python-classfiction,,1.概述: 对于一
python-classfiction,,1.概述: 对于一
1.概述:
对于一些结果较单一的离散数值,机器学习的分类器是一个不错的选择。例如,我们预测一封邮件是否为垃圾邮寄的时候,可以分析该邮件的相关的特征得出“0,1”的结果,从而分析得到该邮件的最终属性。2特点
2.1变形
分类器与线性回归相似,可以通过对数变形得到。
将线性函数引申成为“0,1”,通过辅助函数:
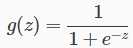
注:z值变为线性回归方程
当z值大于0时,g取值倾向于1;当z小于0时,函数值趋向于0
g函数图像:

2.2代价函数(cost function):
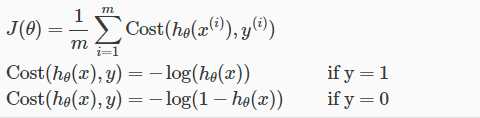
函数绘图:
当y为1时 当y为0时
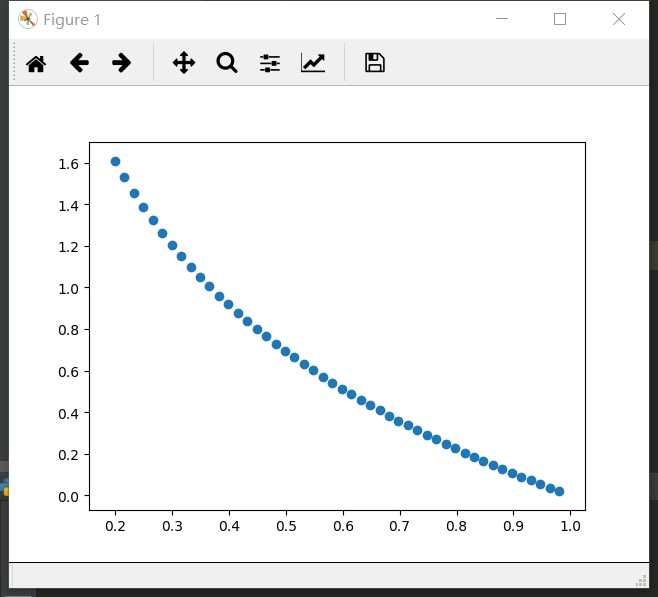
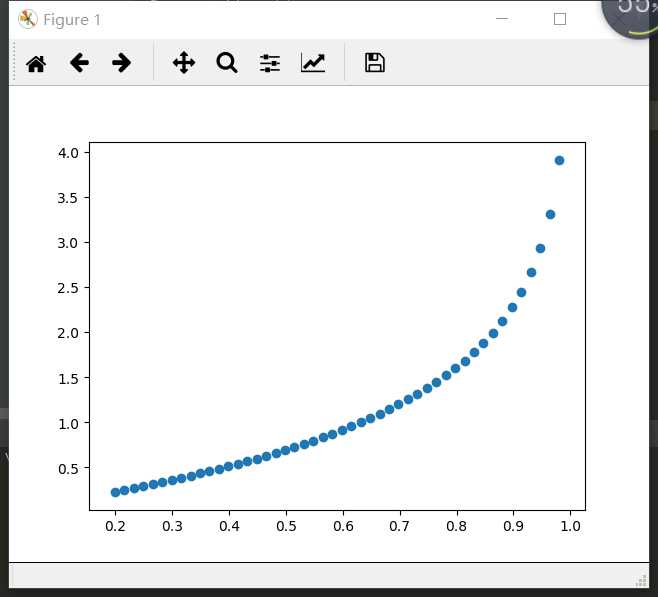
可知:当y=1时,结果越接近0,当y=1时,代价函数的值接近为0。别且注意函数的斜率,横坐标为线性函数。
2.3如何确定线性函数的thea(n):
通过梯度下降算法:当thea的值趋近于平缓,便接近收敛
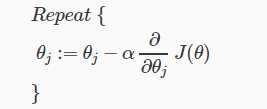
"BFGS", and "L-BFGS":该种方法不用进行步长的给予,能够更快地收敛。并且octave里面有内置函数。
3.举例
情感分类器也是如此,以cousera上的亚马逊商品评价为例,通过提取评价中的字数,小于三星是差评,大于则是好评,通过模型求解,获得商品评价的线性结果。
import graphlabproducts = graphlab.SFrame(‘amazon_baby.gl/‘)products[‘word_count‘] = graphlab.text_analytics.count_words(products[‘review‘])giraffe_reviews = products[products[‘name‘] == ‘Vulli Sophie the Giraffe Teether‘]products = products[products[‘rating‘]!=3]products[‘sentiment‘] = products[‘rating‘] >= 4print(products.head())#train sentiment classifiertrain_data,test_data = products.random_split(.8, seed=0)#logistic_classfiersentiment_model = graphlab.logistic_classifier.create(train_data, target=‘sentiment‘, features=[‘word_count‘], validation_set=test_data)sentiment_model.evaluate(test_data, metric=‘roc_curve‘)
sentiment_model.show(view=‘Evaluaion‘)
giraffe_reviews[‘predict_sentiment‘] = sentiment_model.predict(giraffe_reviews,output_type=‘probability‘) #paixu giraffe_reviews = giraffe_reviews.sort(‘predict_sentiment‘) print(giraffe_reviews[1])
python-classfiction
相关内容
- Python_面向对象_tkinter库,,#-- tkinte
- python基础_函数,,import num
- Python9-6,,函数中“
- Python之路,day3-Python基础,,三级菜单 1 men
- 初始Python(11)__类,,Python类Pyt
- python函数——形参中的:*args和**kwargs,,多个实参,放
- Python升级sqlite3到最新版,,Python升级sq
- python模块之os,,os 模块提供了很多
- Behave + Selenium(Python) ------ (第四篇),,最近比较忙, be
- 在python中实现线性回归(linear regression),,1 什么是线
评论关闭