你好,TensorFlow,你好tensorflow,未经许可,禁止转载!英文
你好,TensorFlow,你好tensorflow,未经许可,禁止转载!英文
本文由 编橙之家 - Ree Ray 翻译,艾凌风 校稿。未经许可,禁止转载!英文出处:Aaron Schumacher。欢迎加入翻译组。
零基础创建和训练你的第一个 TensorFlow 图(Graph)
TensorFlow 之大远远超出你的认识。事实上它是一个针对深度学习的库,并藉由和谷歌的关系赢得了许多关注。但除去这些噱头,项目的如下特性(unique elements)值得深入玩味。
- 核心库“不仅”适用深度学习,且面向绝大部分的机器学习技术。
- 线性代数和其它内部构件(internals)(的功能)尤其突出(prominently exposed)。
- 除了主要的机器学习功能以外,TensorFlow 还有自己的日志(logging)系统、可交互的日志可视化工具(interactive log visualizer),甚至有工程性非常强的(heavily engineered)服务架构(serving architecture)。
- TensorFlow 的执行(execution)模型有别于 Python 的 scikit-learn,或是 R 语言中大部分的工具。
TensorFlow 里这些酷炫的玩意(Cool stuff)非常容易被那些渴望探索机器学习的初学者接受(take in)。
TensorFlow 的原理是什么?让我们深入剖析来查看和理解它的每个独立部分。我们会探索即将进行计算的数据的数据流图(data flow graph),怎么通过 TensorFlow 使用梯度下降(gradient descent)来训练模型,以及怎样利用 TensorBoard 来可视化 TensorFlow 的工作。虽然这些例子解决不了工业级的机器学习问题,但是能够帮助你理解构建 TensorFlow 的每个组件(components ),包括下面的程序会使用到的!
Python 与 TensorFlow 中的命名(names)与执行
TensorFlow 的计算管理和 Python 完全不同。按照 Hadley Wickham 的说法,对于这两者都该牢记的是:一个对象(obejct)不会对应(have)一个命名(见图 1)。为了观察 Python 和 TensorFlow 的相似性(以及差异),让我们看看他们是如何引用(refer to)对象和处理执行的。
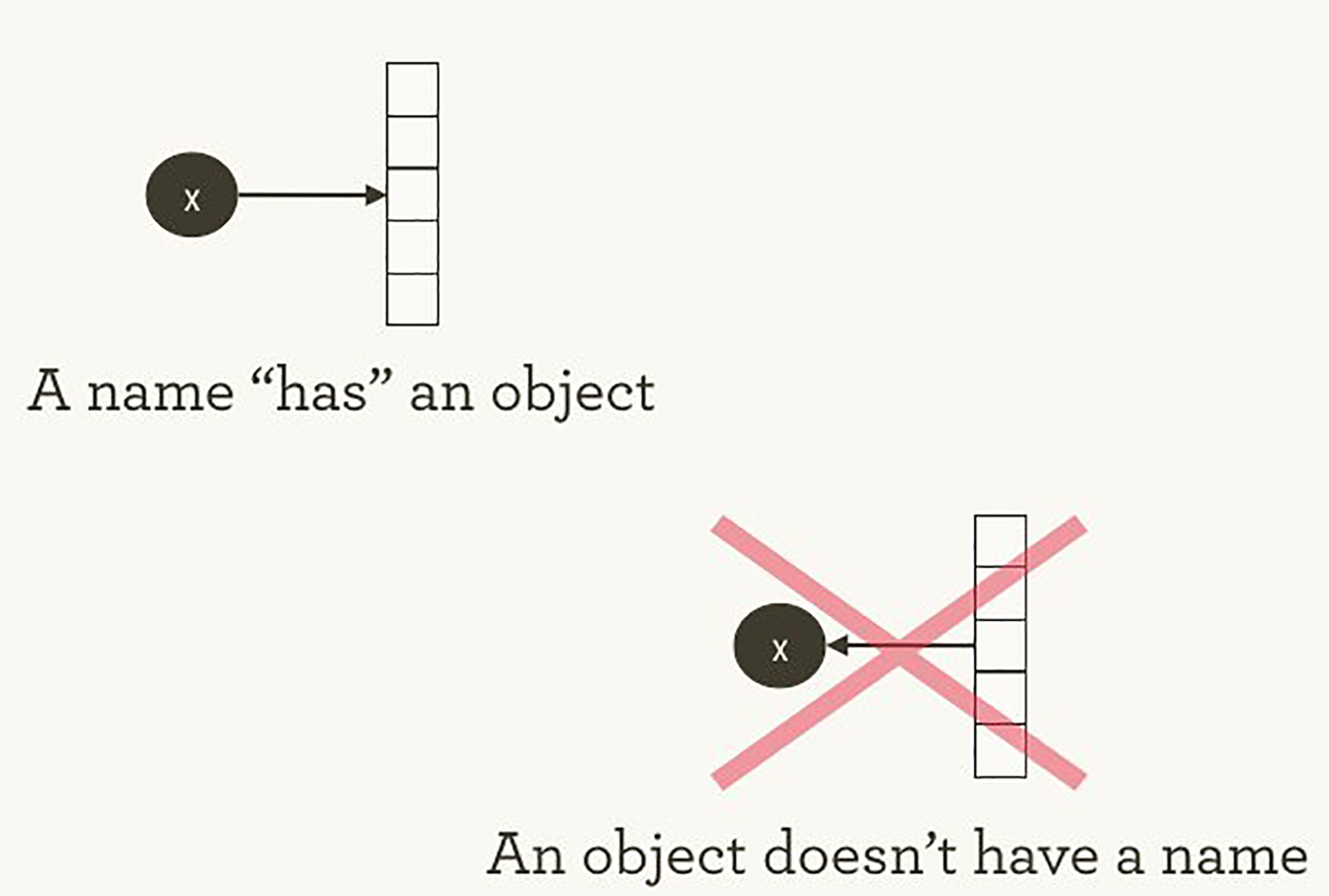
