Python数据处理:Pandas模块的 12 种实用技巧,pythonpandas,未经许可,禁止转载!英文
Python数据处理:Pandas模块的 12 种实用技巧,pythonpandas,未经许可,禁止转载!英文
本文由 编橙之家 - a58797 翻译,LynnShaw 校稿。未经许可,禁止转载!英文出处:AARSHAY JAIN。欢迎加入翻译组。
简介
Python 正迅速成为数据科学家们更为钟爱的编程语言。形成该现状的理由非常充分:Python 提供了一种覆盖范围更为广阔的编程语言生态系统,以及具有一定计算深度且性能良好的科学计算库。如果您是 Python 初学者,建议首先看下Python 学习路线。
在 Python 自带的科学计算库中,Pandas 模块是最适于数据科学相关操作的工具。它与 Scikit-learn 两个模块几乎提供了数据科学家所需的全部工具。本文着重介绍了 Python 中数据处理的 12 种方法。此前的文章里也分享了一些技巧和经验,这些将有助于您提高工作效率。
在本文开始前,推荐读者首先了解一些数据挖掘的相关代码。为使本文更易于理解,我们事先选定了一个数据集以示范相关操作和处理方法。
数据集来源:本文采用的是贷款预测问题的数据集。请下载该数据集并开始本文内容。

让我们开始吧
首先导入相关模块并加载数据集到 Python 环境中:
Python
import pandas as pd
import numpy as np
data = pd.read_csv("train.csv", index_col="Loan_ID")
#1 – 布尔索引
如果需要以其它列数据值为条件过滤某一列的数据,您会怎么处理?例如建立一个列表,列表中全部为未能毕业但曾获得贷款的女性。这里可以使用布尔索引,代码如下:
Pythondata.loc[(data["Gender"]=="Female") & (data["Education"]=="Not Graduate") & (data["Loan_Status"]=="Y"), ["Gender","Education","Loan_Status"]]
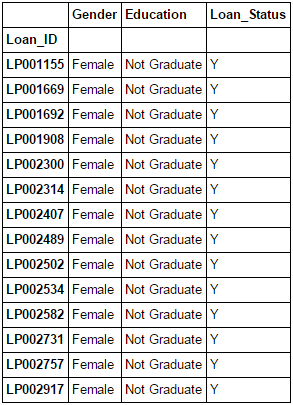
更多内容请参阅:利用 Pandas 模块进行选择和索引
#2 – Apply 函数
Apply 函数是处理数据和建立新变量的常用函数之一。在向数据框的每一行或每一列传递指定函数后,Apply 函数会返回相应的值。这个由 Apply 传入的函数可以是系统默认的或者用户自定义的。例如,在下面的例子中它可以用于查找每一行和每一列中的缺失值。
Python#Create a new function: def num_missing(x): return sum(x.isnull()) #Applying per column: print "Missing values per column:" print data.apply(num_missing, axis=0) #axis=0 defines that function is to be applied on each column #Applying per row: print "nMissing values per row:" print data.apply(num_missing, axis=1).head() #axis=1 defines that function is to be applied on each row
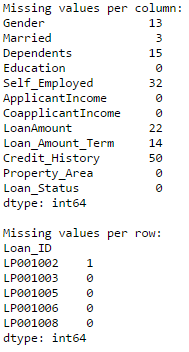
这样我们就得到了所需的结果。
注:由于输出结果包含多行数据,第二个输出函数使用了 head() 函数以限定输出数据长度。在不限定输入参数时 head() 函数默认输出 5 行数据。
更多内容请参阅:Pandas 参考(apply 函数)
#3 – 填补缺失值
fillna() 函数可一次性完成填补功能。它可以利用所在列的均值/众数/中位数来替换该列的缺失数据。下面利用“Gender”、“Married”、和“Self_Employed”列中各自的众数值填补对应列的缺失数据。
Python#First we import a function to determine the mode from scipy.stats import mode mode(data['Gender'])
输出结果为:ModeResult(mode=array([‘Male’], dtype=object), count=array([489]))
输出结果返回了众数值和对应次数。需要记住的是由于可能存在多个高频出现的重复数据,因此众数可以是一个数组。通常默认使用第一个众数值:
Pythonmode(data['Gender']).mode[0]
![]()
现在可以进行缺失数据值填补并利用#2方法进行检查。
