【经典爬虫案例】用Python爬取微博热搜榜!,本次爬取的目标是:微
【经典爬虫案例】用Python爬取微博热搜榜!,本次爬取的目标是:微
目录- 一、爬取目标
- 二、编写爬虫代码
- 2.1 前戏
- 2.2 获取cookie
- 2.3 请求页面
- 2.4 解析页面
- 2.5 转换热搜类别
- 2.6 保存结果
- 2.7 查看结果数据
- 三、获取完整源码
一、爬取目标
您好,我是@马哥python说,一名10年程序猿。
本次爬取的目标是: 微博热搜榜
分别爬取每条热搜的:
热搜标题、热搜排名、热搜类别、热度、链接地址。
下面,对页面进行分析。
经过分析,此页面没有XHR链接通过,也就是说,没有采用AJAX异步技术。
所以,只能针对原页面进行爬取。
二、编写爬虫代码
2.1 前戏
首先,导入需要用到的库:
import pandas as pd # 存入excel数据
import requests # 向页面发送请求
from bs4 import BeautifulSoup as BS # 解析页面
定义一个爬取目标地址:
# 目标地址
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
定义一个请求头:
# 请求头
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'Host': 's.weibo.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
# 定期更换Cookie
'Cookie': '换成自己的Cookie值'
}
其中,Cookie需要换成自己的Cookie值。
2.2 获取cookie
怎么查看自己的Cookie?
Chrome浏览器,按F12打开开发者模式,按照以下步骤操作:
- 选择网络:Network
- 选择所有网络:All
- 选择目标链接地址
- 选择头:Headers
- 选择请求头:Request Headers
- 查看cookie值
2.3 请求页面
下面,向页面发送请求:
r = requests.get(url, headers=header) # 发送请求
2.4 解析页面
接下来,解析返回的页面:
soup = BS(r.text, 'html.parser')
```
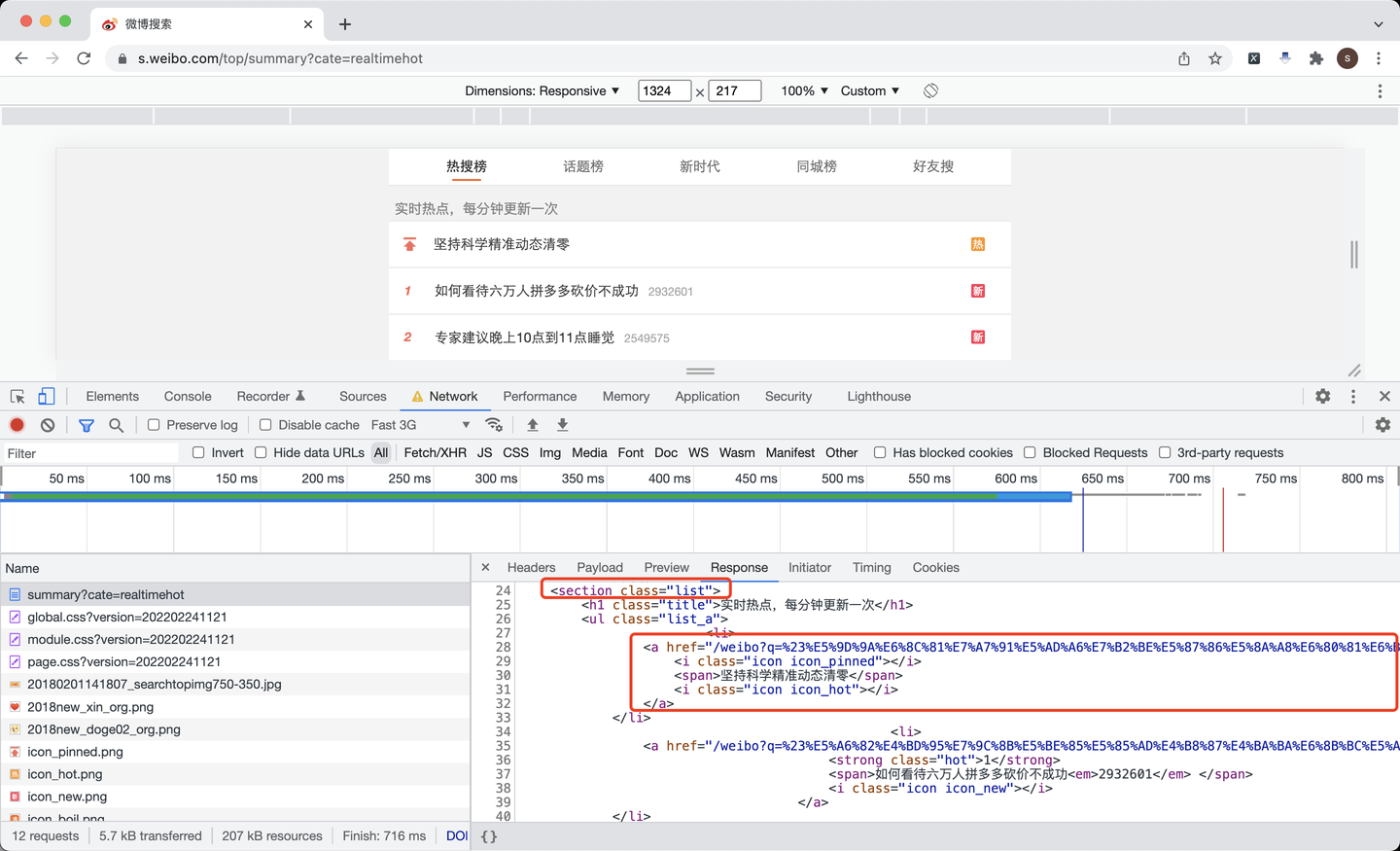
根据页面分析,每条热搜都放在了标签为section的、class值为list的数据里,里面每条热搜,又是一个a标签。
所以,根据这个逻辑,解析页面,以获取链接地址为例:
```python
items = soup.find('section', {'class': 'list'})
for li in items.find_all('li'):
# 链接地址
href = li.find('a').get('href')
href_list.append('https://s.weibo.com' + href)
