Python - 文件读写,,r:只读模式(如果没
Python - 文件读写,,r:只读模式(如果没
r:只读模式(如果没指定模式,默认为只读模式)
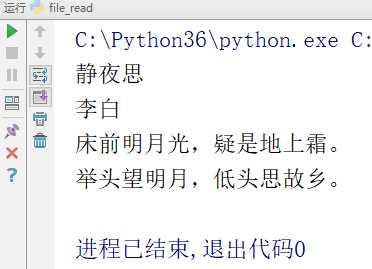
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘r‘) # 文件句柄fr = f.read()print(fr)f.close() # 关闭文件
运行结果
如果对同一个文件句柄连续进行 read() 操作的话,只有第一个 read() 操作有内容,其余的都是空白的
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘r‘) # 文件句柄fr = f.read()fr1 = f.read()fr2 = f.read()print(fr)print("---------")print(fr1)print("+++++++++")print("---------")print(fr2)print("+++++++++")f.close() # 关闭文件运行结果
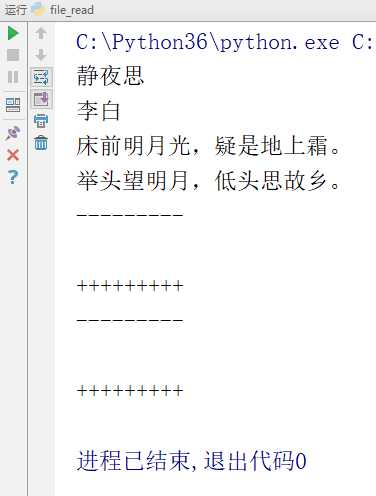
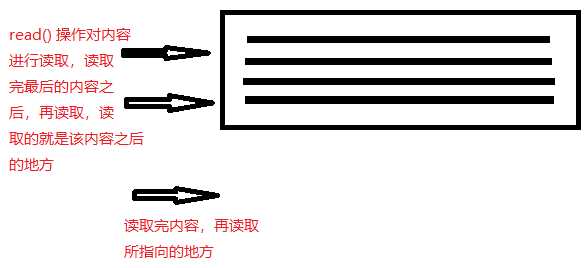
因为 read() 操作是连续的
readline() 进行一行一行地读取
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘r‘) # 文件句柄print(f.readline())print(f.readline())print(f.readline())print(f.readline())print(f.readline())f.close() # 关闭文件
运行结果
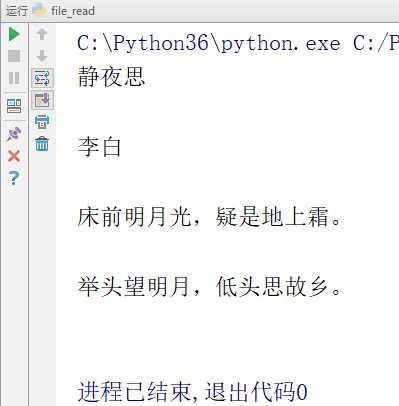
因为每一行末尾都有一个换行符 \n,打印的时候 \n 也打印了,所以空了一行
readlines() 以行为单位读取文件内容
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘r‘) # 文件句柄fr = f.readlines()print(fr)f.close() # 关闭文件
运行结果

结果是列表,每行字符串为该列表的元素,每行末尾有个换行符 \n
打印每行的内容
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘r‘) # 文件句柄for line in f.readlines(): print(line.strip()) # strip() 去掉换行符f.close() # 关闭文件
运行结果
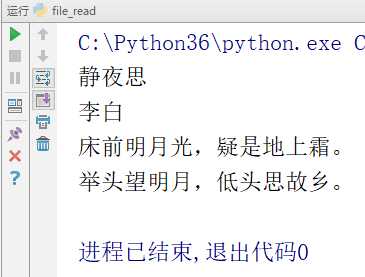
readlines() 遇到大文件时比较占内存,因为 readlines() 直接将整个文件读入内存,推荐用下面的方法
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘r‘) # 文件句柄for line in f: print(line.strip()) # strip() 去掉换行符f.close() # 关闭文件
这个方法是一行一行地读
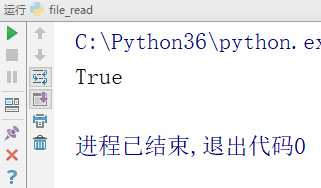
readable() 判断文件是否可读
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘r‘) # 文件句柄fr = f.readable()print(fr)f.close() # 关闭文件
运行结果
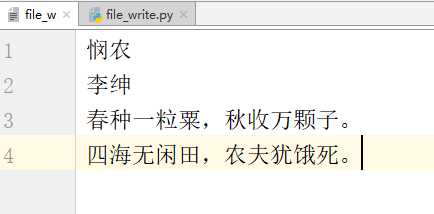
w:只写模式,文件不存在则创建,文件存在则覆盖原文件
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_w‘, mode=‘w‘)f.write(‘悯农\n‘)f.write(‘李绅\n‘)f.write(‘春种一粒粟,秋收万颗子。\n‘)f.write(‘四海无闲田,农夫犹饿死。‘)f.close()
运行,创建了一个文件“file_w”(本地没有该文件)
如果文件存在的话
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_w‘, mode=‘w‘)f.write(‘test‘)f.close()
运行结果
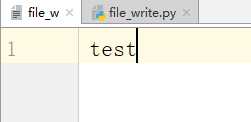
之前的内容被新的内容覆盖了
还有一个 writelines() 方法,可以写入一个序列
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_w‘, mode=‘w‘)f.writelines(["春种一粒粟,", "秋收万颗子。\n"])f.writelines(("四海无闲田,", "农夫犹饿死。\n"))f.writelines({"锄禾日当午,", "汗滴禾下土。\n"})f.writelines("谁知盘中餐,粒粒皆辛苦。")f.close()运行结果
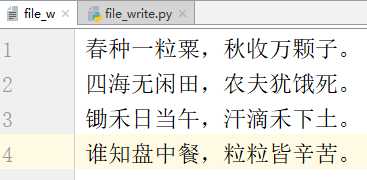
用逗号隔开的各个元素进行拼接
a:追加模式,只能写不能读,不会创建新文件,不会覆盖原文件,在原文件后追加内容
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file="file_w", mode=‘a‘)f.write(‘\nThis is a test‘)f.close()
运行结果
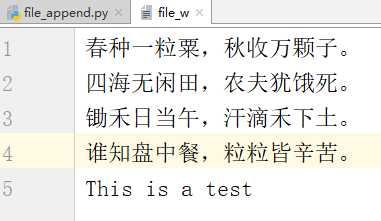
追加模式写的方法和只读模式用的方法一样,只不过追加模式是在原文件末尾添加内容
rb:只读二进制模式
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘rb‘)fr = f.read()print(fr)f.close()
运行结果

