python3获取一个网页特定内容,,我们今天要爬取的网址
python3获取一个网页特定内容,,我们今天要爬取的网址
我们今天要爬取的网址为:https://www.zhiliti.com.cn/html/luoji/list7_1.html
一、目标:获取下图红色部分内容
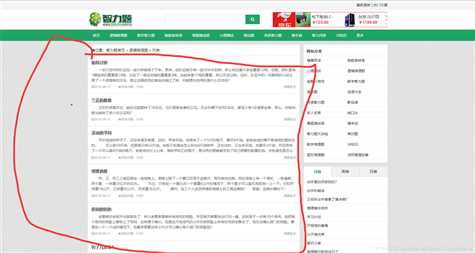
即获取所有的题目以及答案。
二、实现步骤。
分析:
1,首先查看该网站的结构。
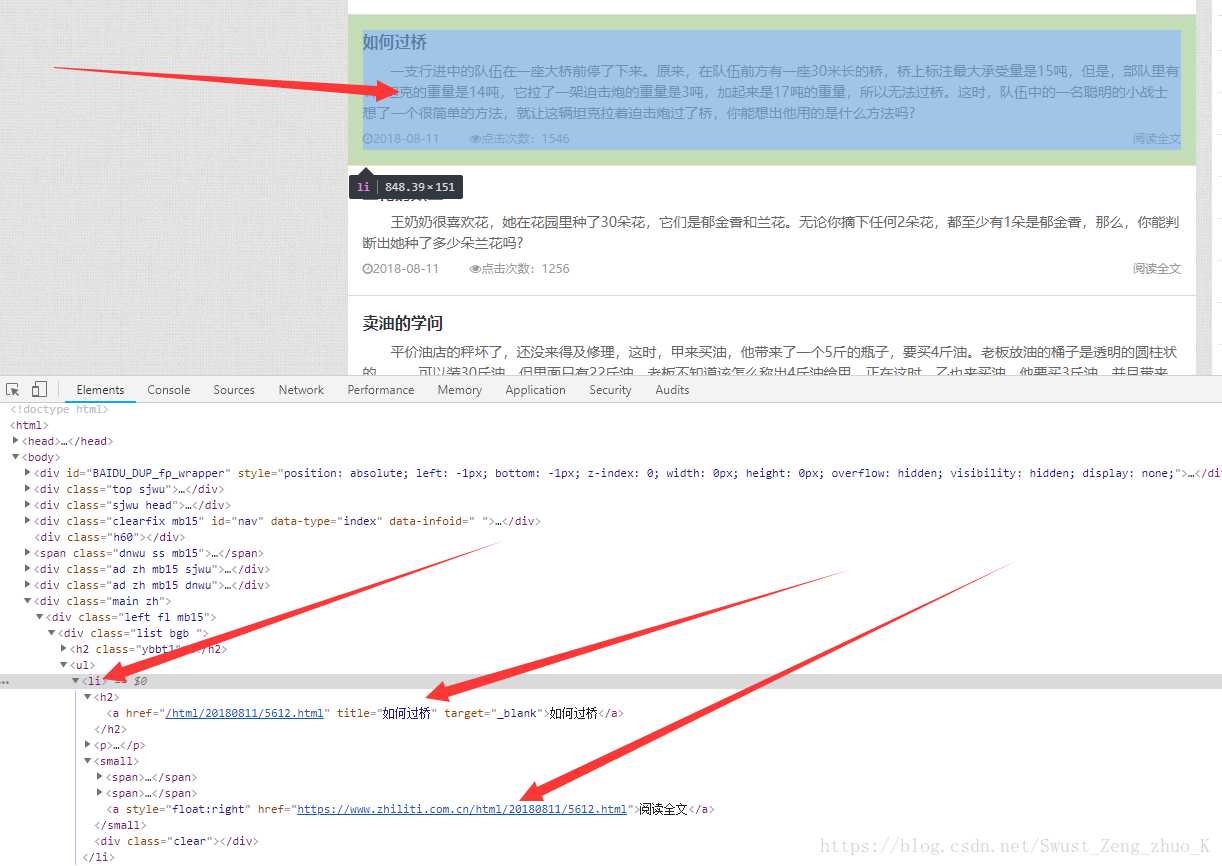
分析网页后可以得到:
我们需要的内容是在该网页<li>标签下,详细内容链接在<small>的<a>的href中。
但是这样我们最多只能获取这一页的内容
别着急
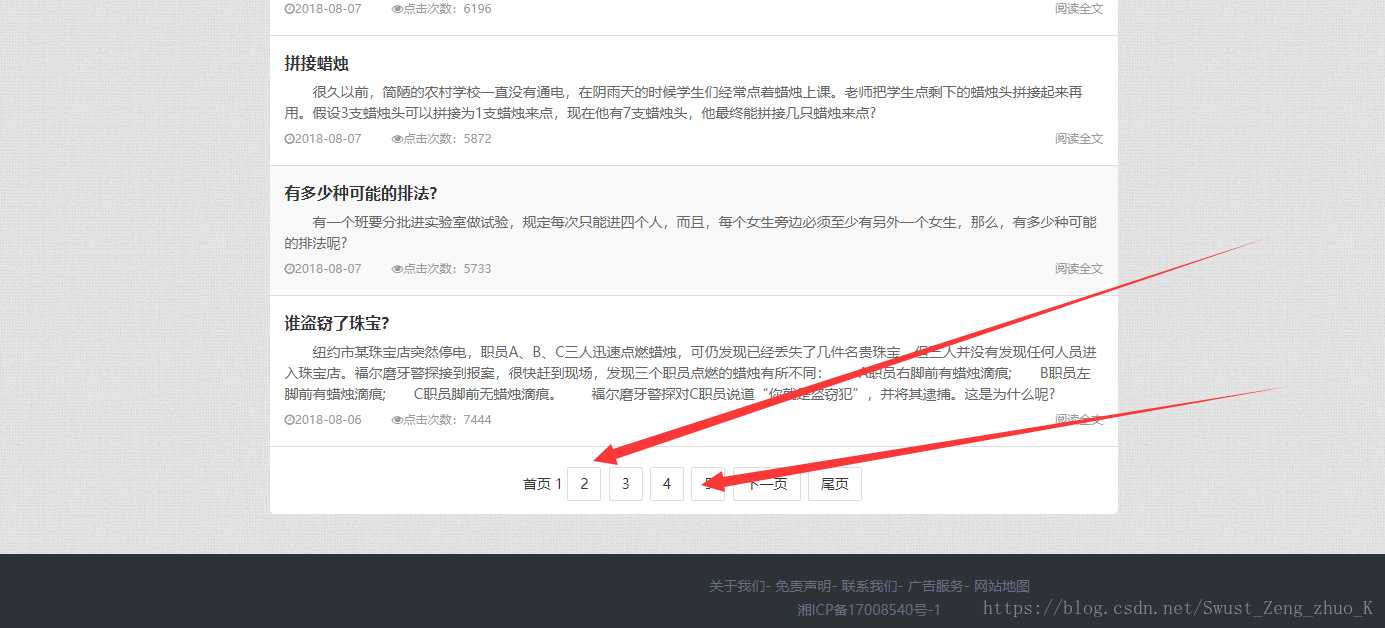
我们点击第二页看一下目标网址有什么变化
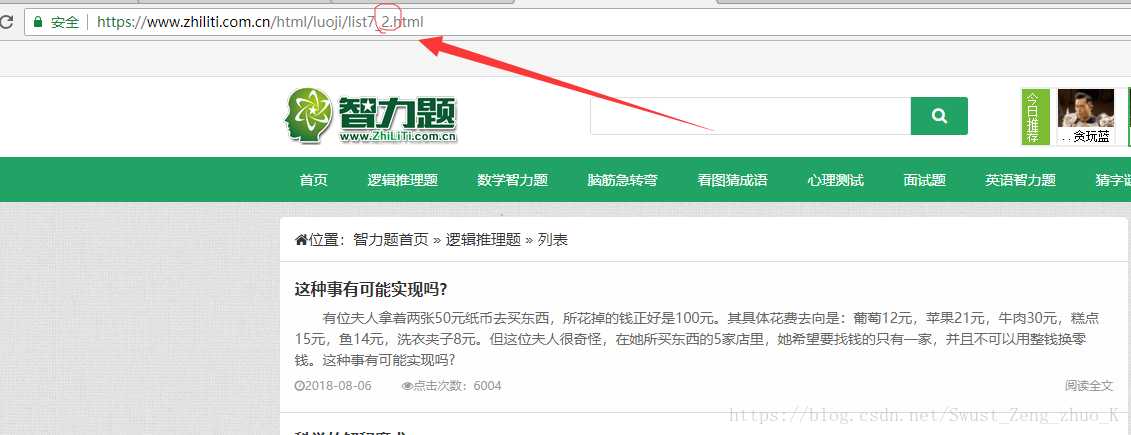
我们发现目标网址最后的数字变成了2
再看一下最后一页
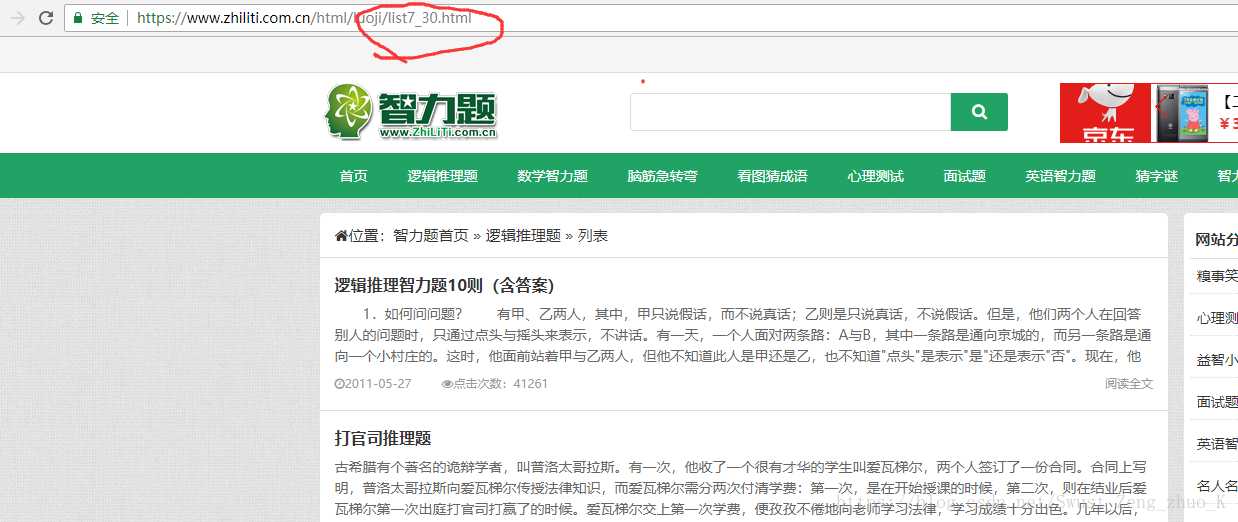
我们可以分析出最后那个数字即第几页,所以我们待会可以直接用一个for循环拼接字符串即可。
分析详细页面:
我们随便点击进入一个阅读全文
同样分析网页结构。
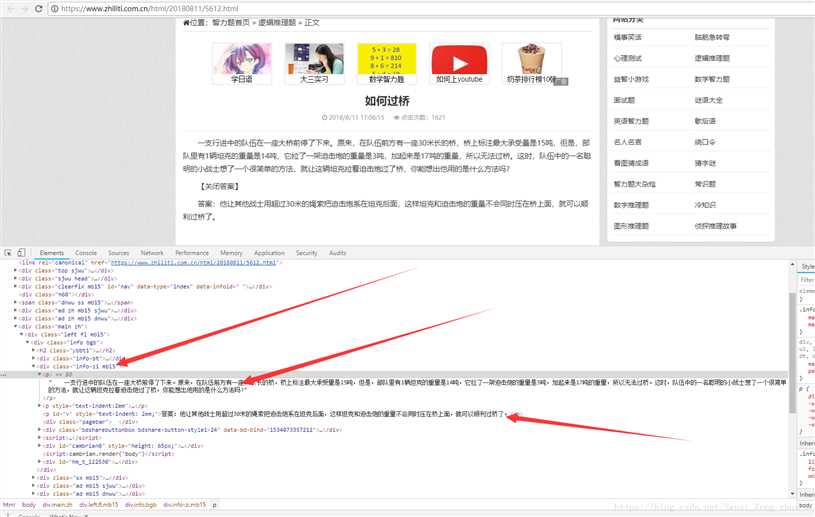
