Python网络爬虫二三事,python爬虫,在此作为初出茅庐的数据小
Python网络爬虫二三事,python爬虫,在此作为初出茅庐的数据小

1 前言
作为一名合格的数据分析师,其完整的技术知识体系必须贯穿数据获取、数据存储、数据提取、数据分析、数据挖掘、数据可视化等各大部分。在此作为初出茅庐的数据小白,我将会把自己学习数据科学过程中遇到的一些问题记录下来,以便后续的查阅,同时也希望与各路同学一起交流、一起进步。刚好前段时间学习了Python网络爬虫,在此将网络爬虫做一个总结。
2 何为网络爬虫?
2.1 爬虫场景
我们先自己想象一下平时到天猫商城购物(PC端)的步骤,可能就是打开浏览器==》搜索天猫商城==》点击链接进入天猫商城==》选择所需商品类目(站内搜索)==》浏览商品(价格、详情参数、评论等)==》点击链接==》进入下一个商品页面,……这样子周而复始。当然这其中的搜索也是爬虫的应用之一。简单讲,网络爬虫是类似又区别于上述场景的一种程序。
2.2 爬虫分类
- 分类与关系
一般最常用的爬虫类型主要有通用爬虫和聚焦爬虫,其中聚焦爬虫又分为浅聚焦与深聚焦,三者关系如下图: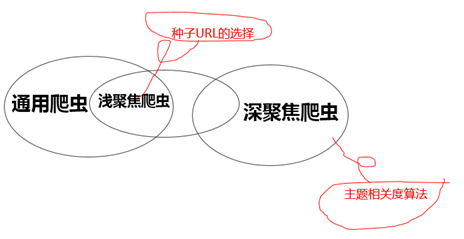
- 区别
通用爬虫与聚焦爬虫的区别就在有没有对信息进行过滤以尽量保证只抓取与主题相关的网页信息。 - 聚焦爬虫过滤方法
- 浅聚焦爬虫
选取符合目标主题的种子URL,例如我们定义抓取的信息为招聘信息,我们便可将招聘网站的URL(拉勾网、大街网等)作为种子URL,这样便保证了抓取内容与我们定义的主题的一致性。 - 深聚焦爬虫
一般有两种,一是针对内容二是针对URL。其中针对内容的如页面中绝大部分超链接都是带有锚文本的,我们可以根据锚文本进行筛选;针对URL的如现有链接http://geek.csdn.net/news/detail/126572 ,该链接便向我们透漏主题是新闻(news)。
- 浅聚焦爬虫
2.3 爬虫原理
总的来说,爬虫就是从种子URL开始,通过 HTTP 请求获取页面内容,并从页面内容中通过各种技术手段解析出更多的 URL,递归地请求获取页面的程序网络爬虫,总结其主要原理如下图(其中红色为聚焦爬虫相对通用爬虫所需额外进行步骤):
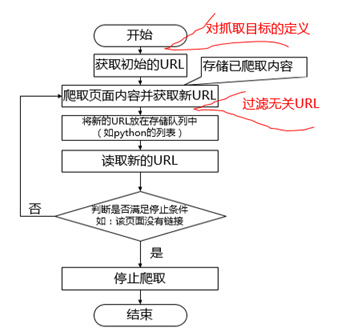
当然,如果对于网络爬虫原理细节有兴趣的同学可参考一下两篇博文:
网络爬虫基本原理(一)
网络爬虫基本原理(二)
2.4 爬虫应用
网络爬虫可以做的事情很多,如以下列出:
- 搜索引擎
- 采集数据(金融、商品、竞品等)
- 广告过滤
- ……
其实就我们个人兴趣,学完爬虫我们可以看看当当网上哪种技术图书卖得比较火(销量、评论等信息)、看某个在线教育网站哪门网络课程做得比较成功、看双十一天猫的活动情况等等,只要我们感兴趣的数据,一般的话都可以爬取得到,不过有些网站比较狡猾,设置各种各样的反扒机制。总而言之,网络爬虫可以帮助我们做很多有趣的事情。
3 网络爬虫基础
个人建议本章除3.3以外,其他内容可以大致先看一下,有些许印象即可,等到后面已经完成一些简单爬虫后或者在写爬虫过程中遇到一些问题再回头来巩固一下,这样子或许更有助于我们进一步网络理解爬虫。
3.1 HTTP协议
HTTP 协议是爬虫的基础,通过封装 TCP/IP 协议链接,简化了网络请求的流程,使得用户不需要关注三次握手,丢包超时等底层交互。
关于HTTP协议可以参考一下博文:
- HTTP 请求方法对照表
- HTTP 响应头和请求头信息对照表
- HTTP 状态码对照表
- HTTP Content-type 对照表
3.2 前端技术
作为新手,个人觉得入门的话懂一点HTML与JavaScript就可以实现基本的爬虫项目,HTML主要协助我们处理静态页面,而实际上很多数据并不是我们简单的右击查看网页源码便可以看到的,而是存在JSON(JavaScript Object Notation)文件中,这时我们便需要采取抓包分析,详见《5.2 爬取基于Ajax技术网页数据》。
- HTML 教程
- JavaScript 教程
3.3 正则表达式与XPath
做爬虫必不可少的步骤便是做解析。正则表达式是文本匹配提取的利器,并且被各种语言支持。XPath即为XML路径语言,类似Windows的文件路径,区别就在XPath是应用在网页页面中来定位我们所需内容的精确位置。具体用法参考以下资料:
- 正则表达式教程
- Python3如何优雅地使用正则表达式
- XPath教程
4 网络爬虫常见问题
4.1爬虫利器——python
Python 是一种十分便利的脚本语言,广泛被应用在各种爬虫框架。Python提供了如urllib、re、json、pyquery等模块,同时前人又利用Python造了许许多多的轮,如Scrapy框架、PySpider爬虫系统等,所以做爬虫Python是一大利器。
- 说明:本章开发环境细节如下
- 系统环境:windows 8.1
- 开发语言:Python3.5
- 开发工具:Spyder、Pycharm
- 辅助工具:Chrome浏览器
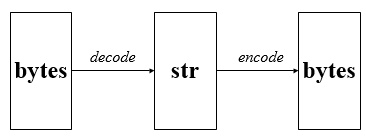
4.2 编码格式
Python3中,只有Unicode编码的为str,其他编码格式如gbk,utf-8,gb2312等都为bytes,在编解码过程中字节bytes通过解码方法decode()解码为字符串str,然后字符串str通过编码方法encode()编码为字节bytes,关系如下图:
实战——爬取当当网
爬取网页
In [5]:import urllib.request
