python 基础一,,列表、元组操作字符串
python 基础一,,列表、元组操作字符串
列表、元组操作字符串操作字典操作集合操作文件操作字符编码与转码列表、元组操作
切片
>>> names = ["test","Tenglan","Eric","Rain","Tom","Amy"]>>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4[‘Tenglan‘, ‘Eric‘, ‘Rain‘]>>> names[1:-1] #取下标1至-1的值,不包括-1[‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘]>>> names[0:3] [‘test‘, ‘Tenglan‘, ‘Eric‘]>>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样[‘test‘, ‘Tenglan‘, ‘Eric‘]>>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写[‘Rain‘, ‘Tom‘, ‘Amy‘] >>> names[3:-1] #这样-1就不会被包含了[‘Rain‘, ‘Tom‘]>>> names[0::2] #后面的2是代表,每隔一个元素,就取一个[‘test‘, ‘Eric‘, ‘Tom‘] >>> names[::2] #和上句效果一样[‘test‘, ‘Eric‘, ‘Tom‘]
追加操作--append

插入操作

修改操作

删除操作

扩展操作

拷贝操作

统计操作

排序和反转操作

获取索引值操作

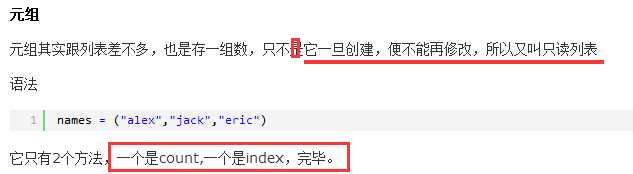
元组操作
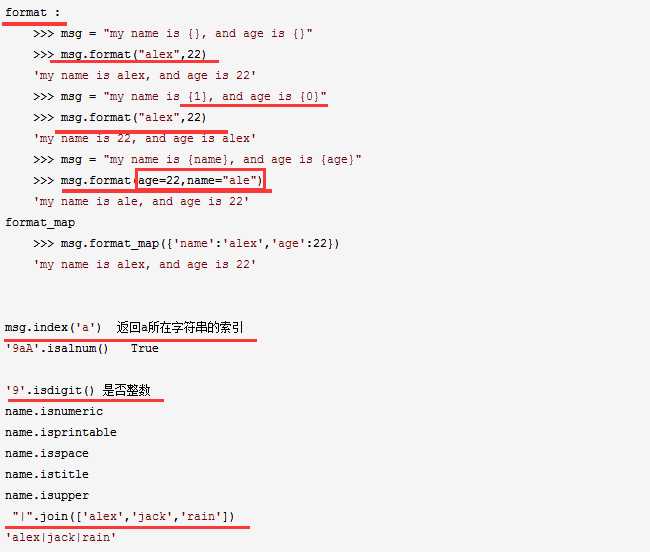
字符串操作

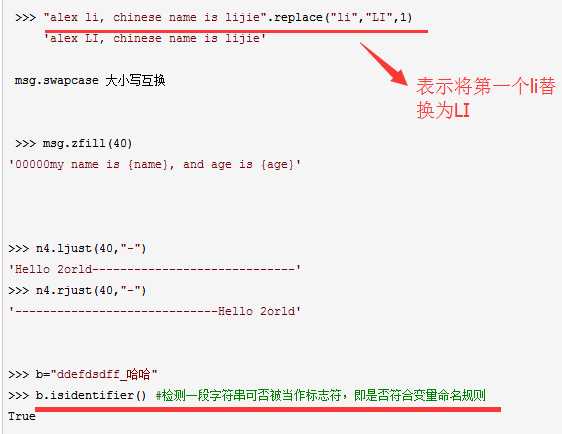
format函数和join函数
replace函数
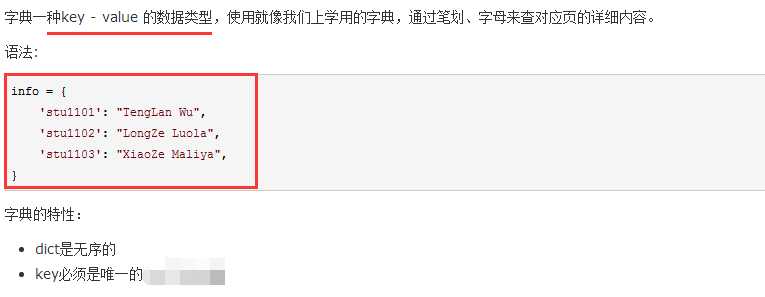
字典操作
增加操作