发现我们要的内容在一个块<divclass="info-zi mb15"/>的<p>标签中,我们在看一下其他题是不是也是这样的
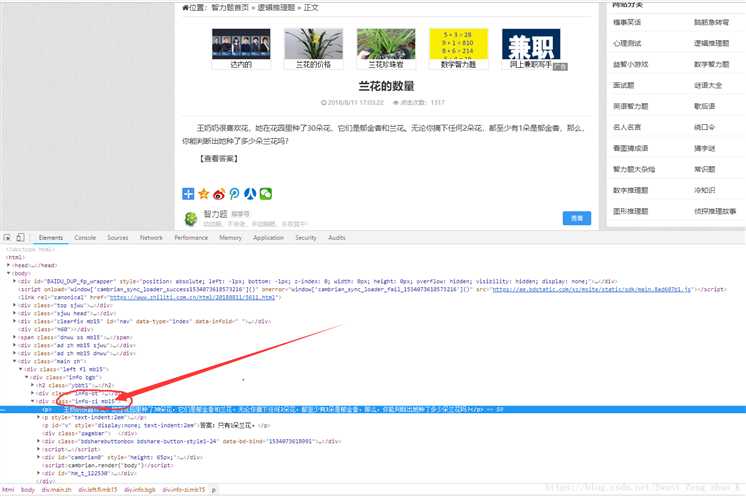
很明显是这样的,所以我们只需要获取class为info-zi mb15下的<p>标签下的内容即可。
所以我们接下来开始实现。
Let‘s Go
实现:
1,获取所有页
def getall(): for i in range(1,31,1): getalldoc(i)
i表示第i页,一共30页所以i从1变化到30,每次增加1。
2,获取当前页详细页面的连接
#获取目标网址第几页def getalldoc(ii):#字符串拼接成目标网址testurl = "https://www.zhiliti.com.cn/html/luoji/list7_"+str(ii)+".html"#使用request去get目标网址res = requests.get(testurl,headers=headers)#更改网页编码--------不改会乱码res.encoding="GB2312"#创建一个BeautifulSoup对象soup = BeautifulSoup(res.text,"html.parser")#找出目标网址中所有的small标签#函数返回的是一个listans = soup.find_all("small")#用于标识问题cnt = 