爬取豆瓣短评之《后来的我们》,短评《后来的我们》,毕竟,影片的主题曲《我们
爬取豆瓣短评之《后来的我们》,短评《后来的我们》,毕竟,影片的主题曲《我们
《后来的我们》上映了,或许大家有点小期待吧。毕竟,影片的主题曲《我们》,早就虐哭了不少人。电影能否跟歌曲一样深入人心?怀着这样的一种心情,下面就来看一下它的影评如何吧。
1.抓数据
通过试探知道:豆瓣影评设置权限,没有登陆的话,只能够看到前面的几十条短评,并且登录的时候需要输入验证码。所以考虑使用selenium来获取数据。
登录时需要的验证码,通过保存图片,然后手动输入
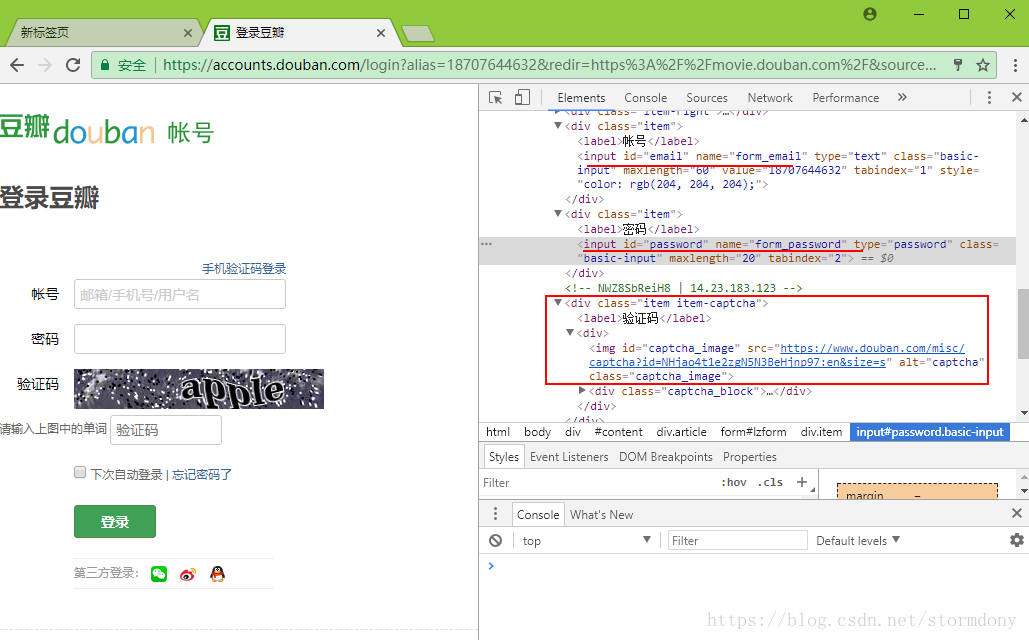
所以构造两个方法
# 登录
def login(url,username,password):
brower.get(url)
brower.find_element_by_css_selector('[class="nav-login"]').click()
name = brower.find_element_by_id('email')
name.clear()
name.send_keys(username)
pwd = brower.find_element_by_id('password')
pwd.clear()
pwd.send_keys(password)
pic_src = brower.find_element_by_id('captcha_image').get_attribute('src')
#调用获取验证码的方法
cap_value = get_yzm(pic_src)
yan_zheng_ma = brower.find_element_by_id('captcha_field')
yan_zheng_ma.clear()
yan_zheng_ma.send_keys(cap_value)
brower.find_element_by_css_selector('[class="btn-submit"]').click()
print('登陆成功')
# 获取验证码
def get_yzm(src):
print("正在保存验证码图片")
captchapicfile = "D:/pycharm/PycharmProjects/next_our/captcha.png"
urllib.request.urlretrieve(src, filename=captchapicfile)
print("请打开图片文件,查看验证码,输入单词......")