修改操作

删除操作

查找操作

其他操作

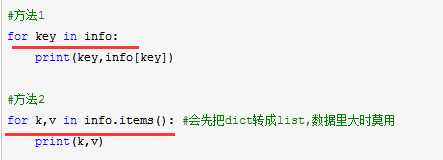
循环
集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
去重,把一个列表变成集合,就自动去重了
关系测试,测试两组数据之前的交集、差集、并集等关系



示例
l1 = [1,2,5,3,6,7,9]l2 = [2,3,5,8,9]①、设置一个集合list_1 = set(l1) ###设置一个集合print (type(list_1)) ###打印类型,为集合 打印结果:{1, 2, 3, 5, 6, 7, 9} <class ‘set‘>②、交集/并集/差集/对称差集###交集 (&)c = l1.intersection(l2)#print (c,type(c))###并集 (|)d = l1.union(l2)print (d,type(d))###差集 (-)e = l1.difference(l2) ###l1里面有,但是l2里面没有print (e)f = l2.difference(l1) ###l2里面有,但是l1里面没有print (f)####子集g = l1.issubset(l2)print (g) ###返回false,这里l1不是l2的子集####父集h = l1.issuperset(l2)print (h) ####返回fasle,这里l1不是l2的父集###对称差集(把两个集合里互相没有的取出来) (^)i = l1.symmetric_difference(l2)print (i)③、增删改查添加: l1.add(‘x‘) ###添加一项 l1.update(1,2,3) ###添加多项删除: pop ###删除一个元素并打印删除的返回值 remove ###删除指定的元素 文件操作
对文件操作流程
1.打开文件,得到文件句柄并赋值给一个变量
2.通过句柄对文件进行操作
3.关闭文件
f = open("aaaa",encoding="utf-8") # 打开文件first_line = f.readline()print(‘first line:‘, first_line) # 读一行print(‘我是分隔线‘.center(50, ‘-‘)) #打印结果----------------------我是分隔线-----------------------data = f.read() # 读取剩下的所有内容,文件大时不要用print(data) # 打印文件all_lines = f.readlines()print ("all_line:",all_lines) ###读取所有行f.close() # 关闭文件#打印前5行for i in range(5): print (f.readline())#####一行一行的读取(推荐使用,比较高效)f = open("aaaa") # 打开文件count = 0for line in f: if count == 2: print ("llall") count += 1 continue print (line) count += 1简写:count = 0for line in f: print(line) count += 1 if count == 2: print ("llall") continue####一次性读取所有文件内容打印前10行,如果打印到第6行时跳过(读取时直接读取所有到内存,遇到大文件不适合用):for index,value in enumerate(f.readlines()): ####enumerate枚举,下标从0开始, if index == 2: print ("daf") ###此处可不写,直接跳出循环从新开始 continue
编码解码
1.在python2(先转成unicode,先decode成unicode在encode成gbk或者utf-8)默认编码是ASCII, python3里默认是unicode bytes编码的经过decode 成中文字符串
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
示例:
import sysprint(sys.getdefaultencoding())msg = "我爱北京天安门" ##此时为unicodemsg_gb2312 = msg.encode(encoding="gb2312") ###此时只能encodegb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk")print(msg)print(msg_gb2312)print(gb2312_to_gbk)打印结果:utf-8我爱北京天安门b‘\xce\xd2\xb0\xae\xb1\xb1\xbe\xa9\xcc\xec\xb0\xb2\xc3\xc5‘b‘\xce\xd2\xb0\xae\xb1\xb1\xbe\xa9\xcc\xec\xb0\xb2\xc3\xc5‘所有的转码必须先转成unicode在从encode成“utf-8”或者“gb-2312”python 基础一
评论关闭