图 1 命名“对应”对象,反之却不然。图片由 Hadley Wickham 提供,已获授权。
Python 代码中的变量名并不是它们代表的那样;它们只是指向对象。因此,当你写出以下的代码:foo = [] 和 bar = foo,不仅说明 foo 和 bar 的值相等,并且强调了 foo 就是 bar。也就是说它们指向了相同的列表对象。
>>> foo = [] >>> bar = foo >>> foo == bar ## True >>> foo is bar ## True
你也会发现 id(foo) 和 id(bar) 是一样的。这种一致性(identity),一旦被错误使用(misunderstood),会产生一些意外的 bug,尤其对于列表这样的可变数据结构(mutable data structures)。
就内部而言,Python 管理所有的对象并且会保留所有变量名和引用对象的过程(track)。TensorFlow 图则代表了这种管理方式的另一个层次(layer);如同我们所见,Python 的命名会引用对象,使得有更多(granular)连接和管理 TensorFlow 的图的 ops(operations)。
当你在 Python 解释器(expression),诸如交互式编译器或者“读取-求值-输出循环(Read Evaluate Print Loop,缩写为 REPL)”,可以即时读取和输出。Python 会执行你的命令。所以如果当我输入 foo.append(bar),Python 会立刻添加,即使我再也不用到 foo。
更懒的替代方法是我输入 foo.append(bar),如果我在以后再执行 foo,Python 会接着添加。这就非常接近 TensorFlow 的做法了,即定义关系完全和计算结果分离开来。
TensorFlow 分离了计算的定义和执行,甚至分开来进行这些操作:一个图定义了一个 ops,但只会在会话(session)中进行。图和会话都是独立创建的。图类似于施工图(blueprint),而会话更像施工地点。
回到纯 Python 的例子,回忆一下 foo 和 bar 会引用相同的列表。把 bar 添加进 foo,就如同把列表塞进它本身。你可以把这个结构看作是一个有节点(node)的图指向它本身。嵌套列表(Nesting lists)是代表图结构的一种方式,像 TensorFlow 的计算图。
>>> foo.append(bar) >>> foo ## [[...]]
真正的 TensorFlow 图比这更有意思!