...:data = urllib.request.urlopen("http://www.dangdang.com/").read()
#爬取的data中的<title>标签中的内容如下:
<title>\xb5\xb1\xb5\xb1\xa1\xaa\xcd\xf8\xc9\xcf\xb9\xba\xce\xef\xd6\xd0\xd0\xc4\xa3\xba\xcd\xbc\xca\xe9\xa1\xa2\xc4\xb8\xd3\xa4\xa1\xa2\xc3\xc0\xd7\xb1\xa1\xa2\xbc\xd2\xbe\xd3\xa1\xa2\xca\xfd\xc2\xeb\xa1\xa2\xbc\xd2\xb5\xe7\xa1\xa2\xb7\xfe\xd7\xb0\xa1\xa2\xd0\xac\xb0\xfc\xb5\xc8\xa3\xac\xd5\xfd\xc6\xb7\xb5\xcd\xbc\xdb\xa3\xac\xbb\xf5\xb5\xbd\xb8\xb6\xbf\xee</title>
查看编码格式
Python
In [5]:import chardet
...:chardet.detect(data)
Out[5]: {'confidence': 0.99, 'encoding': 'GB2312'}
可知爬取到的网页是GB2312编码,这是汉字的国标码,专门用来表示汉字。
解码
In [5]:decodeData = data.decode("gbk")
#此时bytes已经解码成str,<title>标签内容解码结果如下:
<title>当当—网上购物中心:图书、母婴、美妆、家居、数码、家电、服装、鞋包等,正品低价,货到付款</title>
重编码
Python
dataEncode = decodeData.encode("utf-8","ignore")
#重编码结果
<title>\xe5\xbd\x93\xe5\xbd\x93\xe2\x80\x94\xe7\xbd\x91\xe4\xb8\x8a\xe8\xb4\xad\xe7\x89\xa9\xe4\xb8\xad\xe5\xbf\x83\xef\xbc\x9a\xe5\x9b\xbe\xe4\xb9\xa6\xe3\x80\x81\xe6\xaf\x8d\xe5\xa9\xb4\xe3\x80\x81\xe7\xbe\x8e\xe5\xa6\x86\xe3\x80\x81\xe5\xae\xb6\xe5\xb1\x85\xe3\x80\x81\xe6\x95\xb0\xe7\xa0\x81\xe3\x80\x81\xe5\xae\xb6\xe7\x94\xb5\xe3\x80\x81\xe6\x9c\x8d\xe8\xa3\x85\xe3\x80\x81\xe9\x9e\x8b\xe5\x8c\x85\xe7\xad\x89\xef\xbc\x8c\xe6\xad\xa3\xe5\x93\x81\xe4\xbd\x8e\xe4\xbb\xb7\xef\xbc\x8c\xe8\xb4\xa7\xe5\x88\xb0\xe4\xbb\x98\xe6\xac\xbe</title>
4.3 超时设置
- 允许超时
Pythondata = urllib.request.urlopen(“http://www.dangdang.com/”,timeout=3).read()
- 线程推迟(单位为秒)
Pythonimport time time.sleep(3)
4.4 异常处理
每个程序都不可避免地要进行异常处理,爬虫也不例外,假如不进行异常处理,可能导致爬虫程序直接崩掉。
4.4.1 网络爬虫中处理异常的种类与关系
- URLError
通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。 - HTTPError首先我们要明白服务器上每一个HTTP 应答对象response都包含一个数字“状态码”,该状态码表示HTTP协议所返回的响应的状态,这就是HTTPError。比如当产生“404 Not Found”的时候,便表示“没有找到对应页面”,可能是输错了URL地址,也可能IP被该网站屏蔽了,这时便要使用代理IP进行爬取数据,关于代理IP的设定我们下面会讲到。
- 两者关系
两者是父类与子类的关系,即HTTPError是URLError的子类,HTTPError有异常状态码与异常原因,URLError没有异常状态码。所以,我们在处理的时候,不能使用URLError直接代替HTTPError。同时,Python中所有异常都是基类Exception的成员,所有异常都从此基类继承,而且都在exceptions模块中定义。如果要代替,必须要判断是否有状态码属性。
4.4.2 Python中有一套异常处理机制语法
- try-except语句
Pythontry: block except Exception as e: block else: block
- try 语句:捕获异常
- except语句:处理不同的异常,Exception是异常的种类,在爬虫中常见如上文所述。
- e:异常的信息,可供后面打印输出
- else: 表示若没有发生异常,当try执行完毕之后,就会执行else
- try-except-finally语句
Pythontry: block except Exception as e: block finally: block
假如try没有捕获到错误信息,则直接跳过except语句转而执行finally语句,其实无论是否捕获到异常都会执行finally语句,因此一般我们都会将一些释放资源的工作放到该步中,如关闭文件句柄或者关闭数据库连接等。
4.4.3 实战——爬取CSDN博客
Python