captcha_value = input()
return captcha_value
登陆成功之后,通过搜索框搜索《后来的我们》,进入详情页,随后进入短评列表
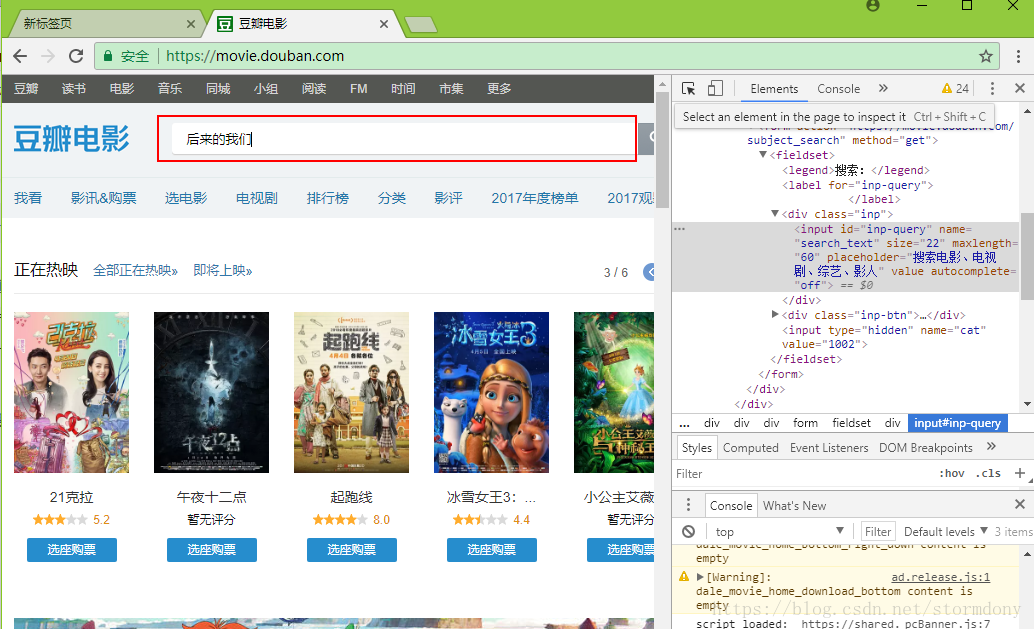
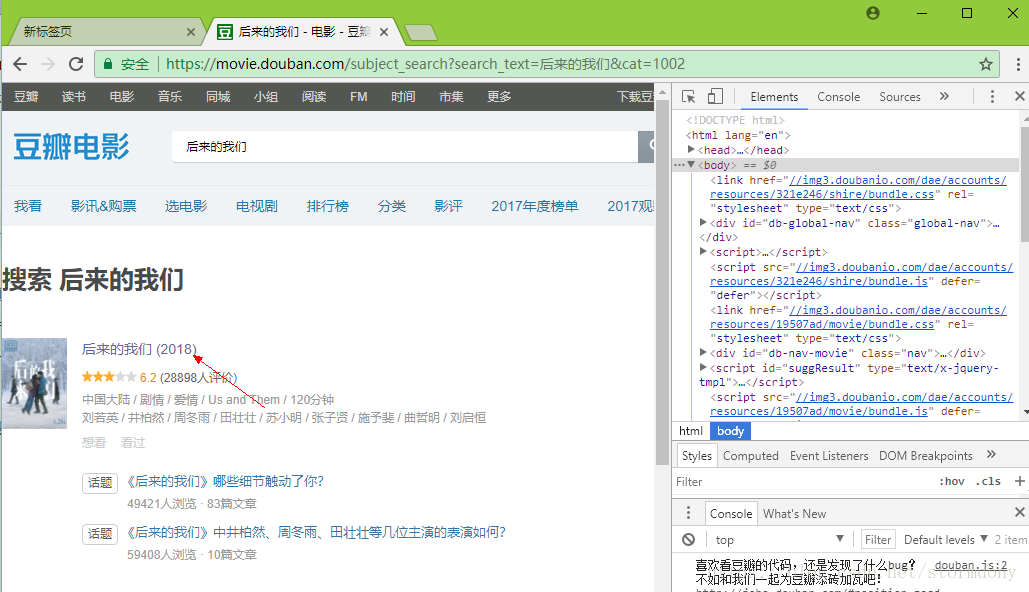
需要获取昵称,短评和赞同数
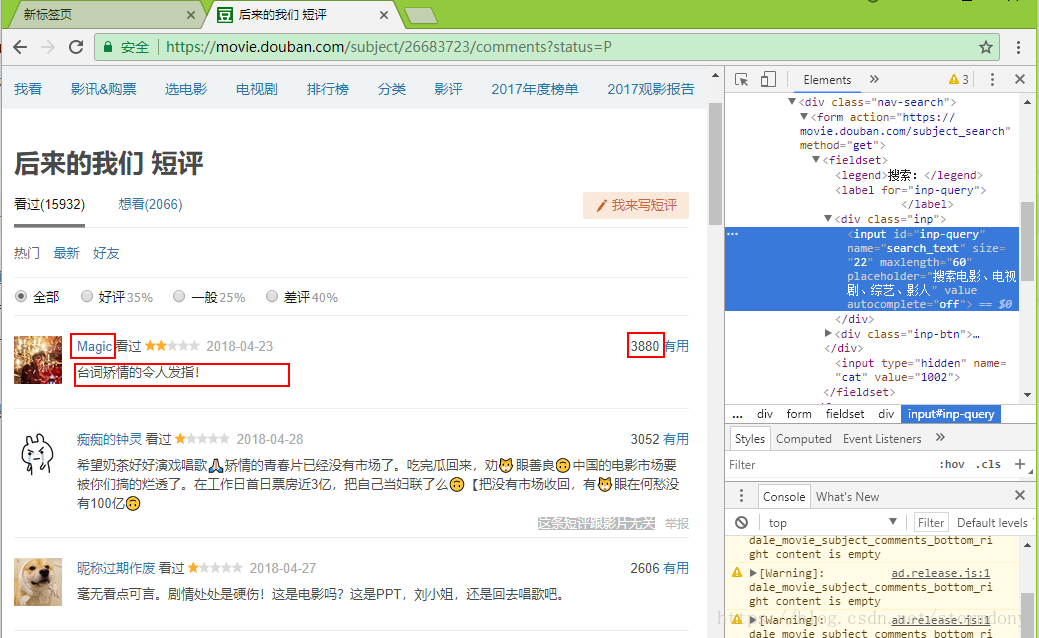
每一个步骤我们都构建一个方法
# 搜索电影
def seach(movie_name):
inp_query = brower.find_element_by_id('inp-query')
inp_query.clear()
inp_query.send_keys(movie_name)
submit = brower.find_element_by_css_selector('[type="submit"]')
submit.click()
sleep(1)
brower.find_element_by_xpath('//*[@id="root"]/div/div[2]/div[1]/div[1]/div[1]/div[1]/div/div[1]/a').click()
print("进入详情页")
# 进入短评列表
def into_comment():
brower.find_element_by_xpath('//*[@id="comments-section"]/div[1]/h2/span/a').click()
print("进入短评列表")
# 获取短评
def get_comment():