最简单的 TensorFlow 图
让我们开始手把手从头创建最简单的 TensorFlow 图。和别的框架比,TensorFlow 非常容易安装。本文使用的例子可以在 Python 2.7 或者 3.3+ 中运行,TensorFlow 的版本则是 0.8。
>>> import tensorflow as tf
到这一步 TensorFlow 已经为我们处理了许多声明(state)。已经存在一个隐藏的默认图,举个例子,就内部而言,它在 _default_graph_stack,但我们不能直接调用(access)它,需要通过 tf.get_default_graph() 函数。
>>> graph = tf.get_default_graph()
TensorFlow 图的节点被成为“operations”或者简称为“ops”。在图的 graph.get_operations() 函数中可以了解 ops 是什么。
>>> graph.get_operations() ## []
现在图还是空的。我们需要把让 TensorFlow 计算的数据塞进去。因此先输入一个简单的常量(constant) 1。
>>> input_value = tf.constant(1.0)
这个常量目前以一个节点的形式存在,也就是图里的一个 op(operation)。Python 的变量名 input_value 间接引用这个 op,但我们还是能在默认图中找到这个 op。
>>> operations = graph.get_operations()
>>> operations
## [<tensorflow.python.framework.ops.Operation at 0x1185005d0>]
>>> operations[0].node_def
## name: "Const"
## op: "Const"
## attr {
## key: "dtype"
## value {
## type: DT_FLOAT
## }
## }
## attr {
## key: "value"
## value {
## tensor {
## dtype: DT_FLOAT
## tensor_shape {
## }
## float_val: 1.0
## }
## }
## }
TensorFlow 内部使用了协议缓冲(Protocol buffers,类似于谷歌式(Google-strength)的 JSON)。打印上述常量 op 的 node_def 可以观察 TensorFlow 怎么用协议缓冲来表示常量 1。
刚开始接触 TensorFlow 的人有时候会想知道为什么对于“TensorFlow 的版本”问题会大惊小怪(fuss)。为什么不能使用原有的 Python 变量,而不去定义 TensorFlow 对象?TensorFlow 其中一个教程解释如下(译者注:为了避免重复劳动,以下引用翻译来自 TensorFlow 中文社区,特此致谢):
在Python中进行高效的数值计算,我们通常会使用像NumPy一类的库,将一些诸如矩阵乘法的耗时操作在Python环境的外部来计算,这些计算通常会通过其它语言并用更为高效的代码来实现。但遗憾的是,每一个操作切换回Python环境时仍需要不小的开销。如果你想在GPU或者分布式环境中计算时,这一开销更加可怖,这一开销主要可能是用来进行数据迁移。
TensorFlow也是在Python外部完成其主要工作,但是进行了改进以避免这种开销。其并没有采用在Python外部独立运行某个耗时操作的方式,而是先让我们描述一个交互操作图,然后完全将其运行在Python外部。这与Theano或Torch的做法类似。
TensorFlow 能干许多了不起的事情,但需要很明确给出要求,即便只是单个常量。
如果我们查看 input_value,会发现是一个维度为空的 32 位的浮点型张量(tensor):意味着只有一个数字。
>>> input_value ## <tf.Tensor 'Const:0' shape=() dtype=float32>
值得注意的是,这个操作不会告诉我们这个数字是什么。执行 input_value 并得到这个数字的值,我们需要创建一个会话使图的 ops 能够被执行而且明确要求“运行” input_value(会话默认会处理(picks up)默认图)。