#(1)可捕获所有异常类型
import urllib.request
import urllib.error
import traceback
import sys
try:
urllib.request.urlopen("http://blog.csdn.net")
except Exception as er1:
print("异常概要:")
print(er1)
print("---------------------------")
errorInfo = sys.exc_info()
print("异常类型:"+str(errorInfo[0]))
print("异常信息或参数:"+str(errorInfo[1]))
print("调用栈信息的对象:"+str(errorInfo[2]))
print("已从堆栈中“辗转开解”的函数有关的信息:"+str(traceback.print_exc()))
#--------------------------------------------------
#(2)捕获URLError
import urllib.request
import urllib.error
try:
urllib.request.urlopen("http://blog.csdn.net")
except urllib.error.URLError as er2:
if hasattr(er2,"code"):
print("URLError异常代码:")
print(er2.code)
if hasattr(er2,"reason"):
print("URLError异常原因:")
print(er2.reason)
#--------------------------------------------------
#(3)捕获HTTPError
import urllib.request
import urllib.error
try:
urllib.request.urlopen("http://blog.csdn.net")
except urllib.error. HTTPError as er3:
print("HTTPError异常概要:")
print(er3)
Exception异常捕获输出结果如下:
Python
...:
异常概要:
HTTP Error 403: Forbidden
异常类型:<class 'urllib.error.HTTPError'>
异常信息或参数:HTTP Error 403: Forbidden
调用栈信息的对象:<traceback object at 0x00000089E1507E08>
已从堆栈中“辗转开解”的函数有关的信息:None
4.5 自动模拟HTTP请求
一般客户端需要通过HTTP请求才能与服务端进行通信,常见的HTTP请求有POST与GET两种。例如我们打开淘宝网页后一旦HTML加载完成,浏览器将会发送GET请求去获取图片等,这样子我们才能看到一个完整的动态页面,假如我们浏览后需要下单那么还需要向服务器传递登录信息。
- GET方式
向服务器发索取数据的一种请求,将请求数据融入到URL之中,数据在URL中可以看到。 - POST方式向服务器提交数据的一种请求,将数据放置在HTML HEADER内提交。从安全性讲,POST方式相对于GET方式较为安全,毕竟GET方式是直接将请求数据以明文的形式展现在URL中。
- 实战——登录CSDN/百度搜索简书
Pythonimport urllib.request import urllib.parse def postData(): '''1_POST方式登录CSDN''' values={} values['username'] = "xxx@qq.com" #账号 values['password']="xxx" #密码 info = urllib.parse.urlencode(values).encode("utf-8") url = "http://passport.csdn.net/account/login" try: req = urllib.request.Request(url,info) data = urllib.request.urlopen(req).read() except Exception as er: print("异常概要:") print(er) return data def getData(): '''2_GET方式搜索简书''' keyword = "简书" #搜索关键词 keyword = urllib.request.quote(keyword)#编码 url = "http://www.baidu.com/s?wd="+keyword try: req = urllib.request.Request(url) data = urllib.request.urlopen(req).read() except Exception as er: print("异常概要:") print(er) return data if __name__=="__main__": print(postData()) print(getData())
4.6 cookies处理
cookies是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
参考:零基础自学用Python 3开发网络爬虫(四): 登录
4.7 浏览器伪装
- 原理
浏览器伪装是防屏蔽的方法之一,简言之,其原理就是在客户端在向服务端发送的请求中添加报头信息,告诉服务器“我是浏览器” - 如何查看客户端信息?
