OSINT + Python = 自定义黑客,osintpython, Python是一个很棒
OSINT + Python = 自定义黑客,osintpython, Python是一个很棒
去年5月10号和11号,计算机取证专家(Computer Forensic Expert)课程在Reus(西班牙)由专业司法软件鉴定协会(ANTPJI)主持举行,我是其中一个成员,也是一个讲师,在那次课程中我有幸做了我的两个爱好的演讲,分别是Python 以及 OSINT (开源情报)。
Python是一个很棒的语言,可以通过许多的库,迅速的开发出各种各样强大的应用程序,去扮演漏洞探测,逆向工程,web分析工具等等角色。毫无疑问对于任何安全专家它都是一个有用的知识。
Internet是巨大的,它收容了所有不可思议的信息,这也是为什么OSINT技术对搜集,分析和呈现这些信息是至关重要的。
在这个课程中,我觉得与会者对学习怎样开发出简单的工具(脚本)是很感兴趣的,这使得他们可以通过使用Python,通过每个有特定目标的一系列实践锻炼,去执行OSINT工作。
代码与描述可以在VULNEX网站 获得。
注意:我删除了脚本中的Google Hacking 查询 ,读者可以插入自己的查询。
工具 #1
目标: 在LinkedIn上使用Google Custom Search API搜索 ANTPJI成员。
这些脚本非常简单,以不同的方式做了同样的事情。第一个使用了 Google API 客户端,第二个使用了神奇的 Requests 库。
在这些脚本中,我们使用了一些Google Hacking,以便在LinkedIn上找到协会的成员。
# File: ex1_a.py
# Date: 05/14/13
# Author: Simon Roses Femerling
# Desc: Basic Google Hacking
#
# VULNEX (C) 2013
# www.vulnex.com
import const
from apiclient.discovery import build
import pprint
# your google hacking query
query=''
query_params=''
doquery=query+query_params
service = build("customsearch","v1",developerKey=const.cse_token)
res = service.cse().list(
q=doquery,
cx=const.cse_id,
num=10).execute()
pprint.pprint(res)
# VULNEX EOF
# File: ex1_b.py # Date: 05/14/13 # Author: Simon Roses Femerling # Desc: Simple Google Hacking # # VULNEX (C) 2013 # www.vulnex.com import requests import json import urllib import const site="https://www.googleapis.com/customsearch/v1?key=" # Your Google Hacking query query='' query_params='' url=site+const.cse_token+"&cx="+const.cse_id+"&q=" + urllib.quote(query+query_params) response = requests.get(url) print json.dumps(response.json,indent=4) # VULNEX EOF
执行任意一个脚本,就可以得到如下结果:
现在还不是很有趣 
工具 #2
目标: 使用Google Custom Search API 获得 ANTPJI 成员 LinkedIn档案中的照片。
下面的脚本获取协会成员在LinkedIn的照片,并提取出图片元数据信息  这个脚本生成了一个包含所有照片的HTML页面。
这个脚本生成了一个包含所有照片的HTML页面。
使用的库: Google API 客户端, PIL, Requests 和 Markup。
# File: ex2.py
# Date: 05/14/13
# Author: Simon Roses Femerling
# Desc: Download picture and extract metadata
#
# VULNEX (C) 2013
# www.vulnex.com
import const
from apiclient.discovery import build
import pprint
import os
from PIL import Image
from StringIO import StringIO
from PIL.ExifTags import TAGS
import requests
import markup
def do_query(istart=0):
if istart == 0:
res = service.cse().list(
q=doquery,
cx=const.cse_id,
num=10).execute()
else:
res = service.cse().list(
q=doquery,
cx=const.cse_id,
num=10,
start=istart).execute()
return res
pic_id=1
do_stop=10
cnt=1
page=markup.page()
# Set page title
page.init(title="ANTPJI OSINT")
page.h1("ANTPJI OSINT")
# Set output directory
out_dir = "pics_gepl"
# Your Google Hacking query
query=''
query_params=''
doquery=query+query_params
service = build("customsearch","v1",developerKey=const.cse_token)
if not os.path.exists(out_dir):
os.makedirs(out_dir)
res=[]
while True:
if cnt==1:
res = do_query()
else:
if not res['queries'].has_key("nextPage"): break
res = do_query(res['queries']['nextPage'][0]['startIndex'])
cnt+=1
if cnt > do_stop: break
if res.has_key("items"):
for item in res['items']:
name=""
if not item.has_key('pagemap'): continue