wait.until(lambda brower : brower.find_element_by_css_selector('[class="next"]'))
sleep(1)
for i in range(1,21):
comment = brower.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/p'.format(str(i))).text
comment_name = brower.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).text
votes = brower.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[1]/span'.format(str(i))).text
#构建字典
data = {
'comment': comment,
'comment_name': comment_name,
'votes': int(votes)
}
comments.insert_one(data)
print('*'*100)
print(data)
print('成功存入数据库')
还有最重要的一步就是,需要进行翻页,然后重新获取短评信息
#翻页
def next_page():
next = brower.find_element_by_css_selector('[class="next"]')
try:
next.click()
except:
logging.info("全部完成了")
ps:由于技术较渣,所以直接跳到最后一页,发现只有24页,所以直接使用循环了<~_~>
#使用PhantomJS
brower = webdriver.PhantomJS(executable_path="D:/phantomjs-2.1.1-windows/bin/phantomjs.exe")
wait = ui.WebDriverWait(brower,10)
# 数据库
client = pymongo.MongoClient('localhost',27017)
next_our = client['next_our']
comments = next_our['comments']
URL = 'https://movie.douban.com/'
username = '你的豆瓣账号'
password = '你的密码'
movie = '后来的我们'
if __name__=="__main__":
login(URL,username,password)
seach(movie)
into_comment()
for page in range(24):
get_comment()
next_page()
2.数据处理
在获取到数据之后,制作成图表,让我们更加直观的看到大体情况
series =[
{
'name':'评论点赞数',
'data':[i for i in vote_list],
'type':'column'
}
]
charts.plot(series,show='inline',options=dict(title=dict(text='评论点赞数')))
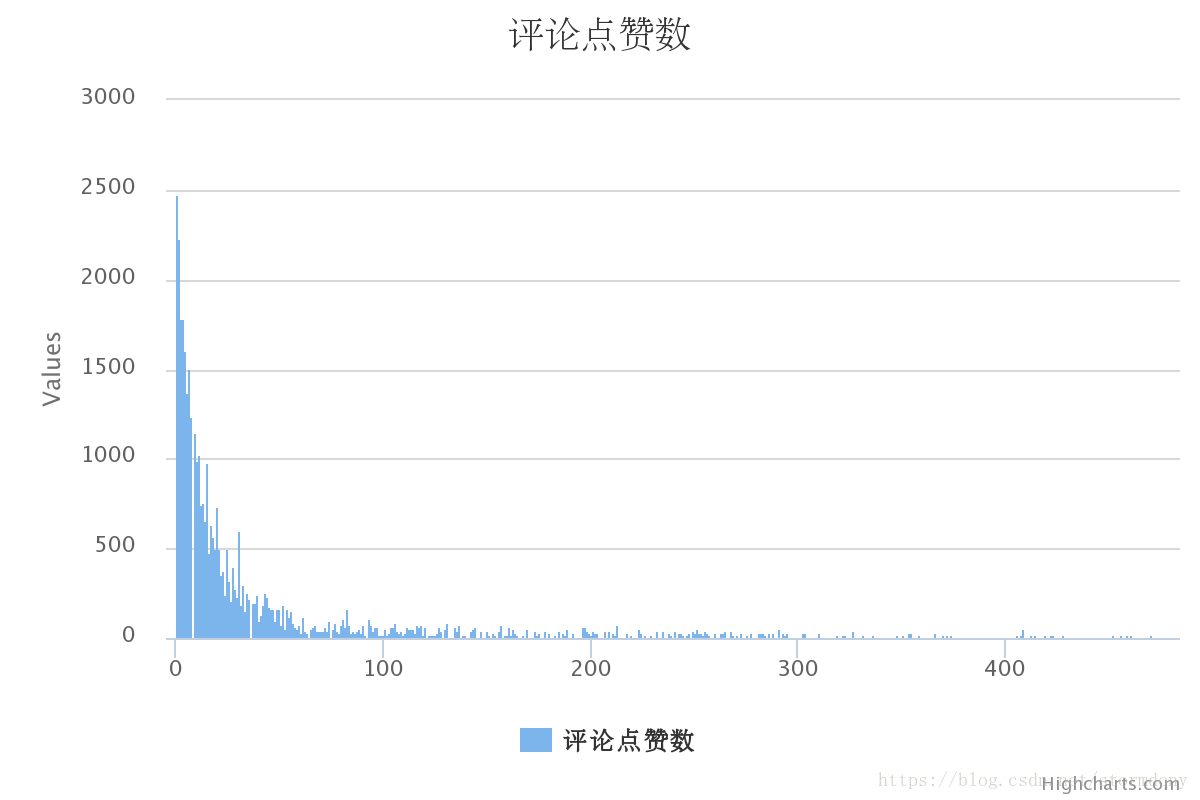
从图中可以看出短评中最受欢迎的大概有2500票,并且大部分集中在前排,(这是后面没有多少人看,所以点赞少?)