通过Chrome浏览器按F12==》选择Network==》刷新后点击Name下任一个地址,便可以看到请求报文和相应报文信息。以下是在百度上搜索简书的请求报文信息,在爬虫中我们只需添加报头中的User-Agent便可实现浏览器伪装。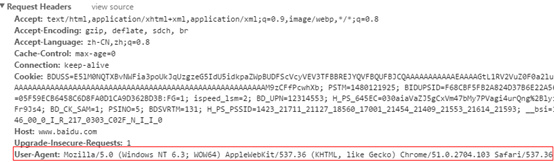
- 实战——爬取CSDN博客
在上面的实例中我们已知道对CSDN博客直接进行爬取的时候会返回403错误,接下来将我们伪装成浏览器爬取CSDN博客
Python'''浏览器伪装''' import urllib.request url = "http://blog.csdn.net/" headers=("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36") opener = urllib.request.build_opener() #自定义opener opener.addheaders = [headers] #添加客户端信息 #urllib.request.install_opener(opener) #如解除注释,则可以使用方法2 try: data = opener.open(url,timeout=10).read() #打开方法1 #data=urllib.request.urlopen(url).read() #打开方法2 except Exception as er: print("爬取的时候发生错误,具体如下:") print(er) f = open("F:/spider_ret/csdnTest.html","wb") #创建本地HTML文件 f.write(data) #将首页内容写入文件中 f.close()
4.8 代理服务器
- 原理
代理服务器原理如下图,利用代理服务器可以很好处理IP限制问题。 个人认为IP限制这一点对爬虫的影响是很大的,毕竟我们一般不会花钱去购买正规的代理IP,我们一般都是利用互联网上提供的一些免费代理IP进行爬取,而这些免费IP的质量残次不齐,出错是在所难免的,所以在使用之前我们要对其进行有效性测试。另外,对开源IP池有兴趣的同学可以学习Github上的开源项目:IPProxyPool。
个人认为IP限制这一点对爬虫的影响是很大的,毕竟我们一般不会花钱去购买正规的代理IP,我们一般都是利用互联网上提供的一些免费代理IP进行爬取,而这些免费IP的质量残次不齐,出错是在所难免的,所以在使用之前我们要对其进行有效性测试。另外,对开源IP池有兴趣的同学可以学习Github上的开源项目:IPProxyPool。
- 实战——代理服务器爬取百度首页
Pythonimport urllib.request def use_proxy(url,proxy_addr,iHeaders,timeoutSec): ''' 功能:伪装成浏览器并使用代理IP防屏蔽 @url:目标URL @proxy_addr:代理IP地址 @iHeaders:浏览器头信息 @timeoutSec:超时设置(单位:秒) ''' proxy = urllib.request.ProxyHandler({"http":proxy_addr}) opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler) urllib.request.install_opener(opener) try: req = urllib.request.Request(url,headers = iHeaders) #伪装为浏览器并封装request data = urllib.request.urlopen(req).read().decode("utf-8","ignore") except Exception as er: print("爬取时发生错误,具体如下:") print(er) return data url = "http://www.baidu.com" proxy_addr = "125.94.0.253:8080" iHeaders = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0"} timeoutSec = 10 data = use_proxy(url,proxy_addr,iHeaders,timeoutSec) print(len(data))
4.9 抓包分析
- Ajax(异步加载)的技术
网站中用户需求的数据如联系人列表,可以从独立于实际网页的服务端取得并且可以被动态地写入网页中。简单讲就是打开网页,先展现部分内容,再慢慢加载剩下的内容。显然,这样的网页因为不用一次加载全部内容其加载速度特别快,但对于我们爬虫的话就比较麻烦了,我们总爬不到我们想要的内容,这时候就需要进行抓包分析。 - 抓包工具
推荐Fiddler与Chrome浏览器 - 实战
请转《5.2 爬取基于Ajax技术网页数据》。
4.10多线程爬虫
一般我们程序是单线程运行,但多线程可以充分利用资源,优化爬虫效率。实际上Python 中的多线程并行化并不是真正的并行化,但是多线程在一定程度上还是能提高爬虫的执行效率,下面我们就针对单线程和多线程进行时间上的比较。
- 实战——爬取豆瓣科幻电影网页
Python'''多线程''' import urllib from multiprocessing.dummy import Pool import time def getResponse(url): '''获取响应信息''' try: req = urllib.request.Request(url) res = urllib.request.urlopen(req) except Exception as er: print("爬取时发生错误,具体如下:") print(er) return res def getURLs(): '''获取所需爬取的所有URL''' urls = [] for i in range(0, 101,20):#每翻一页其start值增加20 keyword = "科幻" keyword = urllib.request.quote(keyword) newpage = "https://movie.douban.com/tag/"+keyword+"?start="+str(i)+"&type=T" urls.append(newpage) return urls def singleTime(urls): '''单进程计时''' time1 = time.time() for i in urls: print(i) getResponse(i) time2 = time.time() return str(time2 - time1) def multiTime(urls): '''多进程计时''' pool = Pool(processes=4) #开启四个进程 time3 = time.time() pool.map(getResponse,urls) pool.close() pool.join() #等待进程池中的worker进程执行完毕 time4 = time.time() return str(time4 - time3) if __name__ == '__main__': urls = getURLs() singleTimes = singleTime(urls) #单线程计时 multiTimes = multiTime(urls) #多线程计时 print('单线程耗时 : ' + singleTimes + ' s') print('多线程耗时 : ' + multiTimes + ' s') - 结果:
Python单线程耗时 : 3.850554943084717 s 多线程耗时 : 1.3288819789886475 s
- 更多详情请参考:
Python 并行任务技巧
Python中的多进程处理
4.11 数据存储
- 本地文件(excel、txt)
- 数据库(如MySQL)
备注:具体实战请看5.1
4.12 验证码处理