>>> sess = tf.Session() >>> sess.run(input_value) ## 1.0
对于“运行”一个常量可能会感到有些奇怪。但这和在 Python 中执行常见的表达一样;仅仅只是因为 TensorFlow 管理自身空间——计算图——以及有自己独特的方法执行。
最简单的 TensorFlow 神经元(neuron)
现在带有简单图的会话已经创建好了,让我们继续创建一个只有单个参数的神经元,或者说是权重(weight)。通常,即便再简单的神经元也会存在偏项(bias term)和非同一性激励函数(non-identity activation function),但我们省去这步。
神经元的权重不会是一个常量;我们希望它能够改变,因为需要从“真实”的输入和输出来进行训练。这个权重将会是 TensorFlow 的变量。我们把这个变量的初始值设为 0.8。
>>> weight = tf.Variable(0.8)
你也许以为添加 1 个变量也会在图中添加 1 个 op,但事实上是 4 个。我们来看看所有 ops 的命名:
>>> for op in graph.get_operations(): print(op.name) ## Const ## Variable/initial_value ## Variable ## Variable/Assign ## Variable/read
我们并不想单独观察每个 op 太久,但至少观察一个来看看真实的运算。
>>> output_value = weight * input_value
现在图中有 6 个 ops,最后一个是乘法。
>>> op = graph.get_operations()[-1]
>>> op.name
## 'mul'
>>> for op_input in op.inputs: print(op_input)
## Tensor("Variable/read:0", shape=(), dtype=float32)
## Tensor("Const:0", shape=(), dtype=float32)
这说明了乘法 op 的输入来源:来自图中的其它 ops。要了解整个图,按这种方法很快会使人恹恹欲睡。所以 TensorBoard graph visualization 就应运而生了。
怎样查看生成了些什么呢?我们必须“运行” output_value op。但它取决于变量:weight。我们将初始的 weight 设为 0.8,但这个值在当前会话中还没有设置。tf.initialize_all_variables() 函数会生成一个可以初始化所有变量(虽然本例中只有一个变量)的 op,下面运行这个 op。
>>> init = tf.initialize_all_variables() >>> sess.run(init)
运行 tf.initialize_all_variables() 后会对目前存在于图中的所有变量进行初始化,所以如果添加更多变量后,会想再次使用 tf.initialize_all_variables();但原有的 init 不包括新的变量。
下面我们准备运行 output_value 的 op。
>>> sess.run(output_value) ## 0.80000001
回想一下 0.8 * 1.0 进行 32 位的浮点型运算很难得到 0.8;0.80000001 是最接近的数。
在 TensorBoard 观察你的图
到目前为止,简单的图已经完成了,但通过图解(diagram)能观察会更棒。用 TensorBoard 就能生成这个图解。TensorBoard 读取命名字段(name field)并将每个 op 存储在内部(和 Python 的变量名比起来很不同)。我们可以使用这些 TensorFlow 命名并转换成更符合 Python 习惯的变量名。在这使用的 tf.mul 和前面用 * 一样都是乘法,但它可以设置 op 的命名。
>>> x = tf.constant(1.0, name='input') >>> w = tf.Variable(0.8, name='weight') >>> y = tf.mul(w, x, name='output')
