【Python数据分析】pands中的Merge与join,, 目录
【Python数据分析】pands中的Merge与join,, 目录
目录
1.Merge 1.1 简单关联:left_on与right_on 1.2 使用how参数:指定连接方式 1.3 right_index与right_index 1.4 sort参数:排序 2.join1.Merge
Pandas具有全功能的,高性能内存中连接操作,与关系型数据库中的连接操作类似。
语法:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False)1.1 简单关联:left_on与right_on
下面是Merge的一些实战案例:
(1)创建测试数组
import pandas as pddf1 = pd.DataFrame({'studentNo':['A01','A02','A03','A04'], 'studentName':['Jack','Lucy','Marry','Tom'], 'studentAge':[18,19,21,17], 'classNo':['class01','class02','class03','class02'] })df2 = pd.DataFrame({'classNo':['class01','class02','class03','class04'], 'className':['火箭1班','火箭2班','火箭3班','火箭4班'] })# 学生信息print(df1)# 班级信息print(df2)(2)使用Merge,找出每个学生对应的班级名字
print(pd.merge(df1, df2, on="classNo")) # 这里的df1类似关系型数据库的主表,df2对应# 如果存在多个键关联,则on = ['key1','key2']
输出结果:
1.2 使用how参数:指定连接方式
# 1.取交集:默认取交集print('--------参数how = \'inner\'的结果--------------') print(pd.merge(df1, df2, on="classNo",how='inner')) # 类似内连接# 2.取并集,数据缺失则为NaNprint('--------参数how = \'outer\'的结果--------------')print(pd.merge(df1, df2, on="classNo",how='outer')) # 类似全连接# 3.左连接print('--------参数how = \'left\'的结果--------------')print(pd.merge(df1, df2, on="classNo",how='left')) # 4.右连接print('--------参数how = \'right\'的结果--------------')print(pd.merge(df1, df2, on="classNo",how='right')) 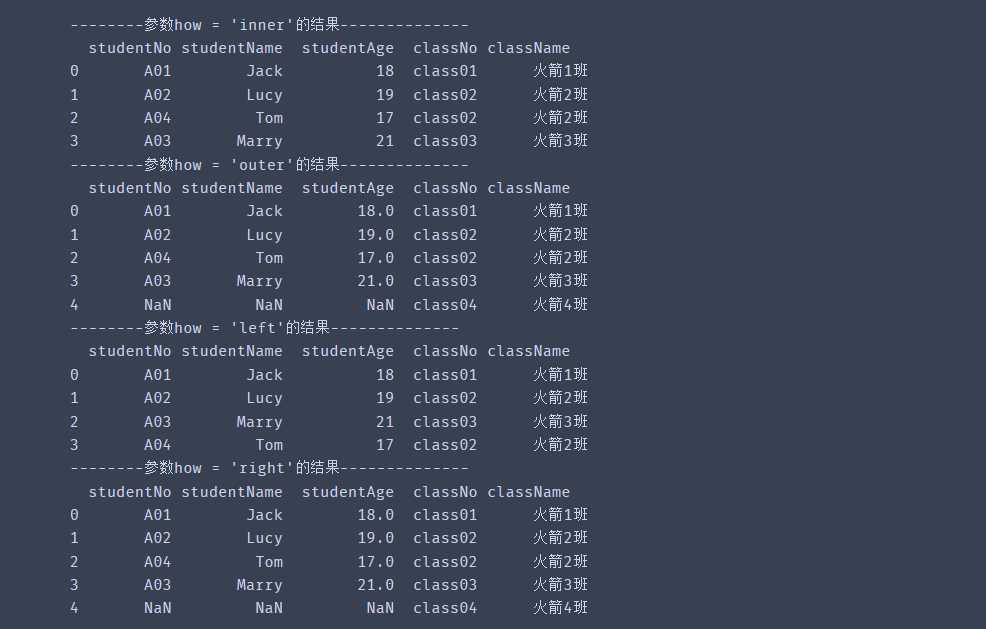
1.3 right_index与right_index
