python性能分析,python性能,性能分析就是分析代码和它
python性能分析,python性能,性能分析就是分析代码和它
调优简介
什么是性能分析
没有优化过的程序通常会在某些子程序(subroutine)上消耗大部分的CPU指令周期(CPU cycle)。性能分析就是分析代码和它正在使用的资源之间有着怎样的关系。例如,性能分析可以告诉你一个指令占用了多少CPU时间,或者整个程序消耗了多少内存。性能分析是通过使用一种被称为性能分析器(profiler)的工具,对程序或者二进制可执行文件(如果可以拿到)的源代码进行调整来完成的。
性能分析软件有两类方法论:基于事件的性能分析(event-based profiling)和统计式性能分析(statistical profiling)。
支持这类基于事件的性能分析的编程语言主要有以下几种。
- Java:JVMTI(JVM Tools Interface,JVM工具接口)为性能分析器提供了钩子,可以跟踪诸如函数调用、线程相关的事件、类加载之类的事件。
- .NET:和Java一样,.NET运行时提供了事件跟踪功能(https://en.wikibooks.org/wiki/Intro-duction_to_Software_Engineering/Testing/Profiling#Methods_of_data_gathering)。
- Python: 开发者可以用 sys.setprofile 函数,跟踪 python_[call|return|exception]或 c_[call|return|exception] 之类的事件。
基于事件的性能分析器(event-based profiler,也称为轨迹性能分析器,tracing profiler)是通过收集程序执行过程中的具体事件进行工作的。这些性能分析器会产生大量的数据。基本上,它们需要监听的事件越多,产生的数据量就越大。这导致它们不太实用,在开始对程序进行性能分析时也不是首选。但是,当其他性能分析方法不够用或者不够精确时,它们可以作为最后的选择。
Python基于事件的性能分析器的简单示例代码
import sys
def profiler(frame, event, arg):
print 'PROFILER: %r %r' % (event, arg)
sys.setprofile(profiler)
#simple (and very ineficient) example of how to calculate the Fibonacci sequence for a number.
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def fib_seq(n):
seq = [ ]
if n > 0:
seq.extend(fib_seq(n-1))
seq.append(fib(n))
return seq
print fib_seq(2)
执行结果:
Python$ python test.py PROFILER: 'call' None PROFILER: 'call' None PROFILER: 'call' None PROFILER: 'call' None PROFILER: 'return' 0 PROFILER: 'c_call' <built-in method append of list object at 0x7f113d7f67a0> PROFILER: 'c_return' <built-in method append of list object at 0x7f113d7f67a0> PROFILER: 'return' [0] PROFILER: 'c_call' <built-in method extend of list object at 0x7f113d7e0d40> PROFILER: 'c_return' <built-in method extend of list object at 0x7f113d7e0d40> PROFILER: 'call' None PROFILER: 'return' 1 PROFILER: 'c_call' <built-in method append of list object at 0x7f113d7e0d40> PROFILER: 'c_return' <built-in method append of list object at 0x7f113d7e0d40> PROFILER: 'return' [0, 1] PROFILER: 'c_call' <built-in method extend of list object at 0x7f113d7e0758> PROFILER: 'c_return' <built-in method extend of list object at 0x7f113d7e0758> PROFILER: 'call' None PROFILER: 'call' None PROFILER: 'return' 1 PROFILER: 'call' None PROFILER: 'return' 0 PROFILER: 'return' 1 PROFILER: 'c_call' <built-in method append of list object at 0x7f113d7e0758> PROFILER: 'c_return' <built-in method append of list object at 0x7f113d7e0758> PROFILER: 'return' [0, 1, 1] [0, 1, 1] PROFILER: 'return' None PROFILER: 'call' None PROFILER: 'c_call' <built-in method discard of set object at 0x7f113d818960> PROFILER: 'c_return' <built-in method discard of set object at 0x7f113d818960> PROFILER: 'return' None PROFILER: 'call' None PROFILER: 'c_call' <built-in method discard of set object at 0x7f113d81d3f0> PROFILER: 'c_return' <built-in method discard of set object at 0x7f113d81d3f0> PROFILER: 'return' None
统计式性能分析器以固定的时间间隔对程序计数器(program counter)进行抽样统计。这样做可以让开发者掌握目标程序在每个函数上消耗的时间。由于它对程序计数器进行抽样,所以数据结果是对真实值的统计近似。不过,这类软件足以窥见被分析程序的性能细节,查出性能瓶颈之所在。它使用抽样的方式(用操作系统中断),分析的数据更少,对性能造成的影响更小。
Linux统计式性能分析器OProfile(http://oprofile.sourceforge.net/news/)的分析结果:
Function name,File name,Times Encountered,Percentage "func80000","statistical_profiling.c",30760,48.96% "func40000","statistical_profiling.c",17515,27.88% "func20000","static_functions.c",7141,11.37% "func10000","static_functions.c",3572,5.69% "func5000","static_functions.c",1787,2.84% "func2000","static_functions.c",768,1.22% func1500","statistical_profiling.c",701,1.12% "func1000","static_functions.c",385,0.61% "func500","statistical_profiling.c",194,0.31%
下面我们使用statprof进行分析:
import statprof
def profiler(frame, event, arg):
print 'PROFILER: %r %r' % (event, arg)
#simple (and very ineficient) example of how to calculate the Fibonacci sequence for a number.
