python基础(三)----字符编码以及文件处理,,字符编码与文件处理一
python基础(三)----字符编码以及文件处理,,字符编码与文件处理一
字符编码与文件处理
一.字符编码
由字符翻译成二进制数字的过程字符--------(翻译过程)------->数字这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。字符编码的发展史阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符 ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符) 后来为了将拉丁文也编码进了ASCII表,将最高位也占用了阶段二:为了满足中文,中国人定制了GBK GBK:2Bytes代表一个字符 为了满足其他国家,各个国家纷纷定制了自己的编码 日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes需要强调的一点是:unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。用什么类型的字符编码存数据那么就用什么类型的字符编码解数据!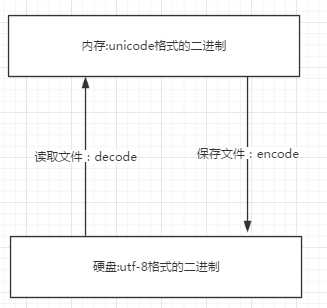
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print(‘包含中文的str‘)包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord(‘A‘)65>>> ord(‘中‘)20013>>> chr(66)‘B‘>>> chr(25991)‘文‘
如果知道字符的整数编码,还可以用十六进制这么写str:
>>> ‘\u4e2d\u6587‘‘中文‘
两种写法完全是等价的。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b‘ABC‘
要注意区分‘ABC‘和b‘ABC‘,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> ‘ABC‘.encode(‘ascii‘)b‘ABC‘>>> ‘中文‘.encode(‘utf-8‘)b‘\xe4\xb8\xad\xe6\x96\x87‘>>> ‘中文‘.encode(‘ascii‘)Traceback (most recent call last): File "<stdin>", line 1, in <module>UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b‘ABC‘.decode(‘ascii‘)‘ABC‘>>> b‘\xe4\xb8\xad\xe6\x96\x87‘.decode(‘utf-8‘)‘中文‘
要计算str包含多少个字符,可以用len()函数:
>>> len(‘ABC‘)3>>> len(‘中文‘)2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b‘ABC‘)3>>> len(b‘\xe4\xb8\xad\xe6\x96\x87‘)6>>> len(‘中文‘.encode(‘utf-8‘))6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python第一行注释是为了告诉Linux/OSX系统,这是一个Python可执行程序,Windows系统会忽略这个注释;第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
# -*- coding: utf-8 -*-
二Python对于文件处理的操作
打开文件的模式有:r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】w,只写模式【不可读;不存在则创建;存在则清空内容】x, 只写模式【不可读;不存在则创建,存在则报错】a, 追加模式【可读; 不存在则创建;存在则只追加内容】"+" 表示可以同时读写某个文件r+, 读写【可读,可写】w+,写读【可读,可写】x+ ,写读【可读,可写】a+, 写读【可读,可写】"b"表示以字节的方式操作rb 或 r+bwb 或 w+bxb或 w+bab或 a+b注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码#r模式,默认模式,文不存在则报错# f=open(‘a.txt‘,encoding=‘utf-8‘)# # print(‘first-read:‘,f.read())# # print(‘seconde-read: ‘,f.read())## # print(f.readline(),end=‘‘)# # print(f.readline(),end=‘‘)### # print(f.readlines())## # print(f.write(‘asdfasdfasdfasdfasdfasdf‘))## f.close()#w模式,文不存在则创建,文件存在则覆盖# f=open(‘a.txt‘,‘w‘,encoding=‘utf-8‘)# f.write(‘1111111\n22222\n3333\n‘)# # f.write(‘2222222\n‘)## # f.writelines([‘11111\n‘,‘22222\n‘,‘3333\n‘])## f.close()#a模式,文不存在则创建,文件存在不会覆盖,写内容是追加的方式写# f=open(‘a.txt‘,‘a‘,encoding=‘utf-8‘)# f.write(‘\n444444\n‘)# f.write(‘5555555\n‘)# f.close()#其他方法# f=open(‘a.txt‘,‘w‘,encoding=‘utf-8‘)# f.write(‘asdfasdf‘)# f.flush() #吧内存数据刷到硬盘# f.close()# print(f.closed) #判断文件是否关闭# f.readlines()# print(f.name,f.encoding)# print(f.readable())# print(f.writable())## f=open(‘c.txt‘,‘r‘,encoding=‘utf-8‘)# print(f.read(3))# print(‘first_read: ‘,f.read())# f.seek(0)# print(‘second_read: ‘,f.read())## f.seek(3)# print(f.tell())# print(f.read())# f=open(‘c.txt‘,‘w‘,encoding=‘utf-8‘)# f.write(‘1111\n‘)# f.write(‘2222\n‘)# f.write(‘3333\n‘)# f.write(‘444\n‘)# f.write(‘5555\n‘)# f.truncate(3)# f=open(‘a.txt‘,‘a‘,encoding=‘utf-8‘)## f.truncate(2)#r w a; rb wb ab# f=open(‘a.txt‘,‘rb‘)## print(f.read())# print(f.read().decode(‘utf-8‘))# f.close()# f=open(‘a.txt‘,‘wb‘)## print(f.write(‘你好啊‘.encode(‘utf-8‘)))# f.close()上下文管理我们经常在打开文件操作时忘记了一个小的操作--关闭文档.colse()我们用with as的模式来打开文档操作就可以避免这个小错误!withopen(‘a.txt‘,‘w‘)asf: pass如何将文件的内容进行批量的修改:read_f=open(‘a.txt‘,‘r‘,encoding=‘utf-8‘)
write_f=open(‘.a.txt.swp‘,‘w‘,encoding=‘utf-8‘)
with open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as read_f,\#将文件打开
open(‘.a.txt.swp‘,‘w‘,encoding=‘utf-8‘) as write_f:#并且再创建一个文件名为.a.txt.swp的文件
for line in read_f:
if ‘alex‘ in line: #找到想要替换的内容
line=line.replace(‘alex‘,‘ALEXSB‘) #并且将旧的内容替换成新的内容存在.a.txt.swp的文件中
write_f.write(line) #不符合条件的不动
os.remove(‘a.txt‘) #将源文件删除
os.rename(‘.a.txt.swp‘,‘a.txt‘) #将.a.txt.swp这个文件该成a.txt这样就实现了文件内容的批量修改!
python基础(三)----字符编码以及文件处理
评论关闭