python--注释,,#的英文:pound
python--注释,,#的英文:pound
#的英文:pound character或者octothorpe
python中单行注释用#,多行注释用""",看下面的代码:
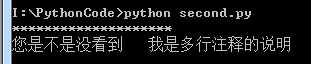
1 #!/usr/bin/python 2 #coding:utf-8 3 4 5 #编码方式 6 7 #打印一行* 8 9 print "********************" #我也是注释10 11 """12 我是多行注释13 """14 15 print "您是不是没看到 我是多行注释的说明"
结果:
特别说明下:
为什么#coding:utf-8能起作用?
我们参考python的官方文档发现,这是规定好的,一共三种方式,第三种方式运用了正则表达式,有兴趣可以去研究下。网址:https://www.python.org/dev/peps/pep-0263/
这个PEP的目的是介绍在一个Python源文件中如何声明编码的语法。随后Python解释器会在解释文件的时候用到这些编码信息。最显著的是源文件中对Unicode的解释,使得在一个能识别Unicode的编辑器中使用如FUT-8编码成为可能
1 Python will default to ASCII as standard encoding if no other encoding hints are given. 2 3 To define a source code encoding, a magic comment must be placed into the source files either as first or second line in the file, such as: 4 5 # coding=<encoding name> 6 or (using formats recognized by popular editors): 7 8 #!/usr/bin/python 9 # -*- coding: <encoding name> -*-10 or:11 12 #!/usr/bin/python13 # vim: set fileencoding=<encoding name> :14 More precisely, the first or second line must match the following regular expression:15 16 ^[ \t\v]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)17 The first group of this expression is then interpreted as encoding name. If the encoding is unknown to Python, an error is raised during compilation. There must not be any Python statement on the line that contains the encoding declaration. If the first line matches the second line is ignored.18 19 To aid with platforms such as Windows, which add Unicode BOM marks to the beginning of Unicode files, the UTF-8 signature \xef\xbb\xbf will be interpreted as ‘utf-8‘ encoding as well (even if no magic encoding comment is given).20 21 If a source file uses both the UTF-8 BOM mark signature and a magic encoding comment, the only allowed encoding for the comment is ‘utf-8‘. Any other encoding will cause an error.
python--注释
相关内容
- python中的多线程【转】,,转载自:http:/
- 17、Python之文件处理的高级方法,, 目录
- Python基础教程总结(二),, 上周总结了一下P
- 服务器硬件信息采集python版本,,#!/usr/bin
- Python入门5(pandas中merge中的参数how),, 1 import
- Python实现字典dict,,Python实现字典
- Python可执行对象——exec、eval、compile,,Python提供的调
- 程序媛计划——python网络编程,,class1 正则表
- Python学习第62天(css代码之1),, 今天和新认识的好
- Python IDLE背景主题,,相信刚进入pytho
评论关闭