import pandas as pddf1 = pd.DataFrame({'left_key':list('abcd'), 'data1':range(4)})df2 = pd.DataFrame({'right_key':list('acef'), 'data2':range(4)})# df1 以‘lkey’为键,df2以'rkey'为键print(pd.merge(df1,df2,left_on='left_key',right_on='right_key')) df1 = pd.DataFrame({'key':list('abcdfeg'), 'data1':range(7)})df2 = pd.DataFrame({'data2':range(1,6)}, index = list('abcde'))print('----------df1-------------')print(df1)print('----------df2-------------')print(df2)print('----------df1,df2,参数:left_on=\'key\',right_index=True-------------')print(pd.merge(df1,df2,left_on='key',right_index=True)) # df1采用key列值作为关联数据,df2采用index作为关联数据# left_index:为True时,第一个df以index为键,默认False# right_index:为True时,第二个df以index为键,默认False# 所以left_on, right_on, left_index, right_index可以相互组合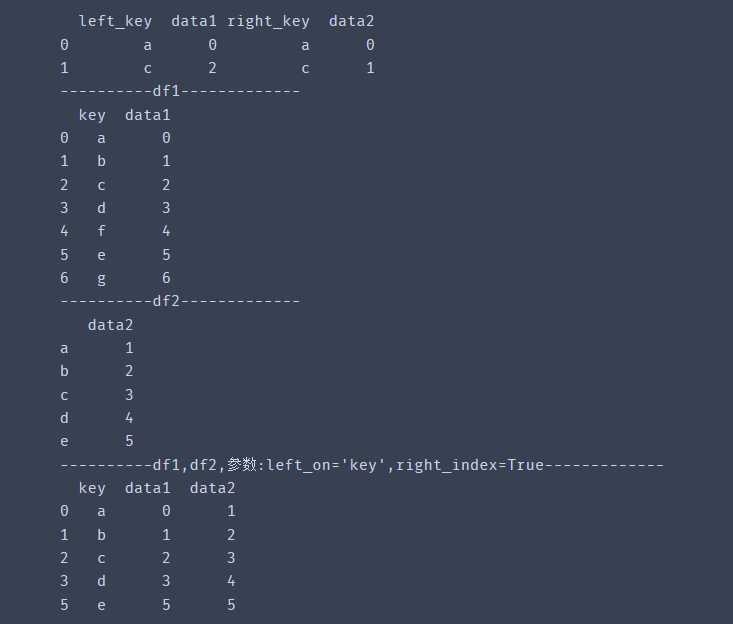
1.4 sort参数:排序
import pandas as pd# 参数sort df1 = pd.DataFrame({'key':list('baecd'), 'data1':[10,2,4,7,5]})df2 = pd.DataFrame({'key':list('abc'), 'data2':[11,2,33]})print('-------------df1-------------')print(df1)print('-------------df2-------------')print(df2)y1 = pd.merge(df1,df2, on = 'key', how = 'outer')y2 = pd.merge(df1,df2, on = 'key', sort=True, how = 'outer')print('-------------df1与df2全连接的结果-------------')print(y1)print('-------------df1与df2全连接并根据连接键排序的结果-------------')print(y2)# sort:按照字典顺序通过 连接键 对结果DataFrame进行排序。默认为False,设置为False会大幅提高性能print('-------------df1与df2全连接的结果根据data1排序-------------')# 也可以连接完毕后直接使用DataFrame的排序方法print(y2.sort_values('data1'))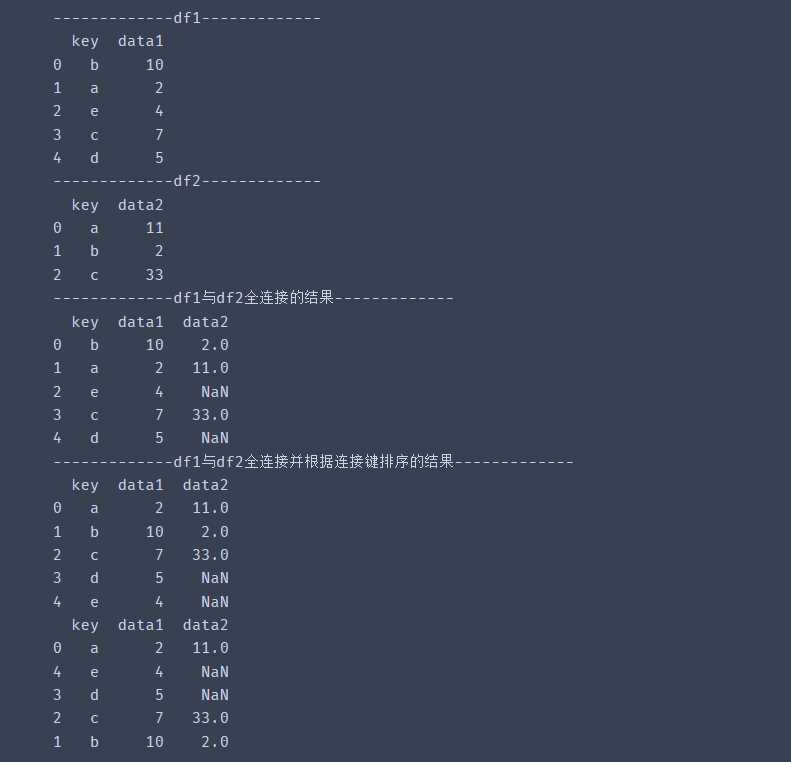
