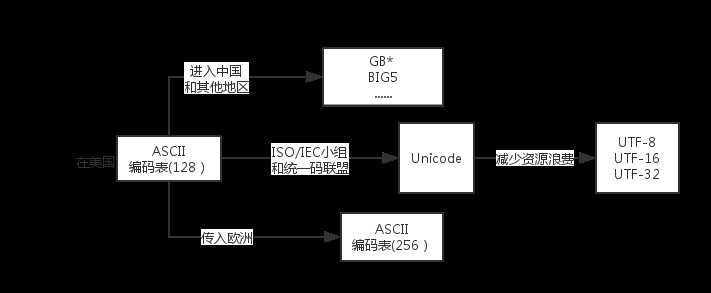
python2中文件的默认编码为ASCII,在文件中含有中文的时候就会报错,这时,我们需要是设置一下文件的默认编码,如下:
#!/usr/bin/env python # -*- coding: UTF-8 -*- # 指定python文件编码方式
在python3中,文件的默认编码为UTF-8,已经不存在这个问题。
python 入门学习 载抄
相关内容
- 暂无相关文章
评论关闭