在登录过程中我们常遇到验证码问题,此时我们有必要对其进行处理。
- 简单验证码识别
利用pytesser识别简单图形验证码,有兴趣的童鞋,请参考Python验证码识别。 - 复杂验证码识别
这相对有难度,可以调用第三方接口(如打码兔)、利用数据挖掘算法如SVM,有兴趣参考字符型图片验证码识别完整过程及Python实现
5 综合实战案例
5.1 爬取静态网页数据
(1)需求
爬取豆瓣网出版社名字并分别存储到excel、txt与MySQL数据库中。
(2)分析
- 查看源码
- Ctrl+F搜索任意出版社名字,如博集天卷
- 确定正则模式
Python"<div class="name">(.*?)</div>"
(3)思路
- 下载目标页面
- 正则匹配目标内容
- Python列表存储
- 写入Excel/txt/MySQL
(4)源码
Python
'''信息存储'''
import urllib
import re
import xlsxwriter
import MySQLdb
#-----------------(1)存储到excel与txt-------------------------#
def gxls_concent(target_url,pat):
'''
功能:爬取数据
@target_url:爬取目标网址
@pat:数据过滤模式
'''
data = urllib.request.urlopen(target_url).read()
ret_concent = re.compile(pat).findall(str(data,'utf-8'))
return ret_concent
def wxls_concent(ret_xls,ret_concent):
'''
功能:将最终结果写入douban.xls中
@ret_xls:最终结果存储excel表的路径
@ret_concent:爬取数据结果列表
'''
# 打开最终写入的文件
wb1 = xlsxwriter.Workbook(ret_xls)
# 创建一个sheet工作对象
ws = wb1.add_worksheet()
try:
for i in range(len(ret_concent)):
data = ret_concent[i]
ws.write(i,0,data)
wb1.close()
except Exception as er:
print('写入“'+ret_xls+'”文件时出现错误')
print(er)
def wtxt_concent(ret_txt,ret_concent):
'''
功能:将最终结果写入douban.txt中
@ret_xls:最终结果存储excel表的路径
@ret_concent:爬取数据结果列表
'''
fh = open(ret_txt,"wb")
try:
for i in range(len(ret_concent)):
data = ret_concent[i]
data = data+"\r\n"
data = data.encode()
fh.write(data)
except Exception as er:
print('写入“'+ret_txt+'”文件时出现错误')
print(er)
fh.close()
def mainXlsTxt():
'''
功能:将数据存储到excel表中
'''
target_url = 'https://read.douban.com/provider/all' # 爬取目标网址
pat = '<div class="name">(.*?)</div>' # 爬取模式
ret_xls = "F:/spider_ret/douban.xls" # excel文件路径
ret_txt = "F:/spider_ret/douban.txt" # txt文件路径
ret_concent = gxls_concent(target_url,pat) # 获取数据
wxls_concent(ret_xls,ret_concent) # 写入excel表
wtxt_concent(ret_txt,ret_concent) # 写入txt文件
#---------------------END(1)--------------------------------#
#-------------------(2)存储到MySQL---------------------------#
def db_con():
'''
功能:连接MySQL数据库
'''
con = MySQLdb.connect(
host='localhost', # port
user='root', # usr_name
passwd='xxxx', # passname
db='urllib_data', # db_name
charset='utf8',
local_infile = 1
)
return con
def exeSQL(sql):
'''
功能:数据库查询函数
@sql:定义SQL语句
'''
print("exeSQL: " + sql)
#连接数据库
con = db_con()
con.query(sql)
def gdb_concent(target_url,pat):
'''
功能:转换爬取数据为插入数据库格式:[[value_1],[value_2],...,[value_n]]
@target_url:爬取目标网址
@pat:数据过滤模式
'''
tmp_concent = gxls_concent(target_url,pat)
ret_concent = []
for i in range(len(tmp_concent)):
ret_concent.append([tmp_concent[i]])
return ret_concent
def wdb_concent(tbl_name,ret_concent):
'''
功能:将爬取结果写入MySQL数据库中
@tbl_name:数据表名
@ret_concent:爬取数据结果列表
'''
exeSQL("drop table if exists " + tbl_name)
exeSQL("create table " + tbl_name + "(pro_name VARCHAR(100));")
insert_sql = "insert into " + tbl_name + " values(%s);"
con = db_con()
cursor = con.cursor()
try:
cursor.executemany(insert_sql,ret_concent)
except Exception as er:
print('执行MySQL:"' + str(insert_sql) + '"时出错')
print(er)
finally:
cursor.close()
con.commit()
con.close()
def mainDb():
'''
功能:将数据存储到MySQL数据库中
'''
target_url = 'https://read.douban.com/provider/all' # 爬取目标网址
pat = '<div class="name">(.*?)</div>' # 爬取模式
tbl_name = "provider" # 数据表名
# 获取数据
ret_concent = gdb_concent(target_url,pat)
# 写入MySQL数据库
wdb_concent(tbl_name,ret_concent)
#---------------------END(2)--------------------------------#
if __name__ == '__main__':
mainXlsTxt()
mainDb()
(5)结果
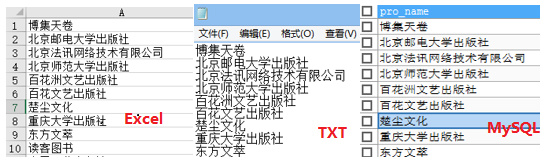
5.2 爬取基于Ajax技术网页数据
(1)需求
爬取拉勾网广州的数据挖掘岗位信息并存储到本地Excel文件中
(2)分析
- 岗位数据在哪里?