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def fib_seq(n):
seq = [ ]
if n > 0:
seq.extend(fib_seq(n-1))
seq.append(fib(n))
return seq
statprof.start()
try:
print fib_seq(20)
finally:
statprof.stop()
statprof.display()
执行结果:
Python$ python test.py [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765] % cumulative self time seconds seconds name 100.00 0.01 0.01 test.py:15:fib 0.00 0.01 0.00 test.py:21:fib_seq 0.00 0.01 0.00 test.py:20:fib_seq 0.00 0.01 0.00 test.py:27:<module> --- Sample count: 2 Total time: 0.010000 seconds
注意上面代码我们把计算fib_seq的参数从2改成20,因为执行时间太快的情况下,statprof是获取不到任何信息的。
性能分析的重要性
性能分析并不是每个程序都要做的事情,尤其对于那些小软件来说,是没多大必要的(不像那些杀手级嵌入式软件或专门用于演示的性能分析程序)。性能分析需要花时间,而且只有在程序中发现了错误的时候才有用。但是,仍然可以在此之前进行性能分析,捕获潜在的bug,这样可以节省后期的程序调试时间。
我们已经拥有测试驱动开发、代码审查、结对编程,以及其他让代码更加可靠且符合预期的手段,为什么还需要性能分析?
随着我们使用的编程语言越来越高级(几年间我们就从汇编语言进化到了JavaScript),我们愈加不关心CPU循环周期、内存配置、CPU寄存器等底层细节了。新一代程序员都通过高级语言学习编程技术,因为它们更容易理解而且开箱即用。但它们依然是对硬件和与硬件交互行为的抽象。随着这种趋势的增长,新的开发者越来越不会将性能分析作为
软件开发中的一个步骤了。
如今,随便开发一个软件就可以获得上千用户。如果通过社交网络一推广,用户可能马上就会呈指数级增长。一旦用户量激增,程序通常会崩溃,或者变得异常缓慢,最终被客户无情抛弃。
上面这种情况,显然可能是由于糟糕的软件设计和缺乏扩展性的架构造成的。毕竟,一台服务器有限的内存和CPU资源也可能会成为软件的瓶颈。但是,另一种可能的原因,也是被证明过许多次的原因,就是我们的程序没有做过压力测试。我们没有考虑过资源消耗情况;我们只保证了测试已经通过,而且乐此不疲。
性能分析可以帮助我们避免项目崩溃夭折,因为它可以相当准确地为我们展示程序运行的情况,不论负载情况如何。因此,如果在负载非常低的情况下,通过性能分析发现软件在I/O操作上消耗了80%的时间,那么这就给了我们一个提示。是产品负载过重时,内存泄漏就可能发生。性能分析可以在负载真的过重之前,为我们提供足够的证据来发现这类隐患。
性能分析的内容
- 运行时间
如果你对运行的程序有一些经验(比如说你是一个网络开发者,正在使用一个网络框架),可能很清楚运行时间是不是太长。例如,一个简单的网络服务器查询数据库、响应结果、反馈到客户端,一共需要100毫秒。但是,如果程序运行得很慢,做同样的事情需要花费60秒,你就得考虑做性能分析了。
import datetime
tstart = None
tend = None
def start_time():
global tstart
tstart = datetime.datetime.now()
def get_delta():
global tstart
tend = datetime.datetime.now()
