Python编程(三)字符编码与文件处理,,计算机要想工作必须通
Python编程(三)字符编码与文件处理,,计算机要想工作必须通
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字
编程的目的是让计算机干活,而编程的结果说白了只是一堆字符,也就是说我们编程最终要实现的是:一堆字符驱动计算机干活
所以必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
字符编码 :字符--》二进制数字的标准
阶段一:
ASCII:一个Bytes代表一个字符(英文+符号)
1Bytes=8bit,8bit可以表示256个字符
最初只用了后7位,127个数字,预留一位
阶段二:
中国制定GBK
2Bytes代表一个字符
阶段三:
语言多,混合出现乱码
产生Unicode,统一用2Bytes代表一个字符,2**16-1 65535个
对于英文来说,这种方式多了一倍的空间,浪费空间
于是产生 UTF-8,对英文只用1Bytes,对中午用3 bYtes
unicode: 所有都是2Bytes
正确使用字符编码:
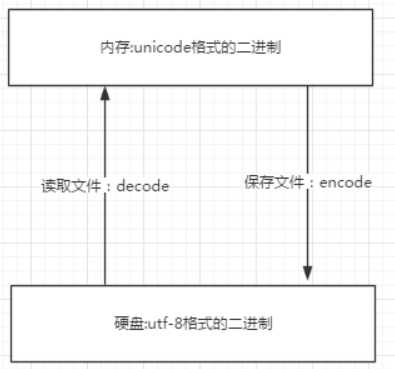
内存中默认都是unicode
文件村:内存刷到硬盘
文件读:硬盘读到内存
1.文件执行前:文件存的时候用什么编码,读的时候要用相同的编码
2.文件执行时:才有了字符串这个数据类型的概念
x=‘hello‘ python3的字符串默认是unicode
unicode类型可以encode不可 x.encode(‘gbk‘)python3中
须知:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
乱码:
乱码一:存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存,
本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败,用open函数的write可以测试,f=open(‘a.txt‘,‘w‘,encodig=‘shift_jis‘)
f.write(‘你\nて\n‘) #‘你‘因为在shiftjis中没有找到对应关系而无法保存成功,只存‘て\n‘可以成功
但当我们用文件编辑器去存的时候,编辑器会帮我们做转换,保证中文也能用shiftjis存储(硬存,必然乱码),这就导致了,存文件阶段就已经发生乱码
此时当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了
乱码二:存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就ok了,而存文件时乱码,则是一种数据的损坏。
总结:
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
文件处理:
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】w,只写模式【不可读;不存在则创建;存在则清空内容】x, 只写模式【不可读;不存在则创建,存在则报错】a, 追加模式【可读; 不存在则创建;存在则只追加内容】"+" 表示可以同时读写某个文件
r+, 读写【可读,可写】w+,写读【可读,可写】x+ ,写读【可读,可写】a+, 写读【可读,可写】"b"表示以字节的方式操作
rb 或 r+bwb 或 w+bxb或 w+bab或 a+b注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
flush原理:
文件操作是通过软件将文件从硬盘读到内存写入文件的操作也都是存入内存缓冲区buffer(内存速度快于硬盘,如果写入文件的数据都从内存刷到硬盘,内存与硬盘的速度延迟会被无限放大,效率变低,所以要刷到硬盘的数据我们统一往内存的一小块空间即buffer中放,一段时间后操作系统会将buffer中数据一次性刷到硬盘)flush即,强制将写入的数据刷到硬盘1. open()语法
open(file[, mode[, buffering[, encoding[, errors[, newline[, closefd=True]]]]]])
open函数有很多的参数,常用的是file,mode和encoding
file文件位置,需要加引号
mode文件打开模式,见下面3
buffering的可取值有0,1,>1三个,0代表buffer关闭(只适用于二进制模式),1代表line buffer(只适用于文本模式),>1表示初始化的buffer大小;
encoding表示的是返回的数据采用何种编码,一般采用utf8或者gbk;
errors的取值一般有strict,ignore,当取strict的时候,字符编码出现问题的时候,会报错,当取ignore的时候,编码出现问题,程序会忽略而过,继续执行下面的程序。
newline可以取的值有None, \n, \r, ”, ‘\r\n‘,用于区分换行符,但是这个参数只对文本模式有效;
closefd的取值,是与传入的文件参数有关,默认情况下为True,传入的file参数为文件的文件名,取值为False的时候,file只能是文件描述符,什么是文件描述符,就是一个非负整数,在Unix内核的系统中,打开一个文件,便会返回一个文件描述符。
2.Python中file()与open()区别
两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别,file为文件类,用file()来打开文件,相当于这是在构造文件类,而用open()打开文件,是用python的内建函数来操作,建议使用open
3. 参数mode的基本取值
| Character | Meaning |
| ‘r‘ | open for reading (default) |
| ‘w‘ | open for writing, truncating the file first |
| ‘a‘ | open for writing, appending to the end of the file if it exists |
| ‘b‘ | binary mode |
| ‘t‘ | text mode (default) |
| ‘+‘ | open a disk file for updating (reading and writing) |
| ‘U‘ | universal newline mode (for backwards compatibility; should not be used in new code) |
r、w、a为打开文件的基本模式,对应着只读、只写、追加模式;
b、t、+、U这四个字符,与以上的文件打开模式组合使用,二进制模式,文本模式,读写模式、通用换行符,根据实际情况组合使用、
常见的mode取值组合

1 r或rt 默认模式,文本模式读 2 rb 二进制文件 3 4 w或wt 文本模式写,打开前文件存储被清空 5 wb 二进制写,文件存储同样被清空 6 7 a 追加模式,只能写在文件末尾 8 a+ 可读写模式,写只能写在文件末尾 9 10 w+ 可读写,与a+的区别是要清空文件内容11 r+ 可读写,与a+的区别是可以写到文件任何位置
回到顶部2.7 上下文管理
with open(‘a.txt‘,‘w‘) as f: pass
with open(‘a.txt‘,‘r‘) as read_f,open(‘b.txt‘,‘w‘) as write_f: data=read_f.read() write_f.write(data)回到顶部
2.8 文件的修改
import oswith open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as read_f, open(‘.a.txt.swap‘,‘w‘,encoding=‘utf-8‘) as write_f: for line in read_f: if line.startswith(‘hello‘): line=‘哈哈哈\n‘ write_f.write(line)os.remove(‘a.txt‘)os.rename(‘.a.txt.swap‘,‘a.txt‘)
Python编程(三)字符编码与文件处理
评论关闭