1#先创建目录mkdir("E:\\Python爬取的文件\\问题\\第" + str(ii) + "页\\")for tag in ans: #获取a标签下的href网址 string_ans=str(tag.a.get("href")) #请求详细页面 #返回我们需要的字符串数据 string_write = geturl(string_ans) #写文件到磁盘 writedoc(string_write,cnt,ii) cnt = cnt+1print("第",ii,"页写入完成")
先拼接处目标网页url,然后调用request去请求,更改网页编码,使用BeautifulSoup对html文档进行解析,找出所有<small>标签,存入一个list,然后遍历该list,获取每一个<small>标签里的<a>标签的href属性,并将其转换为字符串string_ans。
得到详细页面的url之后我们调用geturl(自定义函数下面讲解)返回我们所需要的题目字符串,最后调用writedoc写入文件。
3,得到详细页面的url后筛选目标字符串
#根据详细页面url获取目标字符串def geturl(url): #请求详细页面 r = requests.get(url, headers=headers) #改编码 r.encoding = "GB2312" soup = BeautifulSoup(r.text, "html.parser") #找出类名为 info-zi mb15 下的所有p标签 ans = soup.find_all(["p", ".info-zi mb15"]) #用来储存最后需要写入文件的字符串 mlist = "" for tag in ans: #获取p标签下的string内容,并进行目标字符串拼接 mlist=mlist+str(tag.string) #返回目标字符串 return mlist
首先请求网页构建一个BeautifulSoup对象,筛选出class=info-zi mb15的对象下的<p>标签内容,返回类型为list,遍历list,将每个item的string拼接到目标字符串并返回。
4,将目标字符串写进文件
#写文件def writedoc(ss, i,ii): #打开文件 #编码为utf-8 with open("E:\\Python爬取的文件\\问题\\第" + str(ii) + "页\\"+"问题" + str(i) + ".txt", ‘w‘, encoding=‘utf-8‘) as f: #写文件 f.write(ss) print("问题" + str(i) + "文件写入完成" + "\n")5,创建指定目录
def mkdir(path): # 去除首位空格 path = path.strip() # 去除尾部 \ 符号 path = path.rstrip("\\") # 判断路径是否存在 # 存在 True # 不存在 False isExists = os.path.exists(path) # 判断结果 if not isExists: # 如果不存在则创建目录 # 创建目录操作函数 os.makedirs(path) return True else: # 如果目录存在则不创建,并提示目录已存在 return False三,最终python文件
import requestsfrom bs4 import BeautifulSoupimport os # 服务器反爬虫机制会判断客户端请求头中的User-Agent是否来源于真实浏览器,所以,我们使用Requests经常会指定UA伪装成浏览器发起请求headers = {‘user-agent‘: ‘Mozilla/5.0‘} #写文件def writedoc(ss, i,ii): #打开文件 #编码为utf-8 with open("E:\\Python爬取的文件\\问题\\第" + str(ii) + "页\\"+"问题" + str(i) + ".txt", ‘w‘, encoding=‘utf-8‘) as f: #写文件 f.write(ss) print("问题" + str(i) + "文件写入完成" + "\n") #根据详细页面url获取目标字符串def geturl(url): #请求详细页面 r = requests.get(url, headers=headers) #改编码 r.encoding = "GB2312" soup = BeautifulSoup(r.text, "html.parser") #找出类名为 info-zi mb15 下的所有p标签 ans = soup.find_all(["p", ".info-zi mb15"]) #用来储存最后需要写入文件的字符串 mlist = "" for tag in ans: #获取p标签下的string内容,并进行目标字符串拼接 mlist=mlist+str(tag.string) #返回目标字符串 return mlist #获取目标网址第几页def getalldoc(ii): #字符串拼接成目标网址 testurl = "https://www.zhiliti.com.cn/html/luoji/list7_"+str(ii)+".html" #使用request去get目标网址 res = requests.get(testurl,headers=headers) #更改网页编码--------不改会乱码 res.encoding="GB2312" #创建一个BeautifulSoup对象 soup = BeautifulSoup(res.text,"html.parser") #找出目标网址中所有的small标签 #函数返回的是一个list ans = soup.find_all("small") #用于标识问题 cnt = 1 #先创建目录 mkdir("E:\\Python爬取的文件\\问题\\第" + str(ii) + "页\\") for