Python爬虫: 抓取One网页上的每日一话和图,python爬虫,嗯,最近看到One这个A
Python爬虫: 抓取One网页上的每日一话和图,python爬虫,嗯,最近看到One这个A
先说下需求:
最近打算搜集点源数据,丰富下生活。嗯,最近看到One这个APP蛮好的。每天想你推送一张图和一段话。很喜欢,简单不复杂。而我想要把所有的句子都保存下来,又不想要每个页面都去手动查看。因此,就有了Python。之前有点Python基础,不过没有深入。现在也没有深入,用哪学哪吧。
网站的内容是这样的,我想要图片和这段话:
 (一)
(一)
一台MAC电脑
(二)Python环境搭建(所有命令都是在terminal中输入的)
- 安装homebrew:
Shell/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
- 安装pip:这里我在terminal中输入
python -v,homebrew会自动帮你升级Python到2.7.11版本的。2.7.11版本里自带了pip工具。 - 安装virtualenv:
Shellpip install virtualenv
- 安装request和beautifulsoup4:
Shellpip install requests beautifulsoup4
参考这里
(三)分析
目的:找出三个内容所在的网页标签的位置,然后将它们提取出来。
网址:http://wufazhuce.com/one/1293
谷歌浏览器,右键->显示网页源代码,然后就会弹出一堆HTML的东西了。这样的:
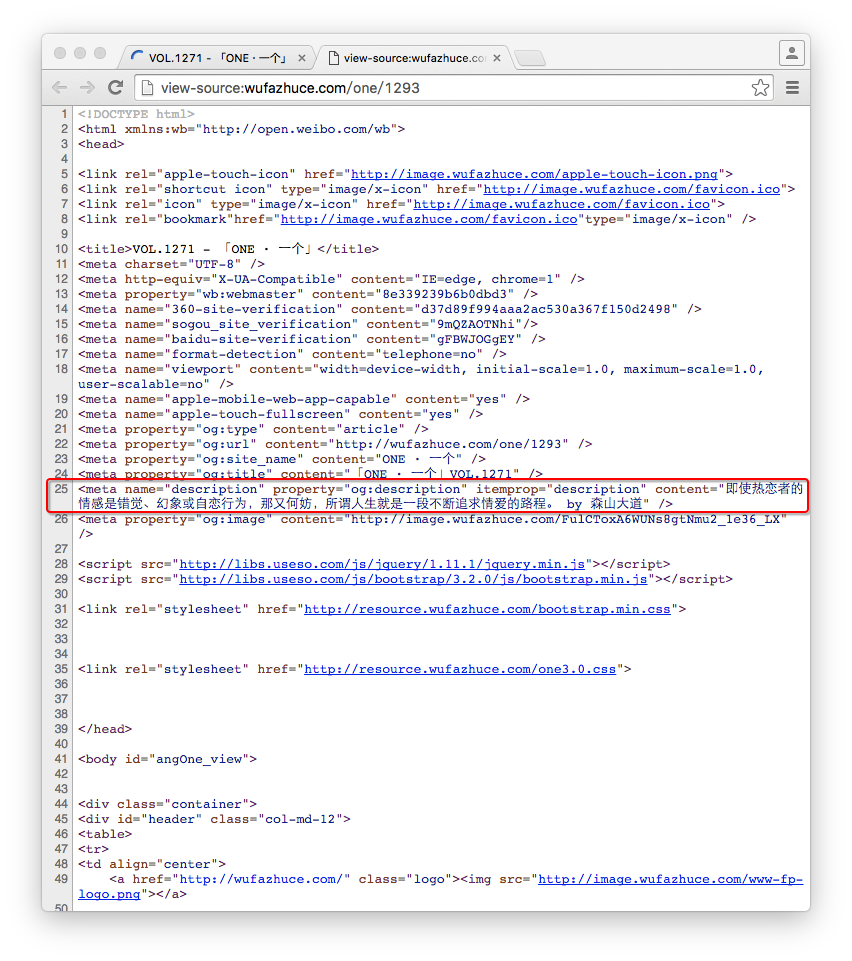 网页源文件
网页源文件
我想要的内容是这段话:“即使热恋者的情感是错觉、幻象或自恋行为,那又何妨,所谓人生就是一段不断追求情爱的路程。 by 森山大道”。它在图中画红线的地方。在<heda>标签里的<meta>中,之后会用到,先往下看。
图片的链接在哪里?显然不在<head>中,往下找,然后就在<body>中,发现2处和图片类似的链接。看图
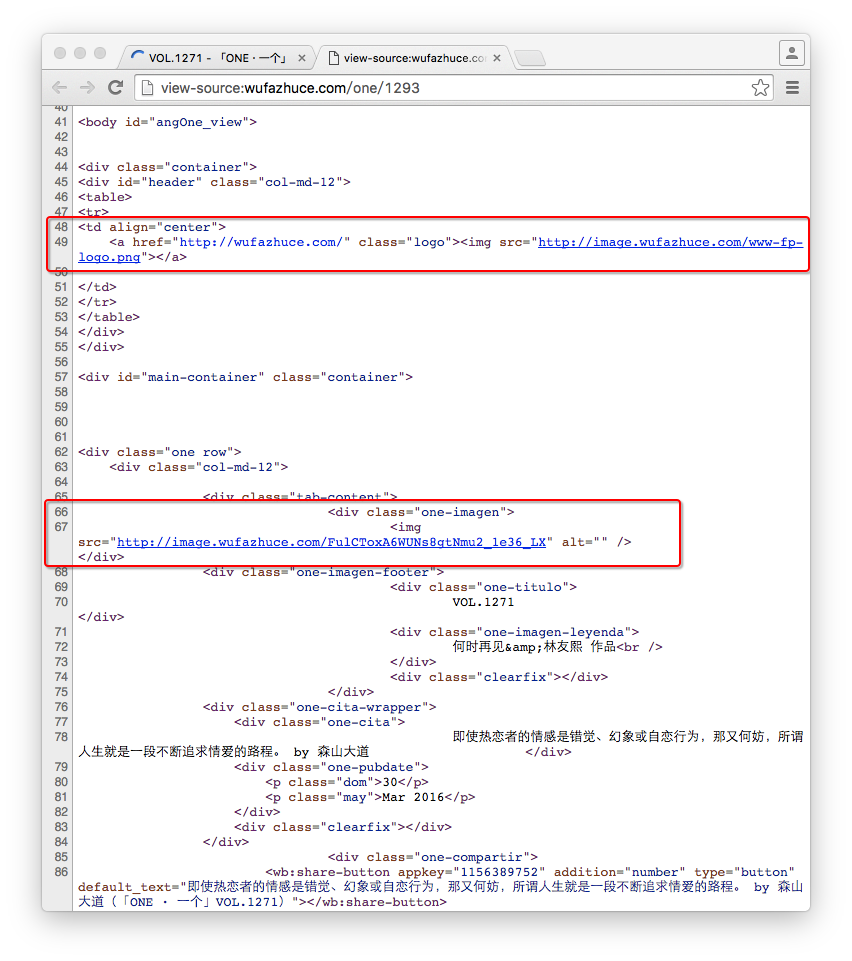 图片链接地址
图片链接地址
哪个链接是呢,点击去,发现后一个链接,也就是67行这个img标签的链接是。
然后,我还想知道哪一天的图和文字。嗯,在回到<head>标签里,很明显有个<title>,里面的东西就是我们要的。这样:
<title>VOL.1271 – 「ONE · 一个」</title>
(四)python编码