if not item['pagemap'].has_key('hcard'): continue
hcard = item['pagemap']['hcard']
for card in hcard:
pic_url=""
if 'title' in card:
if 'fn' in card: name = card['fn']
if 'photo' in card: pic_url = card['photo']
if pic_url != "":
image = requests.get(pic_url)
pic_n = os.path.join(out_dir,"%s.jpg") % pic_id
file = open(pic_n,"w")
pic_id+=1
try:
i = Image.open(StringIO(image.content))
if hasattr(i,"_getexif"):
ret = {}
info = i._getexif()
if info:
for k,v in info.items():
decode = TAGS.get(k,v)
ret[decode] = v
print ret
i.save(file,"JPEG")
page.p(name.encode('ascii','ignore'))
page.img(src=pic_n)
page.br()
page.br()
except IOError, e:
print "error: %s" % e
file.close()
# Set your output filename
with open('index_gepl.html','w') as fp:
fp.write(str(page))
# VULNEX EOF
结果是:
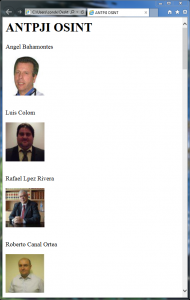
通过很少的数行代码,我们获得了一个有趣的工具。
工具 #3
目标: LinkedIn上 ANTPJI 成员的关系是怎样的 ?
通过这个脚本,我们搜寻LinkedIn上协会成员之间的关系,并创建了一个与此相关的图。
使用的库: Google API 客户端, NetworkX 和 Matplotlib。
# File: ex3.py
# Date: 05/14/13
# Author: Simon Roses Femerling
# Desc: Build graph from profiles
#
# VULNEX (C) 2013
# www.vulnex.com
import const
from apiclient.discovery import build
import networkx as nx
import matplotlib.pyplot as plt
def do_query(istart=0):
if istart == 0:
res = service.cse().list(
q=doquery,
cx=const.cse_id,
num=10).execute()
else:
res = service.cse().list(
q=doquery,
cx=const.cse_id,
num=10,
start=istart).execute()
return res
do_stop=10
cnt=1
# Your Google Hacking query here
query=''
query_params=''
doquery=query+query_params
service = build("customsearch","v1",developerKey=const.cse_token)
G=nx.DiGraph()
res=[]
while True:
if cnt==1:
res = do_query()
else:
if not res['queries'].has_key("nextPage"): break
res = do_query(res['queries']['nextPage'][0]['startIndex'])
cnt+=1
if cnt > do_stop: break
if res.has_key("items"):
for item in res['items']:
name=""
if not item.has_key('pagemap'): continue
if not item['pagemap'].has_key('hcard'): continue
hcard = item['pagemap']['hcard']
for card in hcard:
if 'title' in card:
if 'fn' in card: name = card['fn']
G.add_edge(name,card["fn"])
plt.figure(figsize=(30,30))
nx.draw(G)
# Set your output filename
plt.savefig('antpji_rela_map.png')
# VULNEX EOF
这就是生成的图片:

工具 #4
目标: 协会的Twitter帐号有什么热点 ?
这个脚本下载了协会帐号的最新tweets,并生成了一个tag云。对快速的查看他们在讨论什么很有用。
使用的库: Requests, pytagcloud。
# File: ex4.py
# Date: 05/14/13
# Author: Simon Roses Femerling
# Desc: Create word cloud
#
# VULNEX (C) 2013
# www.vulnex.com
import requests
import json
import urllib
import const
from pytagcloud import create_tag_image, make_tags
from pytagcloud.lang.counter import get_tag_counts
site="http://search.twitter.com/search.json?q="
# Your query here
query=""
url=site+urllib.quote(query)
response = requests.get(url)
tag = []
for res in response.json["results"]:
tag.append(res["text"].encode('ascii','ignore'))
text = "%s" % "".join(tag)
tags = make_tags(get_tag_counts(text),maxsize=100)
# Set your output filename
create_tag_image(tags,"antpji_word_cloud.png", size=(600,500), fontname="Lobster")
# VULNEX EOF
这就是 tag 云:

工具 #5
目标: Twitter上的 ANTPJI用户名在社交网络网站上存在吗 ?
