[转] Python内存管理机制,,转自:https:/
[转] Python内存管理机制,,转自:https:/
转自:https://www.cnblogs.com/51try-again/p/11099999.html
一、引用计数
1、变量与对象
变量赋值的时候才创建,它可以指向(引用)任何类型的对象python里每一个东西都是对象,它们的核心就是一个结构体:PyObject变量必须先赋值,再引用。比如,你定义一个计数器,你必须初始化成0,然后才能自增。每个对象都包含两个头部字段(类型标识符和引用计数器)关系图如下:
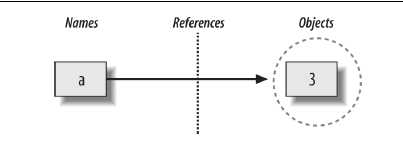
变量名没有类型,类型属于对象(因为变量引用对象,所以类型随对象),在Python中,变量是一种特定类型对象在一个特定的时间点的引用。
2、共享引用
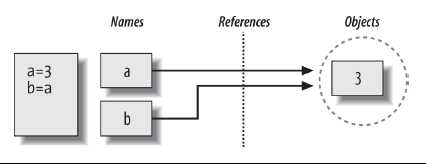
二、内存优化
1、id()
id()是 python 的内置函数,用于返回对象的标识,即对象的内存地址。
>>> help(id)Help on built-in function id in module builtins: id(obj, /) Return the identity of an object. This is guaranteed to be unique among simultaneously existing objects. (CPython uses the object‘s memory address.)
2、引用所指判断
通过is进行引用所指判断,is是用来判断两个引用所指的对象是否相同。
整数:
>>> a = 256>>> b = 256>>> a is bTrue>>> c = 257>>> d = 257>>> c is dFalse>>>
短字符串:
>>> e = "Explicit">>> f = "Explicit">>> e is fTrue>>>
长字符串:
>>> g = "Beautiful is better">>> h = "Beautiful is better">>> g is hFalse>>>
列表:
>>> lst1 = [1, 2, 3]>>> lst2 = [1, 2, 3]>>> lst1 is lst2False>>>
由运行结果可知:
1、Python缓存了整数和短字符串,因此每个对象在内存中只存有一份,引用所指对象就是相同的,即使使用赋值
语句,也只是创造新的引用,而不是对象本身;
2、Python没有缓存长字符串、列表及其他对象,可以由多个相同的对象,可以使用赋值语句创建出新的对象。
原理:
# 两种优化机制: 代码块内的缓存机制, 小数据池。 # 代码块代码全都是基于代码块去运行的(好比校长给一个班发布命令),一个文件就是一个代码块。不同的文件就是不同的代码块。 # 代码块内的缓存机制Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在文件执行时(同一个代码块)会把两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。 注意:# 机制只是在同一个代码块下!!!,才实行。# 满足此机制的数据类型:int str bool。 # 小数据池(驻留机制,驻村机制,字符串的驻存机制,字符串的缓存机制等等)不同代码块之间的优化。# 适应的数据类型:str bool intint: -5 ~256str: 一定条件下的str满足小数据池。bool值 全部。 # 总结:如果你在同一个代码块中,用同一个代码块中的缓存机制。如果你在不同代码块中,用小数据池。 # 优点:1,节省内存。2,提升性能。
3、查看对象的引用计数
在Python中,每个对象都有指向该对象的引用总数 ---引用计数
查看对象的引用计数:sys.getrefcount()
当对变量重新赋值时,它原来引用的值去哪啦?比如下面的例子,给 s 重新赋值 字符串 apple,6 跑哪里去啦?
>>> s = 6>>> s = ‘apple‘
答案是:当变量重新赋值时,它原来指向的对象(如果没有被其他变量或对象引用的话)的空间可能被收回(垃圾回收)
普通引用:
>>> import sys>>>>>> a = "simple">>> sys.getrefcount(a)2>>> b = a>>> sys.getrefcount(a)3>>> sys.getrefcount(b)3>>>
注意:当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多1。
三、垃圾回收
当Python中的对象越来越多,占据越来越大的内存,启动垃圾回收(garbage collection),将没用的对象清除。
1、原理
当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾。
比如某个新建对象,被分配给某个引用,对象的引用计数变为1。如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。
2、解析del
del 可以使 对象的引用计数减 1,该表引用计数变为0,用户不可能通过任何方式接触或者动用这个对象,当垃圾回收启动时,Python扫描到这个引用计数为0的对象,就将它所占据的内存清空。
注意
1、垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率;
2、Python只会在特定条件下,自动启动垃圾回收(垃圾对象少就没必要回收)
3、当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。
当两者的差值高于某个阈值时,垃圾回收才会启动。
>>> import gc>>>>>> gc.get_threshold() #gc模块中查看垃圾回收阈值的方法(700, 10, 10)>>>