想要抓取网页上的内容,又不想自己去解析HTML,只好求助万能的Google了。然后就找到了上面的链接。主要有两个工具:request加载网页,BeautifulSoup4解析HTML。
首先,抓取我们需要的哪三个内容:
进入python环境,然后敲入下面的代码:
import requests
import bs4
response = requests.get('http://wufazhuce.com/one/1295')
soup = bs4.BeautifulSoup(response.text,"html.parser")
这样,就可以将网页信息存储到soup中了。你可以敲入print soup试试。
接下来,我们获得<title>VOL.1271 – 「ONE · 一个」</title>中的数字1271。怎么获得呢,beautifulsoup4教程,提供了很好的方法,可以通过tag查找得到title的内容,然后截取字符串。termianl中输入:
soup.title.string[3:7]
title是tag值,string是tag=title的字符串的值,也就是<title></title>之间的值,因为只有一个<title>tag,所以不用做判断,直接获取即可。
接下来,获取一段话。
 这段话在<meta>
这段话在<meta>
for meta in soup.select('meta'):
if meta.get('name') == 'description':
print meta.get('content')
接下来,在两个img标签中,查找第2个img标签标定的链接。这里通过find_all方法,它可以查找所有的符合要求的标签。
soup.find_all('img')[1]['src']
这样,我们就把所需要的信息找出来了。
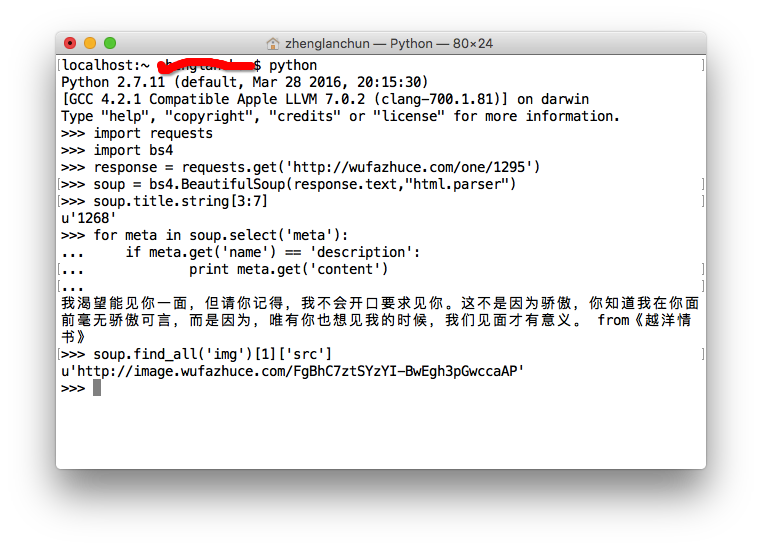 终端示例
终端示例
等等,之后我们还需要并发和保存文件。在此之前,先来看点别的。map函数有两个参数,一个是函数,一个是序列。将序列的每个值,作为参数传递给函数,返回一个列表。参考这里
示例:
def echoInfo(num):
return num
data = map(echoInfo, range(0,10))
print data
结果: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
然后并发, python可以跨平台使用,自身提供了多进程支持模块:multiprocessing。而pool可以用来创建大量的子进程。
保存数据到文件。这里我们是吧数据解析后存储到字典中,然后序列化为JSON模型,最后保存到文件的。
