python爬取网页图片,,在Python中使用
python爬取网页图片,,在Python中使用
在Python中使用正则表达式,一个小小的爬虫,抓取百科词条网页的jpg图片。下面就是我的代码,作为参考:
#coding=utf-8# __author__ = ‘Hinfa‘import reimport osfrom urllib import request as requrl=‘https://baike.baidu.com/item/%E5%B9%BF%E5%B7%9E/72101?fr=aladdin‘path=‘Test//百科广州图片2‘os.mkdir(path)fo=open(path+‘//filecatalog.txt‘,‘w+‘)fo.write(‘爬取jpg目录:‘)page=req.urlopen(url)html=page.read().decode(‘utf-8‘)jpgre=re.compile(r‘https.*?\.jpg‘)jpglist=re.findall(jpgre,html)i=0for jpg in jpglist: jpg=re.sub(r‘\\\/‘,‘/‘,jpg) print(jpg) filepath=path+‘//%d.jpg‘%i fo.write(‘\n‘+jpg) req.urlretrieve(jpg,filepath) i+=1fo.write(‘\n‘+‘爬取共计‘+str(i)+‘个‘)fo.flush()fo.close()
程序运行结果:

然后打开目录文件里生成的filecatalog.txt文件,爬取的内容如下:
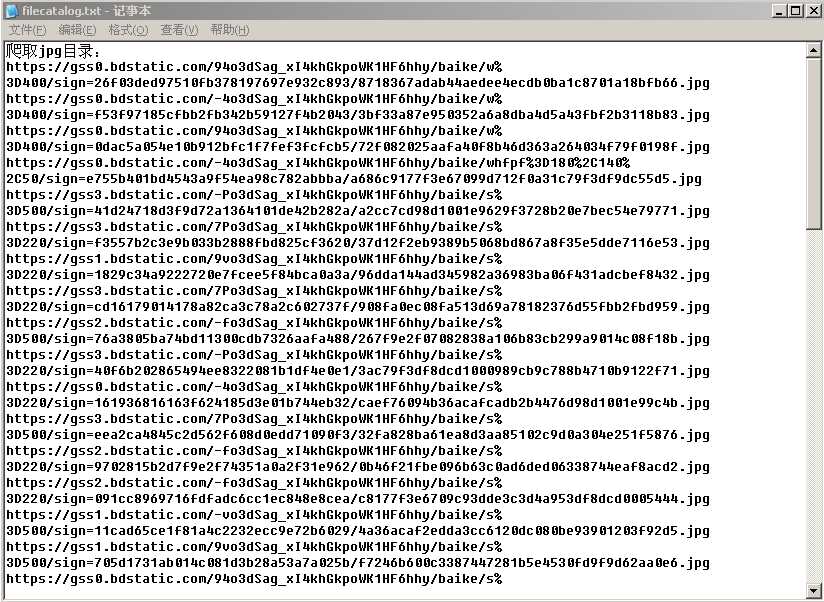
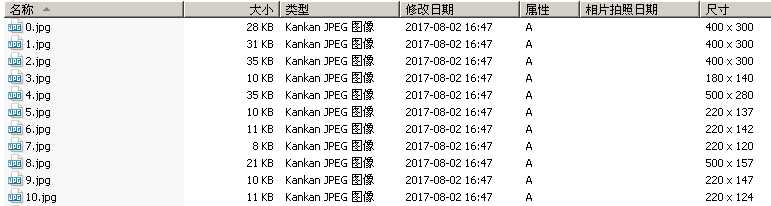
目录地址下载的图片:
第一次爬虫,很兴奋,也觉得很神奇:-)
python爬取网页图片
评论关闭