页面其他元素,热搜标题、排名、热度、类别等获取代码,不再一一赘述。
2.5 转换热搜类别
其中,热搜类别这个元素需要注意,在页面上是一个个图标,背后对应的是class值,是个英文字符串,需要转换成对应的中文含义,定义以下函数进行转换:
def trans_icon(v_str):
"""转换热搜类别"""
if v_str == 'icon_new':
return '新'
elif v_str == 'icon_hot':
return '热'
elif v_str == 'icon_boil':
return '沸'
elif v_str == 'icon_recommend':
return '商'
else:
return '未知'
目前的转换函数包括了"新"、"热"、"沸"、"商"等类别。
我记得,微博热搜类别,是有个"爆"的,就是热度最高的那种,突然蹿升的最热的热点,爆炸性的。但是现在没有爆炸性新闻,所以我看不到"爆"背后的class值是什么。
后续如果有爆炸性热点,可以按照代码的逻辑,加到这个转换函数里来。
2.6 保存结果
依然采用我最顺手的to_excel方式,存入爬取的数据:
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
'热搜标题': text_list,
'热搜排名': order_list,
'热搜类别': type_list,
'热度': view_count_list,
'链接地址': href_list
}
)
df.to_excel('微博热搜榜.xlsx', index=False) # 保存结果数据
至此,整个爬取过程完毕。
2.7 查看结果数据
查看一下,保存到excel里的数据:
其中,第一条是置顶热搜,所以一共是 (1+50=51) 条数据。
演示视频:https://www.zhihu.com/zvideo/1488901467788070912
三、获取完整源码
get完整代码:【最新爬虫案例】用Python爬取微博热搜榜!
我是@马哥python说,持续分享python源码干货中!
相关内容
- Python 爬虫实战:驾驭数据洪流,揭秘网页深处,特别是
- 【python爬虫案例】用python爬豆瓣读书TOP250排行榜!,爬
- 【python爬虫案例】用python爬豆瓣电影TOP250排行榜!,首
- 【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!,爬
- 【爬虫案例】用Python爬大麦网任意城市的近期演出活动
- 爬虫小试牛刀(爬取学校通知公告),所以我的循环体
- 通过模仿学会Python爬虫(一):零基础上手,","")data
- 如何有效管理爬虫流量?,在航旅票务等行业,热
- 【K哥爬虫普法】一个人、一年半、挣了2000万!,案情
- python 爬虫某东网商品信息 | 没想到销量最高的是,
评论关闭