Python#Impute the values: data['Gender'].fillna(mode(data['Gender']).mode[0], inplace=True) data['Married'].fillna(mode(data['Married']).mode[0], inplace=True) data['Self_Employed'].fillna(mode(data['Self_Employed']).mode[0], inplace=True) #Now check the #missing values again to confirm: print data.apply(num_missing, axis=0)
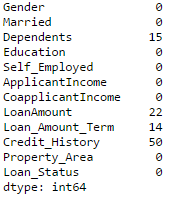
至此,可以确定缺失值已经被填补。请注意,上述方法是最基本的填补方法。包括缺失值建模,用分组平均数(均值/众数/中位数)填补在内的其他复杂方法将在接下来的文章中进行介绍。
更多内容请参阅:Pandas 参考( fillna 函数)
#4 – 数据透视表
Pandas 可建立 MS Excel 类型的数据透视表。例如在下文的代码段里,关键列“LoanAmount” 存在缺失值。我们可以根据“Gender”,“Married”和“Self_Employed”分组后的平均金额来替换。 “LoanAmount”的各组均值可由如下方法确定:
Python#Determine pivot table impute_grps = data.pivot_table(values=["LoanAmount"], index=["Gender","Married","Self_Employed"], aggfunc=np.mean) print impute_grps
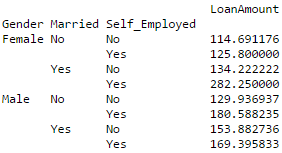
更多内容请参阅:Pandas 参考(数据透视表)
#5 – 复合索引
如果您注意观察#3计算的输出内容,会发现它有一个奇怪的性质。即每个索引均由三个数值的组合构成,称为复合索引。它有助于运算操作的快速进行。
从#3的例子继续开始,已知每个分组数据值但还未进行数据填补。具体的填补方式可结合此前学到的多个技巧来完成。
Python#iterate only through rows with missing LoanAmount for i,row in data.loc[data['LoanAmount'].isnull(),:].iterrows(): ind = tuple([row['Gender'],row['Married'],row['Self_Employed']]) data.loc[i,'LoanAmount'] = impute_grps.loc[ind].values[0] #Now check the #missing values again to confirm: print data.apply(num_missing, axis=0)
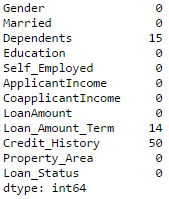
Note:
注:
1. 多值索引需要在 loc 语句中使用用于定义索引分组的元组结构。该元组会在函数中使用。
2. 应使用后缀 .values[0] 以避免潜在的错误。因为默认情况下复合索引返回的 Series 元素索引顺序与所在的数据框架(dataframe)不一致。在此条件下直接赋值会产生错误。
#6 – Crosstab 函数
该函数用于获取数据的初始印象(直观视图),从而验证一些基本假设。例如在本例中,“Credit_History”被认为会显著影响贷款状态。这个假设可以通过如下代码生成的交叉表进行验证:
Pythonpd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True)
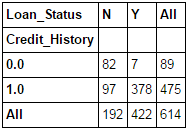
以上这些都是绝对值。但百分比形式能获得更为直观的数据结果。使用 apply 函数可实现该功能:
Pythondef percConvert(ser): return ser/float(ser[-1]) pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True).apply(percConvert, axis=1)
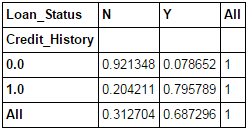
现在可以证明:与仅占9%的无信用记录人群相比,占比为80%的有信用记录人群获得贷款的几率会更高。
但这并不是全部的数据结果,其中还包含了一个有趣的内容。既然已知有信用记录非常重要,如果利用信用记录情况进行贷款预测会如何?其中,预测有信用记录的人的获得贷款状态为 Y,否则为 N。令人吃惊的是在614次测试中,共正确预测了 82+378=460 次,正确率高达75%!
如果您正好奇为什么我们需要统计模型,我一点儿也不会责怪您。但是请相信,提高预测精度是一项非常具有挑战性的任务,哪怕仅仅是在上述预测结果的基础上提高0.001%的预测精度也是如此。您会接受这个挑战吗?