打开拉勾网==》输入关键词“数据挖掘”==》查看源码==》没发现岗位信息
打开拉勾网==》输入关键词“数据挖掘”==》按F12==》Network刷新==》按下图操作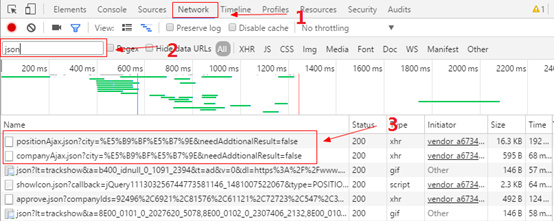
我们可以发现存在position和company开头的json文件,这很可能就是我们所需要的岗位信息,右击选择open link in new tab,可以发现其就是我们所需的内容。

- 如何实现翻页?
我们在写爬虫的时候需要多页爬取,自动模拟换页操作。首先我们点击下一页,可以看到url没有改变,这也就是Ajax(异步加载)的技术。点击position的json文件,在右侧点击Headers栏,可以发现最底部有如下内容: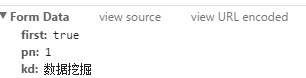
当我们换页的时候pn则变为2且first变为false,故我们可以通过构造post表单进行爬取。
- Json数据结构怎么样?
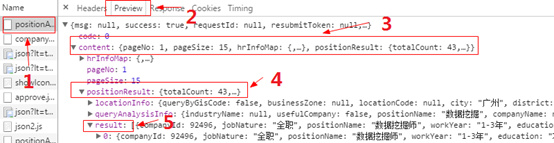
(3)源码
Pythonimport urllib.request import urllib.parse import socket from multiprocessing.dummy import Pool import json import time import xlsxwriter #----------------------------------------------------------# ### ###(1)获取代理IP ### def getProxies(): ''' 功能:调用API获取原始代理IP池 ''' url = "http://api.xicidaili.com/free2016.txt" i_headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0"} global proxy_addr proxy_addr = [] try: req = urllib.request.Request(url,headers = i_headers) proxy = urllib.request.urlopen(req).read() proxy = proxy.decode('utf-8') proxy_addr = proxy.split('\r\n') #设置分隔符为换行符 except Exception as er: print(er) return proxy_addr def testProxy(curr_ip): ''' 功能:利用百度首页,逐个验证代理IP的有效性 @curr_ip:当前被验证的IP ''' socket.setdefaulttimeout(5) #设置全局超时时间 tarURL = "https://www.baidu.com/" #测试网址 proxy_ip = [] try: proxy_support = urllib.request.ProxyHandler({"http":curr_ip}) opener = urllib.request.build_opener(proxy_support) opener.addheaders=[("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0")] urllib.request.install_opener(opener) res = urllib.request.urlopen(tarURL).read() proxy_ip.append(curr_ip) print(len(res)) except Exception as er: print("验证代理IP("+curr_ip+")时发生错误:"+er) return proxy_ip def mulTestProxies(proxies_ip): ''' 功能:构建多进程验证所有代理IP @proxies_ip:代理IP池 ''' pool = Pool(processes=4) #开启四个进程 proxies_addr = pool.map(testProxy,proxies_ip) pool.close() pool.join() #等待进程池中的worker进程执行完毕 return proxies_addr #----------------------------------------------------------# ### ###(2)爬取数据 ### def getInfoDict(url,page,pos_words_one,proxy_addr_one): ''' 功能:获取单页职位数据,返回数据字典 @url:目标URL @page:爬取第几页 @pos_words_one:搜索关键词(单个) @proxy_addr_one:使用的代理IP(单个) ''' global pos_dict page = 1 i_headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0") proxy = urllib.request.ProxyHandler({"http":proxy_addr_one}) opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler) opener.addheaders=[i_headers] urllib.request.install_opener(opener) if page==1: tORf = "true" else: tORf = "false" mydata = urllib.parse.urlencode({"first": tORf, "pn": page, #pn变化实现翻页 "kd": pos_words_one } ).encode("utf-8") try: req = urllib.request.Request(url,mydata) data=urllib.request.urlopen(req).read().decode("utf-8","ignore") #利用代理ip打开 pos_dict = json.loads(data) #将str转成dict except urllib.error.URLError as er: if hasattr(er,"code"): print("获取职位信息json对象时发生URLError错误,错误代码:") print(er.code) if hasattr(er,"reason"): print("获取职位信息json对象时发生URLError错误,错误原因:") print(er.reason) return