2.join
import pandas as pd# pd.join 通过索引连接left = pd.DataFrame({'A':['A01','A02','A03'], 'B':['B01','B02','B03'] },index=['k1','k2','k3'])right = pd.DataFrame({'C':['C01','C02','C03','C04'], 'D':['D01','D02','D03','D04'] },index=['k1','k2','k3','k4'])print(left,'-----------left-----------\n')print(left,'-----------right-----------\n')print(left.join(right),'-----------left.join(right)-----------\n')print(left.join(right,how='outer'),'-----------left.join(right)-----------\n')# 上述语句等价于 pd.merge(left, right, left_index=True, right_index=True, how='outer')df1 = pd.DataFrame({'key':list('bbacde'), 'data1':[1,3,5,7,2,4]})df2 = pd.DataFrame({'key':list('abc'), 'data2':[11,2,15] })print('-----------df1-----------')print(df1)print('-----------df2-----------')print(df2)# 指定参数suffixesprint('-' * 50)print(pd.merge(df1, df2, left_index=True, right_index=True, suffixes=('_1', '_2'))) # 用df1中的索引与df2['data2']中的索引连接print('-' * 50)# print(df2['data2'])print(df1.join(df2['data2']))left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'key': ['K0', 'K1', 'K0', 'K1']})right = pd.DataFrame({'C': ['C0', 'C1'], 'D': ['D0', 'D1']}, index=['K0', 'K1'])print(left)print(right)print(left.join(right, on = 'key'))# 等价于pd.merge(left, right, left_on='key', right_index=True, how='left', sort=False);# left的‘key’和right的index输出结果: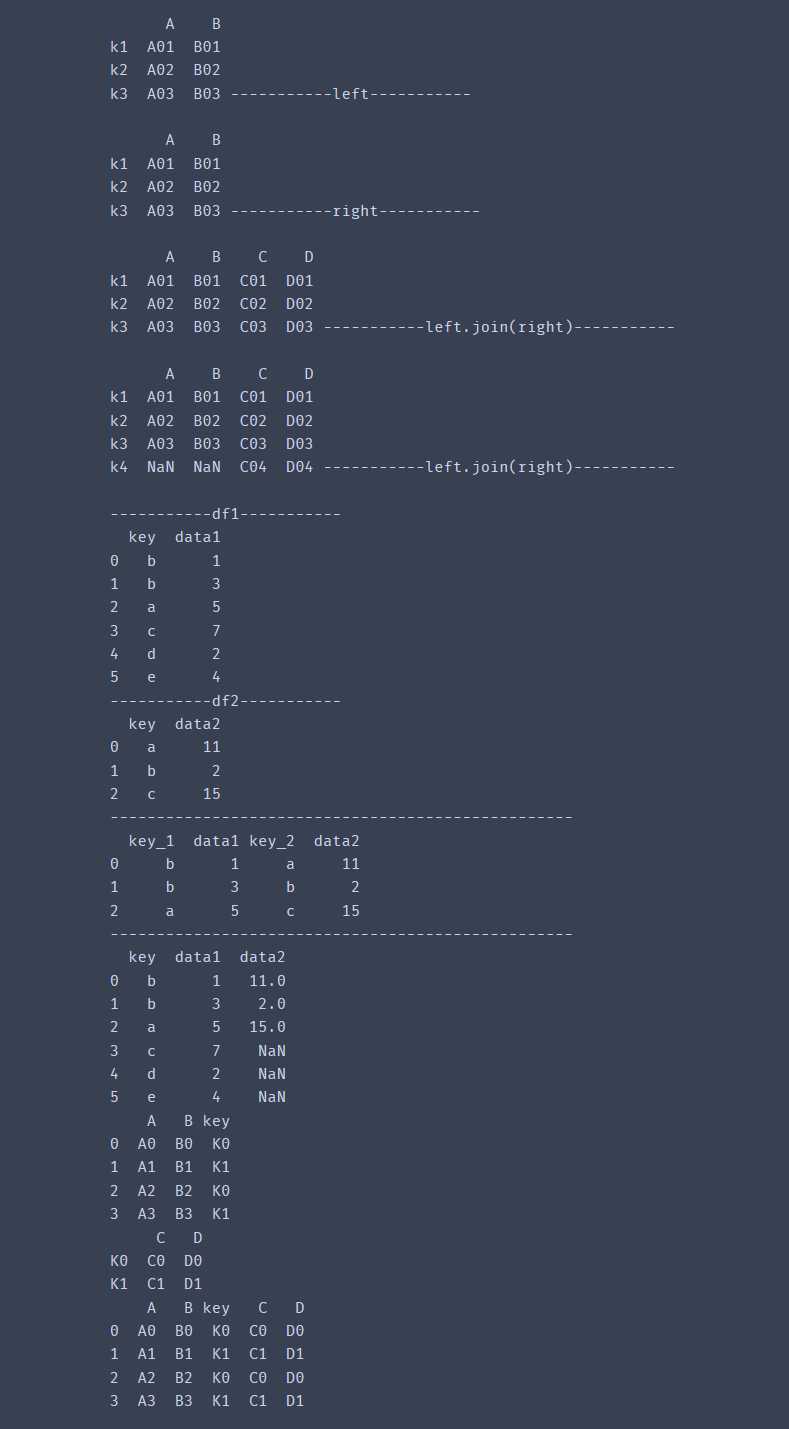
【Python数据分析】pands中的Merge与join
评论关闭