注:75% 是对本文的训练数据集而言。测试数据集的结果将会有所不同,但也非常接近。同样地,希望通过这个例子能让大家明白为什么仅仅提高0.05%的预测精度就可在Kaggle排行榜中排名跃升500位。
更多内容请参阅:Pandas 模块参考( crosstab 函数)
#7 – 合并数据框(DataFrames)
当有来自不同数据源的信息需要收集整理时,合并数据框就变成了一项必不可少的基本操作。考虑一个假设的情况,即不同类型的房产有不同的均价(单位:INR / 平方米)。定义数据框如下:
Pythonprop_rates = pd.DataFrame([1000, 5000, 12000], index=['Rural','Semiurban','Urban'],columns=['rates']) prop_rates
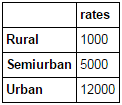
现在可将上述信息与原始数据框合并如下:
Pythondata_merged = data.merge(right=prop_rates, how='inner',left_on='Property_Area',right_index=True, sort=False) data_merged.pivot_table(values='Credit_History',index=['Property_Area','rates'], aggfunc=len)
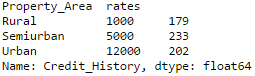
上述透视表验证了合并操作成功。需要注意的是由于上述代码仅对数据值进行简单计算,因此‘values’参数在本例中是一个独立内容,与上下文无关。
更多内容请参阅:Pandas 参考( merge 函数)
#8 – 排列数据框架(DataFrames)
Pandas 允许基于多列数据进行简单排列。具体实现如下:
Pythondata_sorted = data.sort_values(['ApplicantIncome','CoapplicantIncome'], ascending=False) data_sorted[['ApplicantIncome','CoapplicantIncome']].head(10)
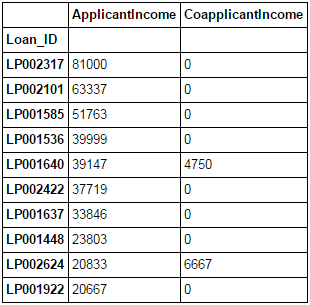
注:Pandas模块中的“sort”函数现已不再使用,应用“sort_values”函数进行代替。
更多内容请参阅:Pandas 参考( sort_values 函数)
#9 – 绘图(Boxplot 和 Histogram 函数)
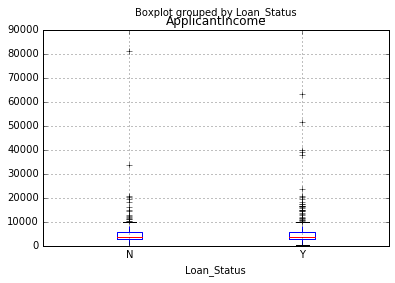
许多人也许并没有意识到 Pandas 模块中的 boxplots 和 histograms 函数可以用于直接绘图,此时没有必要再单独调用 matplotlib 模块。一行命令即可完成相关功能。例如,如果想通过 Loan_Status 比较 ApplicantIncome 的分布情况,则实现代码如下:
Pythonimport matplotlib.pyplot as plt %matplotlib inline data.boxplot(column="ApplicantIncome",by="Loan_Status")
data.hist(column="ApplicantIncome",by="Loan_Status",bins=30)
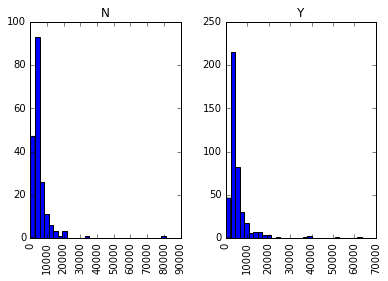
上图的数据结果表明,由于获得贷款人群和未获得贷款人群数没有明显的收入差距,因此个人收入水平高低并非是否能获得贷款的主要决定因素。
更多内容请参阅:Pandas 参考( hist 函数)|( boxplot 函数)
#10 – 使用 Cut 函数进行分箱
有时将数值数据聚合在一起会更有意义。例如,如果我们要根据一天中的某个时间段(单位:分钟)建立交通流量模型模型(以路上的汽车为统计目标)。与具体的分钟数相比,对于交通流量预测而言一天中的具体时间段则更为重要,如“早上”、 “下午”、“傍晚”、“夜晚”、“深夜(Late Night)”。以这种方式建立交通流量模型则更为直观且避免了过拟合情况的发生。
下面的例子中定义了一个简单的可重用函数,该函数可以非常轻松地实现任意变量的分箱功能。
Python
#Binning:
def binning(col, cut_points, labels=None):
#Define min and max values:
minval = col.min()
maxval = col.max()
#create list by adding min and max to cut_points
break_points = [minval] + cut_points + [maxval]
#if no labels provided, use default labels 0 ... (n-1)
if not labels:
labels = range(len(cut_points)+1)
#Binning using cut function of pandas
colBin = pd.cut(col,bins=break_points,labels=labels,include_lowest=True)
return colBin
#Binning age:
cut_points = [90,140,190]
labels = ["low","medium","high","very high"]
data["LoanAmount_Bin"] = binning(data["LoanAmount"], cut_points, labels)
print pd.value_counts(data["LoanAmount_Bin"], sort=False)