TensorBoard 由 TensorFlow 会话创建的输出目录进行观察。我们可以用 SummaryWriter 写入这个输出,如果创建图的时候我们不做任何操作,它只会写入这个图。
当我们创建 SummaryWriter 时,第一个参数是输出目录的名称,如果不存在会自动创建。
>>> summary_writer = tf.train.SummaryWriter('log_simple_graph', sess.graph)
我们现在可以在命令行启动 TensorBoard了。
Python$ tensorboard --logdir=log_simple_graph
TensorBoard 会运行一个本地的 web 应用,在 6006 端口(“6006”是“goog”的翻转)。如果你浏览 localhost:6006/#graphs,你可以看到你在 TensorFlow 图的图解,就像图 2 所示。
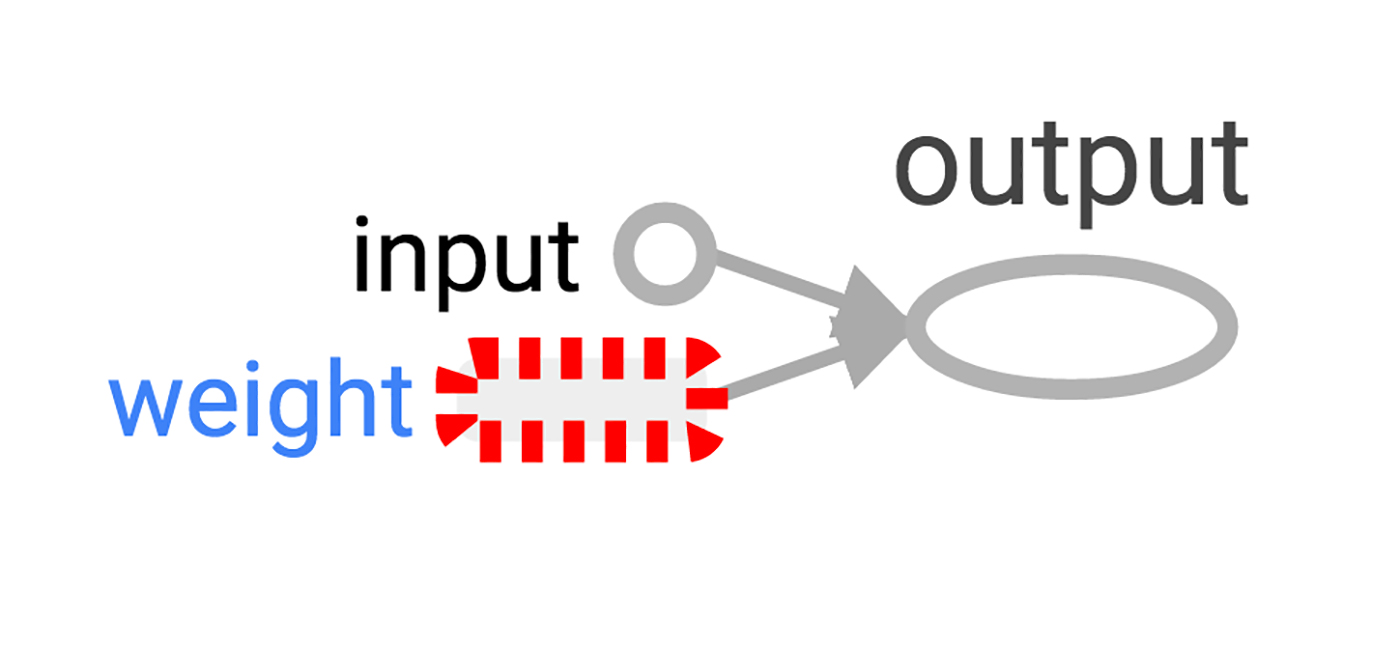
图2:最小 TensorFlow 神经元的 TensorBoard 可视化
让神经元学习
我们已经创建了神经元,但怎么让它学习呢?我们将输入值设置为 1.0,正确的输出值设置为 0。现在我们有一个非常简单的“训练集”,只有一个值为 1 的特征(feature)和值为 0 的标签(label)。我们希望这个神经元能够学会从 1 变为 0。
现在向程序输入 1,返回 0.8 的结果是不正确的。我们需要一种方式来描述系统误差。所以我们用“损失(loss)”来描述系统误差,我们的目标就是尽可能减少系统误差。当然,如果误差为负,就不是越小越好了。因此我们用实际输出(current output)和期望输出(desired output)的平方差来定义误差的值。
>>> y_ = tf.constant(0.0) >>> loss = (y - y_)**2
目前,图里还没有东西进行学习。因此我们需要一个优化器(optimizer)。我们将使用梯度下降优化器使我们能够按照误差的导数(derivative)来更新权重。这个优化器通过学习率(learning rate)来调节(moderate)更新的大小,我们设置为 0.025。
>>> optim = tf.train.GradientDescentOptimizer(learning_rate=0.025)
这个优化器聪明极了。通过整个网络,它可以自动计算和使用合适的梯度,完成后面的步骤来进行学习。
让我们来看看本例中的梯度长什么样:
>>> grads_and_vars = optim.compute_gradients(loss) >>> sess.run(tf.initialize_all_variables()) >>> sess.run(grads_and_vars[1][0]) ## 1.6
为什么梯度的值是 1.6?我们的误差是错误值(error)的平方,而导数则是错误值的两倍。现在程序的输出是 0.8,还不是 0,所以错误值就是 0.8,0.8 的两倍正好是 1.6。成功了!
对于更复杂的系统,TensorFlow 自动计算和应用这些梯度会更方便。
让我们使用梯度,完成反向传播(backpropagation)。
>>> sess.run(optim.apply_gradients(grads_and_vars)) >>> sess.run(w) ## 0.75999999 # about 0.76
>>> sess.run(optim.apply_gradients(grads_and_vars)) >>> sess.run(w) ## 0.75999999 # 约为 0.76
因为权重等于优化器减去梯度乘以学习率,即减去 1.6 * 0.025,因此减少 0.04 是正确的。
为了取代上面的手动(hand-holding)优化器,我们可以用:train_step op 来计算和应用梯度。
>>> train_step = tf.train.GradientDescentOptimizer(0.025).minimize(loss) >>> for i in range(100): >>> sess.run(train_step) >>> >>> sess.run(y) ## 0.0044996012
多次迭代训练步骤后,权重和输出的值已经非常接近 0。神经元已经具有学习能力了!