阈值分析:
700即是垃圾回收启动的阈值;
每10 次 0代 垃圾回收,会配合 1次 1代 的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收;
当然也是可以手动启动垃圾回收:
>>> gc.collect() #手动启动垃圾回收52>>> gc.set_threshold(666, 8, 9) # gc模块中设置垃圾回收阈值的方法>>>
3、何为分代回收
Python将所有的对象分为0,1,2三代;所有的新建对象都是0代对象;当某一代对象经历过垃圾回收,依然存活,就被归入下一代对象。分代技术是一种典型的以空间换时间的技术,这也正是java里的关键技术。这种思想简单点说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。这样的思想,可以减少标记-清除机制所带来的额外操作。分代就是将回收对象分成数个代,每个代就是一个链表(集合),代进行标记-清除的时间与代内对象存活时间成正比例关系。从上面代码可以看出python里一共有三代,每个代的threshold值表示该代最多容纳对象的个数。默认情况下,当0代超过700,或1,2代超过10,垃圾回收机制将触发。0代触发将清理所有三代,1代触发会清理1,2代,2代触发后只会清理自己。
4、标记-清除
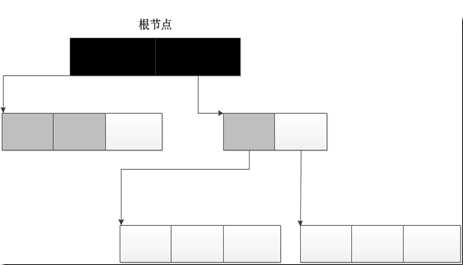
标记-清除机制,顾名思义,首先标记对象(垃圾检测),然后清除垃圾(垃圾回收)。首先初始所有对象标记为白色,并确定根节点对象(这些对象是不会被删除),标记它们为黑色(表示对象有效)。将有效对象引用的对象标记为灰色(表示对象可达,但它们所引用的对象还没检查),检查完灰色对象引用的对象后,将灰色标记为黑色。重复直到不存在灰色节点为止。最后白色结点都是需要清除的对象。
如何解决循环引用可能导致的内存泄露问题呢?
import gcimport objgraphimport sysimport weakref def quote_demo(): class Person: pass p = Person() # 1 print(sys.getrefcount(p)) # 2 first def log(obj): # 4 second 函数执行才计数,执行完释放 print(sys.getrefcount(obj)) log(p) # 3 p2 = p # 2 print(sys.getrefcount(p)) # 3 del p2 print(sys.getrefcount(p)) # 3 - 1 = 2 def circle_quote(): # 循环引用 class Dog: pass class Person: pass p = Person() d = Dog() print(objgraph.count("Person")) print(objgraph.count("Dog")) p.pet = d d.master = p # 删除 p, d之后, 对应的对象是否被释放掉 del p del d print(objgraph.count("Person")) print(objgraph.count("Dog")) def solve_cirecle_quote(): # 1. 定义了两个类 class Person: def __del__(self): print("Person对象, 被释放了") pass class Dog: def __del__(self): print("Dog对象, 被释放了") pass p = Person() d = Dog() p.pet = d d.master = p p.pet = None # 强制置 None del p del d gc.collect() print(objgraph.count("Person")) print(objgraph.count("Dog")) def sovle_circle_quote_with_weak_ref(): # 1. 定义了两个类 class Person: def __del__(self): print("Person对象, 被释放了") pass class Dog: def __del__(self): print("Dog对象, 被释放了") pass p = Person() d = Dog() p.pet = d d.master = weakref.ref(p) del p del d gc.collect() print(objgraph.count("Person")) print(objgraph.count("Dog")) if __name__ == "__main__": quote_demo() circle_quote() solve_cirecle_quote() sovle_circle_quote_with_weak_ref()答案是:
弱引用 使用weakref模块下的ref方法强制把其中一个引用变成 None四、内存池机制
Python中有分为大内存和小内存:(256K为界限分大小内存)
大内存使用malloc进行分配小内存使用内存池进行分配Python的内存池(金字塔)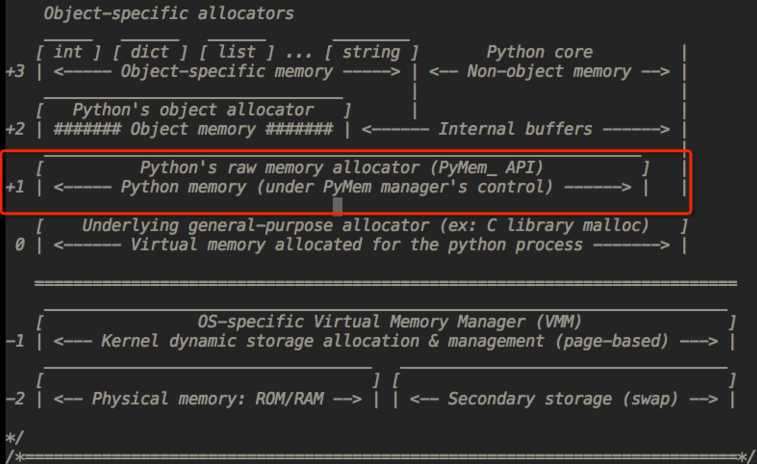
第+3层:最上层,用户对Python对象的直接操作
第+1层和第+2层:内存池,有Python的接口函数PyMem_Malloc实现
若请求分配的内存在1~256字节之间就使用内存池管理系统进行分配,调用malloc函数分配内存,但是每次只会分配一块大小为256K的大块内存,不会调用free函数释放内存,将该内存块留在内存池中以便下次使用第0层:大内存 -----> 若请求分配的内存大于256K,malloc函数分配内存,free函数释放内存。
第-1,-2层:操作系统进行操作
[转] Python内存管理机制
评论关闭