tag in ans: #获取a标签下的href网址 string_ans=str(tag.a.get("href")) #请求详细页面 #返回我们需要的字符串数据 string_write = geturl(string_ans) #写文件到磁盘 writedoc(string_write,cnt,ii) cnt = cnt+1 print("第",ii,"页写入完成") def mkdir(path): # 去除首位空格 path = path.strip() # 去除尾部 \ 符号 path = path.rstrip("\\") # 判断路径是否存在 # 存在 True # 不存在 False isExists = os.path.exists(path) # 判断结果 if not isExists: # 如果不存在则创建目录 # 创建目录操作函数 os.makedirs(path) return True else: # 如果目录存在则不创建,并提示目录已存在 return False def getall(): for i in range(1,31,1): getalldoc(i) if __name__ == "__main__": getall()四,运行结果
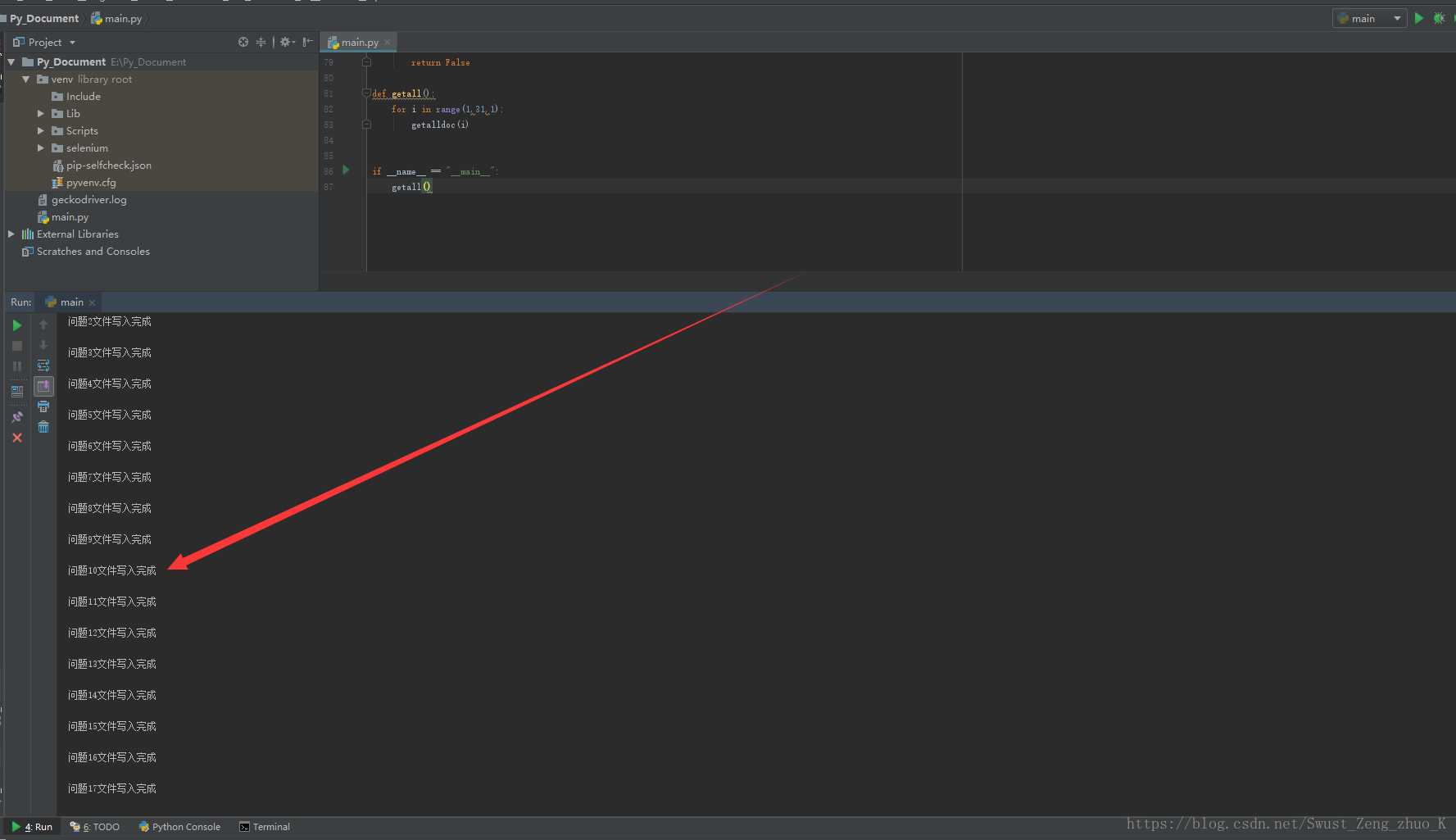
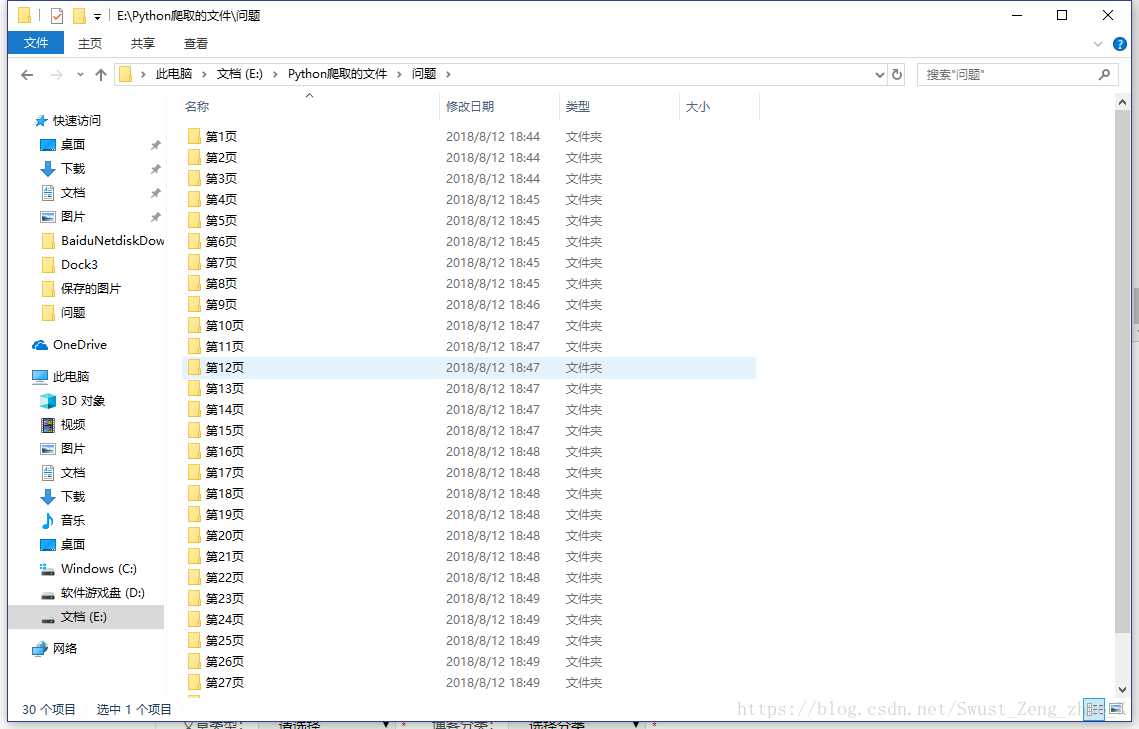