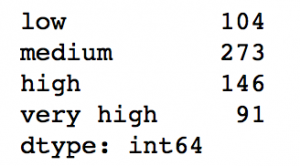
Read More: Pandas Reference (cut)
更多内容请参阅:Pandas 参考( cut 函数)
#11 – 为名义变量编码
通常我们会遇到需要对名义变量进行分类的情况。可能的原因如下:
1. 一些算法(如逻辑回归算法)要求输入参数全部为数字。因此名义变量多需要编码为0, 1….(n-1)。
2. 有时同一种分类可以表示为两种形式。如温度可能被记录为“高(High)”、“中(Medium)”、“低(Low)”、“高(H)”、“低(low)”。在这里,“高(High)”和“高(H)”都表示同一种分类。类似地在“低(Low)”和“低(low)”的表示方法中仅存在大小写的区别。但 python 将会将它们视为不同的温度水平。
3.一些分类的出现频率可能较低,因此将这些分类归为一类不失为一个好主意。
下面的例子中定义了一个通用函数,该函数使用字典作为输入,并利用 Pandas 模块的‘replace’函数对字典值进行编码。
Python
#Define a generic function using Pandas replace function
def coding(col, codeDict):
colCoded = pd.Series(col, copy=True)
for key, value in codeDict.items():
colCoded.replace(key, value, inplace=True)
return colCoded
#Coding LoanStatus as Y=1, N=0:
print 'Before Coding:'
print pd.value_counts(data["Loan_Status"])
data["Loan_Status_Coded"] = coding(data["Loan_Status"], {'N':0,'Y':1})
print 'nAfter Coding:'
print pd.value_counts(data["Loan_Status_Coded"])
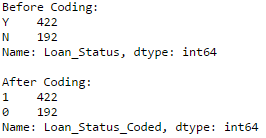
编码前后的计数结果一致,证明编码正确。
更多内容请参阅:Pandas 参考( replace 函数)
#12 – 对数据框的行数据进行迭代
这个操作不经常使用。但您也不希望被这个问题卡住,对吧?有时需要利用 for 循环对所有行数据进行迭代。例如一个常见的问题即是 Python 中变量的不当处理。通常发生在如下情况:
1.带有数字的名义变量被认为是数值数据。
2.由于数据错误,带有字符的数值变量输入行数据中时被认为是分类变量。
因此手动定义列数据类型会是一个不错的主意。如果检查所有列数据的数据类型:
Python#Check current type: data.dtypes

会看到名义变量 Credit_History 被显示为 float 类型。解决这种问题的一个好方法即是创建一个包含列名和对应类型的 csv 文件。这样就可以定义一个通用函数来读取文件,并指定列数据的类型。例如在下面的例子里建立了一个 csv 文件“datatypes.csv”。
Python
#Load the file:
colTypes = pd.read_csv('datatypes.csv')
print colTypes

加载数据后可以对每一行进行迭代,并利用‘type’列中的数据内容确定‘feature’列中对应变量名的数据类型。
Python
#Iterate through each row and assign variable type.
#Note: astype is used to assign types
for i, row in colTypes.iterrows(): #i: dataframe index; row: each row in series format
if row['type']=="categorical":
data[row['feature']]=data[row['feature']].astype(np.object)
elif row['type']=="continuous":
data[row['feature']]=data[row['feature']].astype(np.float)
print data.dtypes

现在 credit history 列被定义为了 ‘object’ 类型,该类型即为 Pandas 模块中用于表示名义变量的数据类型。
更多内容请参阅:Pandas 参考( iterrows 函数)
结语
在这篇文章中,我们介绍了 Pandas 的多个函数,这些函数使得我们数据挖掘和特征工程上更加轻松。同时我们定义了一些可重用的通用函数,以在处理不同的数据集时可以获得类似目标结果。
另请参见:如果您有任何关于 Pandas 模块或 Python 的疑问,请随时与我们讨论。
相关内容
- 用Python Pandas处理亿级数据,pandas亿级,这次拿到近亿条
- 详解 Pandas 透视表(pivot_table),pandaspivot_table,未经许可
- Pandas初学者代码优化指南,pandas初学者指南,通过赋予
- Python 数据处理库 pandas 入门教程,pythonpandas,是对它的一
- Python 数据处理库 pandas 进阶教程,pythonpandas,是它的进阶
- 十分钟搞定pandas,十分钟pandas,可以参阅Cookbook
- 用 Scikit-Learn 和 Pandas 学习线性回归,scikit-learnpandas,1
- python实现城市和省份字典(根据城市判断属于哪个省份
- 泰坦尼克号生存预测(python),泰坦尼克号python,1 数据
- python时间日期函数与利用pandas进行时间序列处理详解,
评论关闭