Python中文分词工具之结巴分词用法实例总结【经典案例】,
Python中文分词工具之结巴分词用法实例总结【经典案例】,
本文实例讲述了Python中文分词工具之结巴分词用法。分享给大家供大家参考,具体如下:
结巴分词工具的安装及基本用法,前面的文章《Python结巴中文分词工具使用过程中遇到的问题及解决方法》中已经有所描述。这里要说的内容与实际应用更贴近——从文本中读取中文信息,利用结巴分词工具进行分词及词性标注。
示例代码如下:
#coding=utf-8
import jieba
import jieba.posseg as pseg
import time
t1=time.time()
f=open("t_with_splitter.txt","r") #读取文本
string=f.read().decode("utf-8")
words = pseg.cut(string) #进行分词
result="" #记录最终结果的变量
for w in words:
result+= str(w.word)+"/"+str(w.flag) #加词性标注
f=open("t_with_POS_tag.txt","w") #将结果保存到另一个文档中
f.write(result)
f.close()
t2=time.time()
print("分词及词性标注完成,耗时:"+str(t2-t1)+"秒。") #反馈结果
其中t_with_splitter.txt文件内容如下:
帮客之家是国内专业的网站建设资源、脚本编程学习类网站,提供asp、php、asp.net、javascript、jquery、vbscript、dos批处理、网页制作、网络编程、网站建设等编程资料。
Python2.7.9平台运行后出现如下图所示的错误提示:
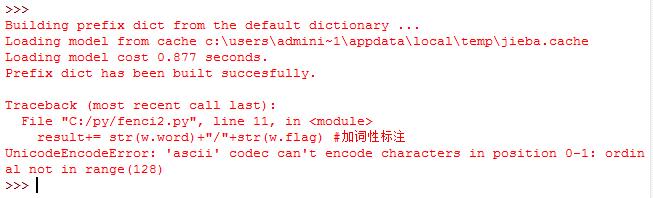
查阅相关资料后发现,需要在开头加上:
import sys reload(sys) sys.setdefaultencoding( "utf-8" )
最终代码应为:
#coding=utf-8
import jieba
import jieba.posseg as pseg
import time
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
t1=time.time()
f=open("t_with_splitter.txt","r") #读取文本
string=f.read().decode("utf-8")
words = pseg.cut(string) #进行分词
result="" #记录最终结果的变量
for w in words:
result+= str(w.word)+"/"+str(w.flag) #加词性标注
f=open("t_with_POS_tag.txt","w") #将结果保存到另一个文档中
f.write(result)
f.close()
t2=time.time()
print("分词及词性标注完成,耗时:"+str(t2-t1)+"秒。") #反馈结果
运行成功:

Editplus打开t_with_POS_tag.txt文件如下图所示:

更多关于Python相关内容可查看本站专题:《Python字典操作技巧汇总》、《Python字符串操作技巧汇总》、《Python常用遍历技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
相关内容
- Python生成随机数组的方法小结,python数组小结
- Python 列表(List) 的三种遍历方法实例 详解,pythonlist
- Python 实现随机数详解及实例代码,python随机数
- Python中标准模块importlib详解,pythonimportlib
- Python的时间模块datetime详解,pythondatetime详解
- Python实现将一个大文件按段落分隔为多个小文件的简单
- Python随机数用法实例详解【基于random模块】,pythonran
- Python外星人入侵游戏编程完整版,python外星人
- Python使用正则表达式实现文本替换的方法,
- 浅析python递归函数和河内塔问题,浅析python递归河内
评论关闭