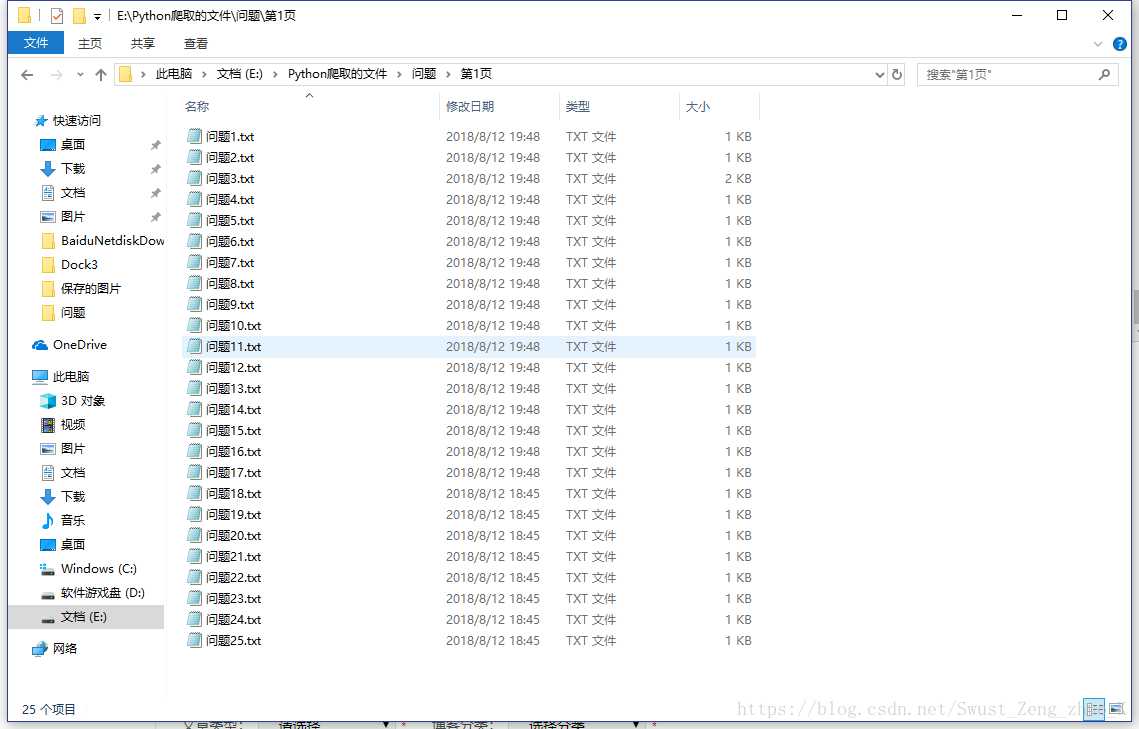
五,总结
一般网页的编码为utf-8编码,但是这个网页就不一样编码为GB2312,我第一次请求返回的是乱码,如果python向一个不存在的目录进行写文件会报错,所以写文件之前要先判断路径是否正确存在,不存在就要创建路径,请求头请使用下面这个
# 服务器反爬虫机制会判断客户端请求头中的User-Agent是否来源于真实浏览器,所以,我们使用Requests经常会指定UA伪装成浏览器发起请求headers = {‘user-agent‘: ‘Mozilla/5.0‘}python3获取一个网页特定内容
相关内容
- Python之Python基本数据类型,,变量不能用数字开头最
- (06)-Python3之--判断、循环,,1.判断(if)语法
- Python学习第七天课后总结,,<html>?pyt
- Python学习—字符串练习,,Python字符串练
- 02-python 学习第二天,,今天学习了以下几个方
- 机器学习经典分类算法 —— k-均值算法(附python实现代
- Python (从数据类型~字典)的测试题,,Python基础数据
- Leetcode147-对链表进行插入排序(Python3实现),,其实就是普
- Python面向对象(类之间的关系)(三),,类与类之间的关系
- Python_00_高阶函数,, 1.abs(
评论关闭