wb:只写二进制模式
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_w‘, mode=‘wb‘)f.write(‘春种一粒粟,秋收万颗子。\n‘.encode())f.write(b‘This is a test‘)f.close()
运行结果
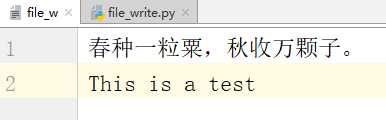
wb 也可以用来写入图片文件、音频文件等
ab:追加二进制模式
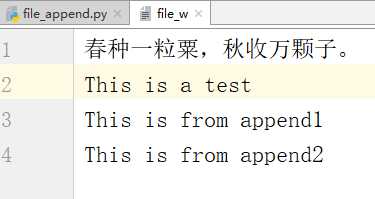
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file="file_w", mode=‘ab‘)f.write(‘\nThis is from append1\n‘.encode())f.write(b‘This is from append2‘)f.close()
运行结果
r+:读写模式,既可读,也可以写(读模式支持写)
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_test‘, mode=‘r+‘)fr = f.read()print(fr)f.write(‘From Writing‘)fr1 = f.read()print(fr1)f.close()
运行结果

写入的内容
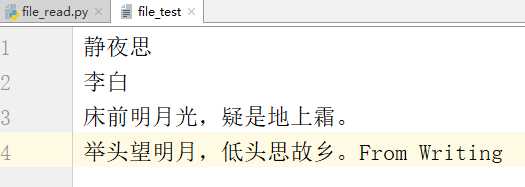
后来写进去的那句话并没有被读出来
w+:写读模式,既可写,也可以读(写模式支持读)
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file=‘file_w‘, mode=‘w+‘)print(f.read())f.write(‘四海无闲田,‘)f.write(‘农夫犹饿死。‘)print(f.read())f.close()
运行结果
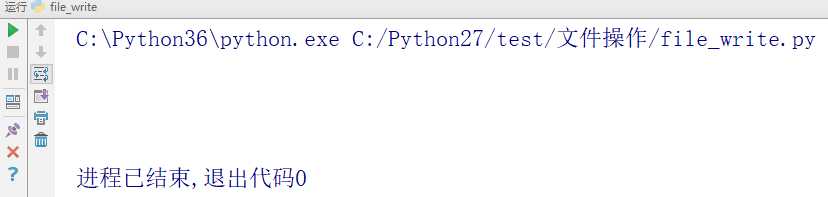
读出的内容是空的
写入的内容
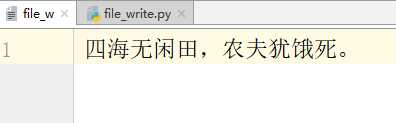
原来的内容被覆盖了
a+:可读追加模式
# -*- coding:utf-8 -*-__author__ = "MuT6 Sch01aR"f = open(file="file_w", mode=‘a+‘)print(f.read())f.write(‘\nThis is from append1\n‘)f.write(‘This is from append2‘)print(f.read())f.close()
运行结果
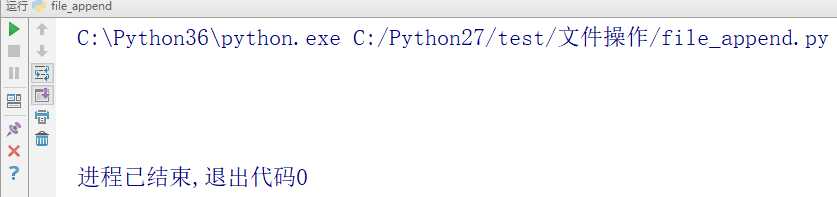
写入的内容

Python - 文件读写
评论关闭