用 TensorBoard 展示训练过程
我们也许对训练的时候发生了什么感兴趣。也就是我们想知道程序在训练过程中做了些什么。因此可以输出每个迭代的循环。
>>> sess.run(tf.initialize_all_variables())
>>> for i in range(100):
>>> print('before step {}, y is {}'.format(i, sess.run(y)))
>>> sess.run(train_step)
>>>
## before step 0, y is 0.800000011921
## before step 1, y is 0.759999990463
## ...
## before step 98, y is 0.00524811353534
## before step 99, y is 0.00498570781201
虽然奏效了,但是有点小瑕疵。就是这一串的数字理解起来很困难。如果能画出来会更好。即使只有一个值需要观察,输出也会非常多导致看不过来。我们更倾向于观察到更多的东西。如果能有组织地记录下所有东西会更好。
还好,我们前面使用的可视化和我们现在所期望的效果是一样的机制(mechanisms)。
我们通过添加一个对状态进行摘要的 ops 来描述(instrument)计算图。在此,我们将创建一个 op 来反映(reports)目前 y 的值,也就是神经元的实际输出。
>>> summary_y = tf.scalar_summary('output', y)
当你运行这个具有摘要功能的 op,会返回缓冲协议文本的字符串,利用 SummaryWriter 可以被写入日志目录。
>>> summary_writer = tf.train.SummaryWriter('log_simple_stats')
>>> sess.run(tf.initialize_all_variables())
>>> for i in range(100):
>>> summary_str = sess.run(summary_y)
>>> summary_writer.add_summary(summary_str, i)
>>> sess.run(train_step)
>>>
运行 tensorboard --logdir=log_simple_stats,在 localhost:6006/#events(图 3)可以看到交互的绘图。
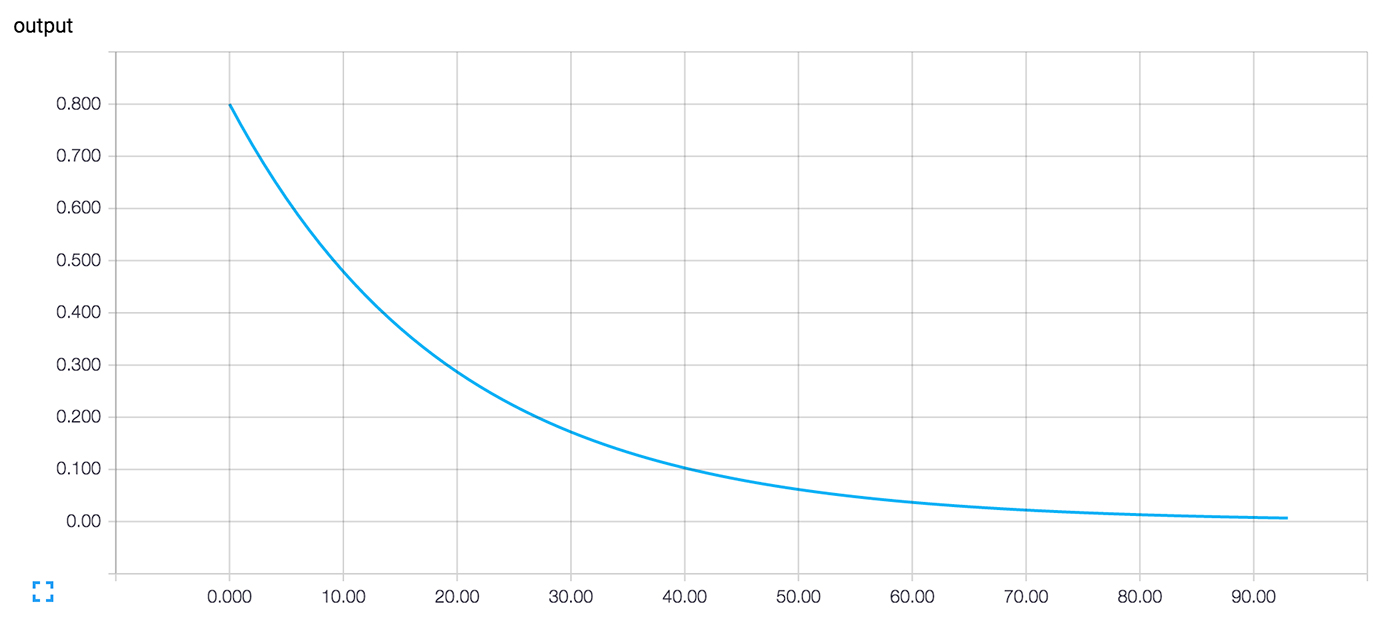
图 3:训练迭代数字与神经元输出在 TensorBoard 下的可视化
继续前进(Flowing onward)
下面是最终版的代码。实在是很短,每个部分都能看出 TensorFlow 的有效和易懂。
import tensorflow as tf
x = tf.constant(1.0, name='input')
w = tf.Variable(0.8, name='weight')
y = tf.mul(w, x, name='output')
y_ = tf.constant(0.0, name='correct_value')
loss = tf.pow(y - y_, 2, name='loss')
train_step = tf.train.GradientDescentOptimizer(0.025).minimize(loss)
for value in [x, w, y, y_, loss]:
tf.scalar_summary(value.op.name, value)
summaries = tf.merge_all_summaries()