return tend - tstart
def fib(n):
return n if n == 0 or n == 1 else fib(n-1) + fib(n-2)
def fib_seq(n):
seq = [ ]
if n > 0:
seq.extend(fib_seq(n-1))
seq.append(fib(n))
return seq
start_time()
print "About to calculate the fibonacci sequence for the number 30"
delta1 = get_delta()
start_time()
seq = fib_seq(30)
delta2 = get_delta()
print "Now we print the numbers: "
start_time()
for n in seq:
print n
delta3 = get_delta()
print "====== Profiling results ======="
print "Time required to print a simple message: %(delta1)s" % locals()
print "Time required to calculate fibonacci: %(delta2)s" % locals()
print "Time required to iterate and print the numbers: %(delta3)s" %locals()
print "====== ======="
执行结果:
$ python test.py About to calculate the fibonacci sequence for the number 30 Now we print the numbers: 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181 6765 10946 17711 28657 46368 75025 121393 196418 317811 514229 832040 ====== Profiling results ======= Time required to print a simple message: 0:00:00.000064 Time required to calculate fibonacci: 0:00:01.430740 Time required to iterate and print the numbers: 0:00:00.000075 ====== =======
可见计算部分是最消耗时间的。
- 发现瓶颈
只要你测量出了程序的运行时间,就可以把注意力移到运行慢的环节上做性能分析。一般瓶颈由下面的一种或者几种原因组成:
* 重的I/O操作,比如读取和分析大文件,长时间执行数据库查询,调用外部服务(比如HTTP请求),等等。
* 现了内存泄漏,消耗了所有的内存,导致后面的程序没有内存来正常执行。
* 未经优化的代码频繁执行。
* 可以缓存时密集的操作没有缓存,占用了大量资源。
I/O关联的代码(文件读/写、数据库查询等)很难优化,因为优化有可能会改变程序执行I/O操作的方式(通常是语言的核心函数操作I/O)。相反,优化计算关联的代码(比如程序使用的算法很糟糕),改善性能会比较容易(并不一定很简单)。这是因为优化计算关联的代码就是改写程序。
内存消耗和内存泄漏
内存消耗不仅仅是关注程序使用了多少内存,还应该考虑控制程序使用内存的数量。跟踪程序内存的消耗情况比较简单。最基本的方法就是使用操作系统的任务管理器。它会显示很多信息,包括程序占用的内存数量或者占用总内存的百分比。任务管理器也是检查CPU时间使用情况的好工具。在下面的top截图中,你会发现一个简单的Python程序(就是前面那段程序)几乎占用了全部CPU(99.8%),内存只用了0.1%。