即:字典->JSON模型->存储到文件。
字典->JSON模型,使用的是JSON模块的json.dumps方法,该方法有一个参数,参数为字典,返回值是JSON字符串。
JSON模型->文件,使用的是json.load方法,可以将JSON存储到文件中。
全部的代码示例如下:
import argparse
import re
from multiprocessing import Pool
import requests
import bs4
import time
import json
import io
root_url = 'http://wufazhuce.com'
def get_url(num):
return root_url + '/one/' + str(num)
def get_urls(num):
urls = map(get_url, range(100,100+num))
return urls
def get_data(url):
dataList = {}
response = requests.get(url)
if response.status_code != 200:
return {'noValue': 'noValue'}
soup = bs4.BeautifulSoup(response.text,"html.parser")
dataList["index"] = soup.title.string[4:7]
for meta in soup.select('meta'):
if meta.get('name') == 'description':
dataList["content"] = meta.get('content')
dataList["imgUrl"] = soup.find_all('img')[1]['src']
return dataList
if __name__=='__main__':
pool = Pool(4)
dataList = []
urls = get_urls(10)
start = time.time()
dataList = pool.map(get_data, urls)
end = time.time()
print 'use: %.2f s' % (end - start)
jsonData = json.dumps({'data':dataList})
with open('data.txt', 'w') as outfile:
json.dump(jsonData, outfile)
相关内容
- 暂无相关文章
评论关闭