sess = tf.Session()
summary_writer = tf.train.SummaryWriter('log_simple_stats', sess.graph)
sess.run(tf.initialize_all_variables())
for i in range(100):
summary_writer.add_summary(sess.run(summaries), i)
sess.run(train_step)
我们这次运行的示例甚至比在 Michael Nielsen 的 Neural Networks and Deep Learning 中受到启发的例子还要简单。就我个人而言,像这样从细节入手有助于理解和构建更复杂的系统,因为它们都是从简单的建筑模块延生来的。TensorFlow 其中一个优美之处就在于非常灵活,你可以通过简单的组件构建出更复杂的系统。
如果你想继续实践 TensorFlow,创建更有趣的神经元,也许激励函数(activation functions)还不一样,但这一定很有意思。你可以用更多有趣的数据来训练;添加更多的神经元;添加更多的层;你也可以深入更复杂的预建模型(pre-built models);或者花更多时间在 TensorFlow 的官方教程和文档(how-to guides)。加油吧!
致谢
感谢 Paco Nathan, Ben Lorica, 和 Marie Beaugureau 让本文成真了。感谢 Deep Learning Analytics 的 Henry Chen, Dennis Leung, 和 Paul Gulley,并感谢 DC Machine Learning Journal Club 对早期版本提供了有价值的反馈。再一次感谢 Marie Beaugureau 和 Jenn Webb,大幅提升了最终版的水准。
作者介绍
Aaron Schumacher 是 Deep Learning Analytics 的数据科学家以及软件工程师。他在 General Assembly 和 Metis 数据科学训练营地(bootcamp)营地教授过 Python 和 R。Aaron 曾在 Booz Allen Hamilton,纽约大学和 New York City Department of Education 从事过数据方面的工作。Aaron 霹雳舞最好的赛绩是进入到了 R16 Korea 2009 individual footwork battle 的半决赛。他为能在 TensorFlow 0.9 中略尽绵力而感到骄傲。
打赏支持我翻译更多好文章,谢谢!
打赏译者
打赏支持我翻译更多好文章,谢谢!
任选一种支付方式


相关内容
- TensorFlow与中文手写汉字识别,tensorflow汉字识别,具体在
- TensorFlow 实战:Neural Style,tensorflowneural, TensorFlow是
- 图解机器学习:神经网络和 TensorFlow 的文本分类,神经
- 实现属于自己的TensorFlow(1):计算图与前向传播,属于自
- 实现属于自己的TensorFlow(二) - 梯度计算与反向传播,
- TensorFlow变量管理详解,tensorflow变量详解
- tensorflow获取变量维度信息,tensorflow变量维度
- python使用TensorFlow进行图像处理的方法,pythontensorflow
- TensorFlow实现RNN循环神经网络,tensorflowrnn
- Tensorflow 利用tf.contrib.learn建立输入函数的方法,
评论关闭