咳咳。。。前排很重要呀
接下来把所有的评论制作成云图
text=open('comment_list.txt', 'r',encoding='utf-8')
mytext=text.read()
cut = jieba.cut(mytext,cut_all=True)
split_cut ='/'.join(cut)
wc = WordCloud(background_color = "white", #设置背景颜色
max_words = 2000, #设置最大显示的字数
margin=5,
font_path="C:\\Windows\\Fonts\\STFANGSO.ttf",#不加这一句显示口字形乱码
max_font_size = 80, #设置字体最大值
random_state = 40, #设置有多少种随机生成状态,即有多少种配色方案
)
mword =wc.generate(split_cut)
plt.imshow(mword)
plt.axis("off")
plt.show()
得到下面的云图:

从图中看到,大部分在评论周冬雨、感慨我们后来没有故事的
ps:数据是4/29晚所爬取的
接下来统计一下赞同数前十的评论
| 昵称 | 获赞数 | 短评 |
|---|---|---|
| Magic | 2475 | 台词矫情的令人发指! |
| 华盛顿樱桃树 | 2230 | 最好的是演员,周冬雨完全开辟出自己的戏路。小井进步惊人,已长出美丽。最差的是编剧,没有一场完全连贯的戏,几乎都是攒的。 |
| 痴痴的钟灵 | 1784 | 希望奶茶好好演戏唱歌,矫情的青春片已经没有市场了。吃完瓜回来,劝眼善良,中国的电影市场要被你们搞的烂透了。在工作日首日票房近3亿,把自己当妇联了么,【把没有市场收回,有,眼在何愁没有100亿. |
| 昵称过期作废 | 1785 | 毫无看点可言。剧情处处是硬伤!这是电影吗?这是PPT,刘小姐,还是回去唱歌吧。 |
| 末药煎肉塔 | 1601 | 现在还把北京设定为梦想之城的,大概受众也是瞄准了小镇青年吧(多次冲北京喊话真是挺尴尬的)。剧情拖太长,唯一的泪点还是田壮壮演的老爸,周冬雨老演这种角色不会腻吗? |
| xiaoning | 1373 | 真的很讨厌卖情怀的电影,而且还有一个不是很有才华的歌手做导演,要不是主题曲我应该都不会想看。(留言说我收钱黑的,老子收了一分黑钱我多的钱都亏出去行了吧,就这尴尬的台词乱拼凑的故事是在看ppt吗还用收钱黑,我真是谢你们大爷了,你不用管我觉得谁有才华,反正这位文青女导演还真不是) |
| 张无B | 1508 | 刘若英对着镜头唱一遍后来我都觉得比这片子感动。 |
| 葡萄猪不爱睡觉 | 1238 | 从形式内容到档期营销,统统都是模仿当年的致青春,致青春票房年度第二,这部最终估计也不会差 |
| 糖炒荔枝 | 1146 | 在我眼里第二个无问西东,投机取巧,毫无才华,对不起 |
| 尼克Lui | 995 | 垃圾做作的电影 这么多年了还在不断的重复搞这种烂片 大晚上被抓住票房造假 哈哈哈哈哈哈 垃圾怎么包装也是垃圾! |
ps:以上评论均来自豆瓣影评
3.总结
或许是主题曲提前预热了市场,让观众的期望值变高了,《后来的我们》在豆瓣上的评分只有6.2分,并且现在又出现了退票事件。
单就电影来说,感觉还是可以的。或许是豆瓣的用户眼光有点高了。
爱情有一种结局,是后来的我们,只能从情侣变成爱了很久的朋友。
电影有句很扎心的文案,“再后来,我什么都有了,却独独没有了我们”。
希望我们好好珍惜。
相关内容
- 5 个用 Python 编写 web 爬虫的方法,python爬虫,通过实现一
- 爬虫进阶:反反爬虫技巧,进阶反爬虫技巧,未经许可,
- python爬虫抓网页的总结,python爬虫抓,学用python也有3个
- 两种python 判断网页编码的方法,python判断网页编码,这
- python 网络爬虫,python爬虫,[Python]代码#F
- Python 图片蜘蛛人,,[Python]代码#c
- Python脚本提取谷歌音乐搜索结果,python谷歌,[Python]代码
- 爬取千万淘宝商品的python脚本,淘宝商品python脚本,分享
- 网易云很多歌曲都要版权?要VIP?在Python面前没有限制
- Python第三方模块tesserocr安装,pythontesserocr,介绍在爬虫过
评论关闭