【Python3爬虫】有道翻译,python3爬虫有道,准备:Python3
【Python3爬虫】有道翻译,python3爬虫有道,准备:Python3
准备:Python3.5+Chrome+Pycharm
步骤:
(1)打开有道翻译的网页,然后鼠标右键检查(或者按F12),再输入一个单词(例如book),在XHR选项中可以看到这条信息,也就是说我们要利用post把要翻译的内容发送出去,然后再获取返回的信息,就能得到翻译的结果了。?
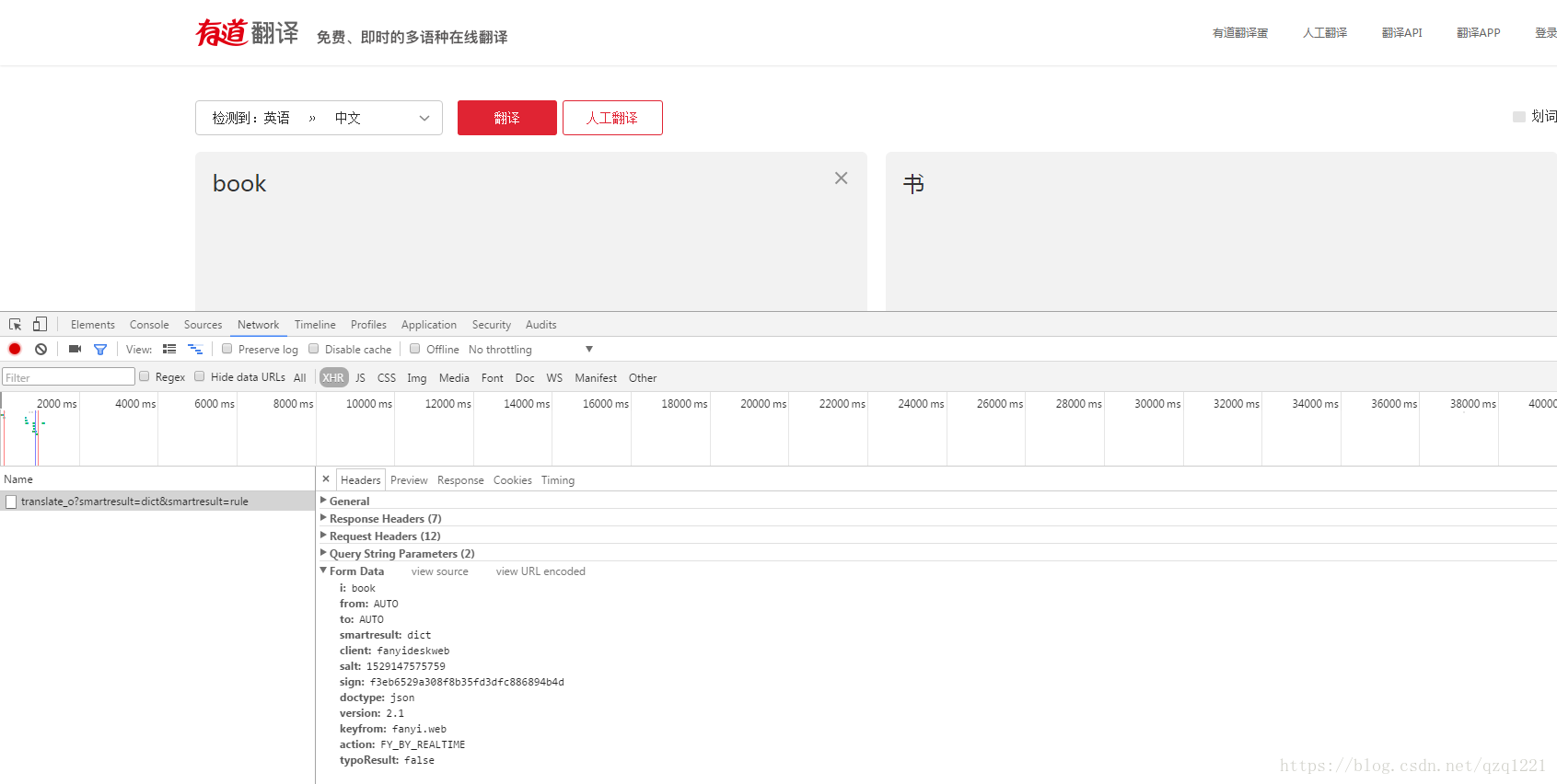
(2)打开Pycharm,新建一个test.py,代码如下:
import requestsdef main(): txt = input("请输入要翻译的内容:") data = { "i": txt, "from": "AUTO", "to": "AUTO", "smartresult": "dict", "client": "fanyideskweb", "doctype": "json", "version": "2.1", "keyfrom": "fanyi.web", "action": "FY_BY_REALTIME", "typoResult": "true" } url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" res = requests.post(url, data=data) js = res.json() print("翻译结果:" + js[‘translateResult‘][0][0][‘tgt‘] + ‘\n‘)if __name__ == ‘__main__‘: while True: main()我使用的是requests库,这里使用post请求返回的结果是一个字典:{‘translateResult‘: [[{‘tgt‘: ‘书‘, ‘src‘: ‘book‘}]], ‘errorCode‘: 0, ‘elapsedTime‘: 0, ‘type‘: ‘EN2ZH_CN‘},然后我们用[‘translateResult‘][0][0][‘tgt‘]把翻译的结果提取出来就行了。
注意:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule这个链接里要把translate后面的_o去掉,如果不去掉,post请求返回的是‘errorCode‘:50,至于原因,我这个小白也不清楚==
【Python3爬虫】有道翻译
相关内容
- Selenium+Python定位实例,seleniumpython定位,常见的定位方式
- python 一个包中的文件调用另外一个包文件 实例,py
- 廖雪峰python实战,廖雪峰python,1.ORM框架从使用
- python错误 invalid command 'bdist_wheel' &
- OCR识别-python3.5版,ocr识别-python3.5,刚接触,啥子都不会
- python3.6使用pygal模块不具交互性,图片不能显示数据,
- ubuntu 16.04 python 3.x 安装OpenSSL,16.04openssl,错误提示:C
- Python 可视化TVTK CubeSource管线初使用,tvtkcubesource,
- 【专栏】Python在DevOps中的应用,专栏pythondevops,互联网时
- python出现关于模块(i18n)的不能使用的解决方法,py
评论关闭