pos_dict def getInfoList(pos_dict): ''' 功能:将getInfoDict()返回的数据字典转换为数据列表 @pos_dict:职位信息数据字典 ''' pos_list = [] #职位信息列表 jcontent = pos_dict["content"]["positionResult"]["result"] for i in jcontent: one_info = [] #一个职位的相关信息 one_info.append(i["companyFullName"]) one_info.append(i['companySize']) one_info.append(i['positionName']) one_info.append(i['education']) one_info.append(i['financeStage']) one_info.append(i['salary']) one_info.append(i['city']) one_info.append(i['district']) one_info.append(i['positionAdvantage']) one_info.append(i['workYear']) pos_list.append(one_info) return pos_list def getPosInfo(pos_words,city_words,proxy_addr): ''' 功能:基于函数getInfoDict()与getInfoList(),循环遍历每一页获取最终所有职位信息列表 @pos_words:职位关键词(多个) @city_words:限制城市关键词(多个) @proxy_addr:使用的代理IP池(多个) ''' posInfo_result = [] title = ['公司全名', '公司规模', '职位名称', '教育程度', '融资情况', "薪资水平", "城市", "区域", "优势", "工作经验"] posInfo_result.append(title) for i in range(0,len(city_words)): #i = 0 key_city = urllib.request.quote(city_words[i]) #筛选关键词设置:gj=应届毕业生&xl=大专&jd=成长型&hy=移动互联网&px=new&city=广州 url = "https://www.lagou.com/jobs/positionAjax.json?city="+key_city+"&needAddtionalResult=false" for j in range(0,len(pos_words)): #j = 0 page=1 while page<10: #每个关键词搜索拉钩显示30页,在此只爬取10页 pos_words_one = pos_words[j] #k = 1 proxy_addr_one = proxy_addr[page] #page += 1 time.sleep(3) pos_info = getInfoDict(url,page,pos_words_one,proxy_addr_one) #获取单页信息列表 pos_infoList = getInfoList(pos_info) posInfo_result += pos_infoList #累加所有页面信息 page += 1 return posInfo_result #----------------------------------------------------------# ### ###(3)存储数据 ### def wXlsConcent(export_path,posInfo_result): ''' 功能:将最终结果写入本地excel文件中 @export_path:导出路径 @posInfo_result:爬取的数据列表 ''' # 打开最终写入的文件 wb1 = xlsxwriter.Workbook(export_path) # 创建一个sheet工作对象 ws = wb1.add_worksheet() try: for i in range(0,len(posInfo_result)): for j in range(0,len(posInfo_result[i])): data = posInfo_result[i][j] ws.write(i,j,data) wb1.close() except Exception as er: print('写入“'+export_path+'”文件时出现错误:') print(er) #----------------------------------------------------------# ### ###(4)定义main()函数 ### def main(): ''' 功能:主函数,调用相关函数,最终输出路径(F:/spider_ret)下的positionInfo.xls文件 ''' #---(1)获取代理IP池 proxies = getProxies() #获取原始代理IP proxy_addr = mulTestProxies(proxies) #多线程测试原始代理IP #---(2)爬取数据 search_key = ["数据挖掘"] #设置职位关键词(可以设置多个) city_word = ["广州"] #设置搜索地区(可以设置多个) posInfo_result = getPosInfo(search_key,city_word,proxy_addr) #爬取职位信息 #---(3)存储数据 export_path = "F:/spider_ret/positionInfo.xls" #设置导出路径 wXlsConcent(export_path,posInfo_result) #写入到excel中 if __name__ == "__main__": main()
5.3 利用Scrapy框架爬取
5.3.1 了解Scrapy
Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下(注:图片来自互联网):
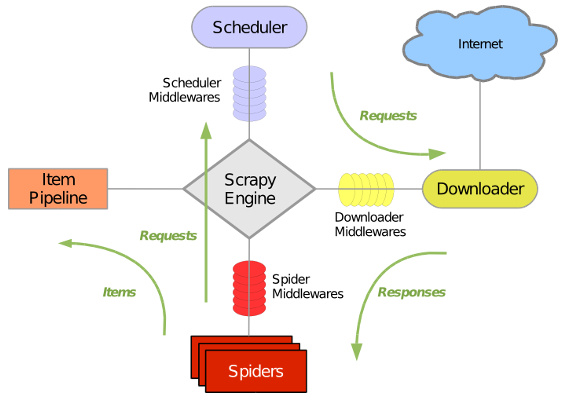
详情转Scrapy:Python的爬虫框架
关于Scrapy的使用方法请参考官方文档
5.3.2 Scrapy自动爬虫
前面的实战中我们都是通过循环构建URL进行数据爬取,其实还有另外一种实现方式,首先设定初始URL,获取当前URL中的新链接,基于这些链接继续爬取,直到所爬取的页面不存在新的链接为止。
(1)需求
采用自动爬虫的方式爬取糗事百科文章链接与内容,并将文章头部内容与链接存储到MySQL数据库中。
(2)分析
- 怎么提取首页文章链接?