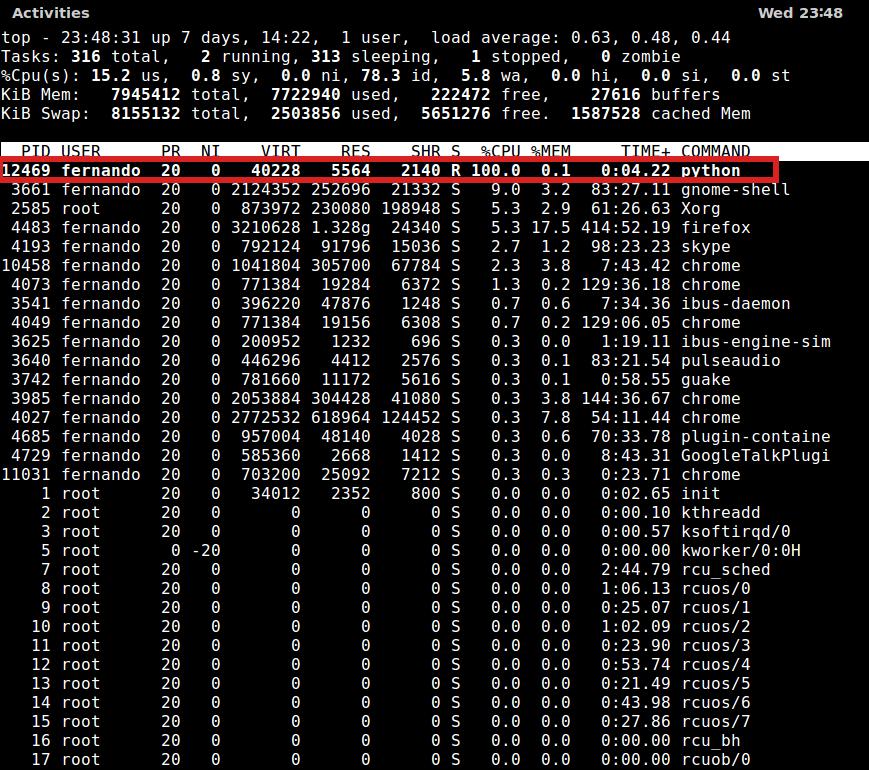
当运行过程启动之后,内存消耗会在一个范围内不断增加。如果发现增幅超出范围,而且消
耗增大之后一直没有回落,就可以判断出现内存泄漏了。
过早优化的风险
优化通常被认为是一个好习惯。但是,如果一味优化反而违背了软件的设计原则就不好了。在开始开发一个新软件时,开发者经常犯的错误就是过早优化(permature optimization)。如果过早优化代码,结果可能会和原来的代码截然不同。它可能只是完整解决方案的一部分,还可能包含因优化驱动的设计决策而导致的错误。一条经验法则是,如果你还没有对代码做过测量(性能分析)
,优化往往不是个好主意。首先,应该集中精力完成代码,然后通过性能分析发现真正的性能瓶颈,最后对代码进行优化。
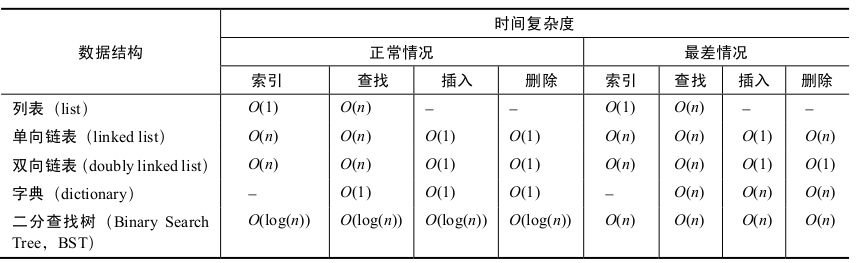
运行时间复杂度
运行时间复杂度(Running Time Complexity,RTC)用来对算法的运行时间进行量化。它是对算法在一定数量输入条件下的运行时间进行数学近似的结果。因为是数学近似,所以我们可以用这些数值对算法进行分类。
RTC常用的表示方法是大O标记(big O notation)。数学上,大O标记用于表示包含无限项的
函数的有限特征(类似于泰勒展开式)。如果把这个概念用于计算机科学,就可以把算法的运行
时间描述成渐进的有限特征(数量级)。
主要模型有:
- 常数时间——O(1):比如判断一个数是奇数还是偶数、用标准输出方式打印信息等。对于理论上更复杂的操作,比如在字典(或哈希表)中查找一个键的值,如果算法合理,就
可以在常数时间内完成。技术上看,在哈希表中查找元素的消耗时间是O(1)平均时间,这意味着每次操作的平均时间(不考虑特殊情况)是固定值O(1)。 - 线性时间——O(n):比如查找无序列表中的最小元素、比较两个字符串、删除链表中的最后一项
- 对数时间——O(logn):对数时间(logarithmic time)复杂度的算法,表示随着输入数量的增加,算法的运行时间会达到固定的上限。随着输入数量的增加,对数函数开始增长很快,然后慢慢减速。它不会停止增长,但是越往后增长的速度越慢,甚至可以忽略不计。比如:二分查找(binary search)、计算斐波那契数列(用矩阵乘法)。
- 线性对数时间——O(nlogn):把前面两种时间类型组合起来就变成了线性对数时间(linearithmic time)。随着x的增大,算法的运行时间会快速增长。比如归并排序(merge sort)、堆排序(heap sort)、快速排序(quick sort,至少是平均运行时间)
- 阶乘时间——O(n!):阶乘时间(factorial time)复杂度的算法是最差的算法。其时间增速特别快,图都很难画。比如:用暴力破解搜索方法解货郎担问题(遍历所有可能的路
径)。 - 平方时间——O(n 2 ):平方时间是另一个快速增长的时间复杂度。输入数量越多,需要消耗的时间越长(大多数算法都是这样,这类算法尤其如此)。平方时间复杂度的运行效率比线性时间复杂度要慢。比如冒泡排序(bubble sort)、遍历二维数组、插入排序(insertion sort)
速度:对数>线性>线性对数>平方>阶乘, 要考虑最好情况、正常情况和最差情况。
性能分析最佳实践
建立回归测试套件、思考代码结构、耐心、尽可能多地收集数据(其他数据资源,如网络应用的系统日志、自定义日志、系统资源快照(如操作系统任务管理器))、数据预处理、数据可视化
python中最出名的性能分析库:cProfile、line_profiler。
前者是标准库:https://docs.python.org/2/library/profile.html#module-cProfile。
后者参见:https://github.com/rkern/line_profiler。
专注于CPU时间。
评论关闭