下面的脚本提取出协会的Twitter上发布或提到的用户名,并在160个社交网络网站上进行查询。
使用的库: Requests。
# File: ex5.py
# Date: 05/14/13
# Author: Simon Roses Femerling
# Desc: Check usernames on 160 social network sites
#
# VULNEX (C) 2013
# www.vulnex.com
import requests
import json
import urllib
import const
import pprint
site="http://search.twitter.com/search.json?q="
# Your query here
query=""
url=site+urllib.quote(query)
print "Recolectando alias en Twitter: %s\n" % query
response = requests.get(url)
users = []
for res in response.json["results"]:
if res.has_key('to_user'):
if not res['to_user'] in users: users.append(str(res["to_user"]))
if res.has_key('from_user'):
if not res['from_user'] in users: users.append(str(res["from_user"]))
print "ALIAS-> %s" % users
print "\nComprobrando alias en 160 websites\n"
for username in users:
for service in const.services:
try:
res1 = requests.get('http://checkusernames.com/usercheckv2.php?target=' + service + '&username=' + username, headers={'X-Requested-With': 'XMLHttpRequest'}).text
if 'notavailable' in res1:
print ""
print username + " -> " + service
print ""
except Exception as e:
print e
# VULNEX EOF
结果像下面这样:
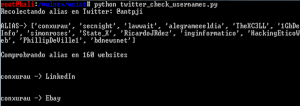
工具 #6
目标: 我们能从ANTPJI 照片中提取出元数据吗?
这个脚本从Google下载有关ANTPJI的照片,并提取出元数据。
使用的库: Requests, PIL 和 Markup。
# File: ex6.py
# Date: 05/14/13
# Author: Simon Roses Femerling
# Desc: Download pictures from Google and extract metadata
#
# VULNEX (C) 2013
# www.vulnex.com
import const
from apiclient.discovery import build
import pprint
import os
from PIL import Image
from StringIO import StringIO
from PIL.ExifTags import TAGS
import requests
import markup
def do_query(istart=0):
if istart == 0:
res = service.cse().list(
q=doquery,
cx=const.cse_id,
num=10).execute()
else:
res = service.cse().list(
q=doquery,
cx=const.cse_id,
num=10,
start=istart).execute()
return res
pic_id=1
do_stop=10
cnt=1
page=markup.page()
# Set your page title
page.init(title="ANTPJI OSINT")
page.h1("ANTPJI OSINT")
# Set output directory
out_dir = "pics_gepl"
# Define your Google hacking query here
query=''
query_params=''
doquery=query+query_params
service = build("customsearch","v1",developerKey=const.cse_token)
if not os.path.exists(out_dir):
os.makedirs(out_dir)
res=[]
while True:
if cnt==1:
res = do_query()
else:
if not res['queries'].has_key("nextPage"): break
res = do_query(res['queries']['nextPage'][0]['startIndex'])
cnt+=1
if cnt > do_stop: break
if res.has_key("items"):
for item in res['items']:
name=""
if not item.has_key('pagemap'): continue
if not item['pagemap'].has_key('hcard'): continue
hcard = item['pagemap']['hcard']
for card in hcard:
pic_url=""
if 'title' in card:
if 'fn' in card: name = card['fn']
if 'photo' in card: pic_url = card['photo']
if pic_url != "":
image = requests.get(pic_url)
pic_n = os.path.join(out_dir,"%s.jpg") % pic_id
file = open(pic_n,"w")
pic_id+=1
try:
i = Image.open(StringIO(image.content))
if hasattr(i,"_getexif"):
ret = {}
info = i._getexif()
if info:
for k,v in info.items():
decode = TAGS.get(k,v)
ret[decode] = v
print ret
i.save(file,"JPEG")
page.p(name.encode('ascii','ignore'))
page.img(src=pic_n)
page.br()
page.br()
except IOError, e:
print "error: %s" % e
file.close()
# Set your output filename
with open('index_gepl.html','w') as fp:
fp.write(str(page))
# VULNEX EOF
一图胜千言!
正如从这篇文章看到的,通过使用一点Python语句,就能收集到关于个人或者集体的大量的信息,因此我们可以很容易的写出复杂的OSINT工具。
如果你想让我深入任何Python 和 OSINT的话题,请告诉我 
你使用什么样的 OSINT工具?
– Simon Roses Femerling
参考
- 感谢RaiderSec 的人们,在哪儿我建立了我的脚本代码。 使用APIs的自动化开源情报(OSINT)
- NSA – 揭秘网络:互联网调查入门 (译注:NSA美国国家安全局 National Security Agency)
- NATO OSINT 手册 (译注:NATO北大西洋公约组织 North Atlantic Treaty Organization)
相关内容
- 暂无相关文章
评论关闭