打开首页后查看源码,搜索首页任一篇文章内容,可以看到”/article/118123230″链接,点击进去后发现这就是我们所要的文章内容,所以我们在自动爬虫中需设置链接包含”article”
- 怎么提取详情页文章内容与链接
- 内容
打开详情页后,查看文章内容如下:
分析可知利用包含属性class且其值为content的div标签可唯一确定文章内容,表达式如下:
"//div[@class='content']/text()" - 链接打开任一详情页,复制详情页链接,查看详情页源码,搜索链接如下:

采用以下XPath表达式可提取文章链接。
["//link[@rel='canonical']/@href"]
- 内容
(3)项目源码
创建爬虫项目
打开CMD,切换到存储爬虫项目的目录下,输入:
scrapy startproject qsbkauto

- 项目结构说明
- spiders.qsbkspd.py:爬虫文件
- items.py:项目实体,要提取的内容的容器,如当当网商品的标题、评论数等
- pipelines.py:项目管道,主要用于数据的后续处理,如将数据写入Excel和db等
- settings.py:项目设置,如默认是不开启pipeline、遵守robots协议等
- scrapy.cfg:项目配置
创建爬虫
进入创建的爬虫项目,输入:
scrapy genspider -t crawl qsbkspd qiushibaie=ke.com(域名)
定义items
Python
import scrapy
class QsbkautoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Link = scrapy.Field() #文章链接
Connent = scrapy.Field() #文章内容
pass
编写爬虫
- qsbkauto.py
Python# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from qsbkauto.items import QsbkautoItem from scrapy.http import Request class QsbkspdSpider(CrawlSpider): name = 'qsbkspd' allowed_domains = ['qiushibaike.com'] #start_urls = ['http://qiushibaike.com/'] def start_requests(self): i_headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0"} yield Request('http://www.qiushibaike.com/',headers=i_headers) rules = ( Rule(LinkExtractor(allow=r'article/'), callback='parse_item', follow=True), ) def parse_item(self, response): #i = {} #i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract() #i['name'] = response.xpath('//div[@id="name"]').extract() #i['description'] = response.xpath('//div[@id="description"]').extract() i = QsbkautoItem() i["content"]=response.xpath("//div[@class='content']/text()").extract() i["link"]=response.xpath("//link[@rel='canonical']/@href").extract() return i - pipelines.py
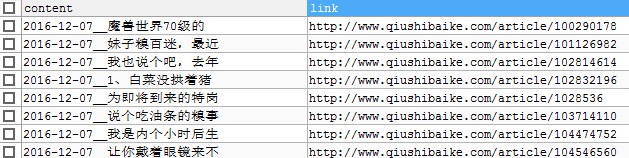
Pythonimport MySQLdb import time class QsbkautoPipeline(object): def exeSQL(self,sql): ''' 功能:连接MySQL数据库并执行sql语句 @sql:定义SQL语句 ''' con = MySQLdb.connect( host='localhost', # port user='root', # usr_name passwd='xxxx', # passname db='spdRet', # db_name charset='utf8', local_infile = 1 ) con.query(sql) con.commit() con.close() def process_item(self, item, spider): link_url = item['link'][0] content_header = item['content'][0][0:10] curr_date = time.strftime('%Y-%m-%d',time.localtime(time.time())) content_header = curr_date+'__'+content_header if (len(link_url) and len(content_header)):#判断是否为空值 try: sql="insert into qiushi(content,link) values('"+content_header+"','"+link_url+"')" self.exeSQL(sql) except Exception as er: print("插入错误,错误如下:") print(er) else: pass return item - setting.py关闭ROBOTSTXT_OBEY
设置USER_AGENT
开启ITEM_PIPELINES
执行爬虫
Pythonscrapy crawl qsbkauto --nolog
结果
参考:
[1] 天善社区韦玮老师课程
[2] 文中所跳转的URL
本文所有代码只用于技术交流,拒绝任何商用活动
文章相关项目代码已上传至个人Github
后续的学习细节将会记录在个人博客whenif中,欢迎各路同学互相交流
相关内容
- 从零开始的Python爬虫速成指南,python爬虫速成, 受众:
- Python爬虫基础,python爬虫,(当然ruby也是很好的
- 使用Python抓取欧洲足球联赛数据,python欧洲足球联赛
- Python 异步网络爬虫(1),python爬虫,未经作者许可,禁
- Python 异步网络爬虫(2),python爬虫,未经作者许可,禁
- Python初学者之网络爬虫,python初学者爬虫,未经作者许可
- 从数据角度解析福州美食,数据解析福州美食,未经作者
- 爬虫破解IP限制:ADSL动态IP服务器部署,爬虫adsl,未经作
- 爬虫学习之一个简单的网络爬虫,学习网络爬虫,有了数
- Python爬虫:一些常用的爬虫技巧总结,python爬虫技巧总
评论关闭