Python 爬虫实例(7)—— 爬取 新浪军事新闻,python新浪军事,我们打开新浪新闻,看
Python 爬虫实例(7)—— 爬取 新浪军事新闻,python新浪军事,我们打开新浪新闻,看
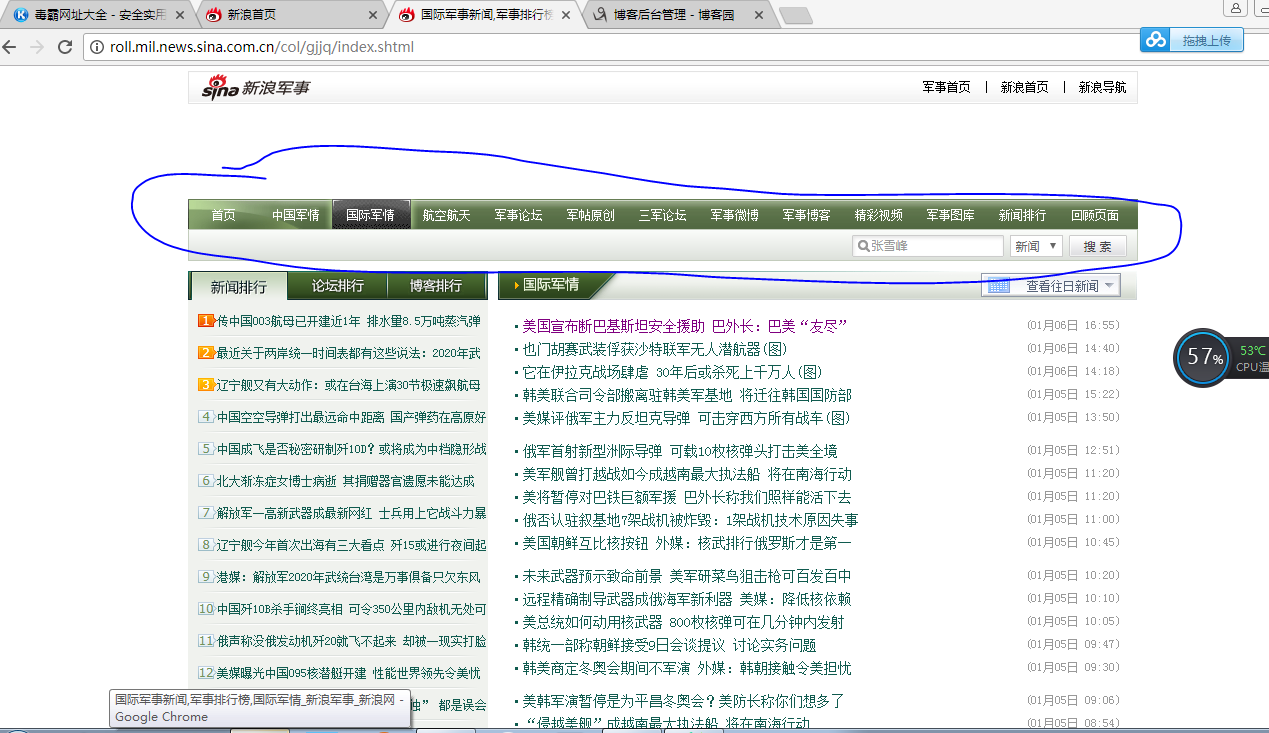
我们打开新浪新闻,看到页面如下,首先去爬取一级 url,图片中蓝色圆圈部分
第二zh张图片,显示需要分页,

源代码:
# coding:utf-8import jsonimport redisimport timeimport requestssession = requests.session()import logging.handlersimport pickleimport sysimport reimport datetimefrom bs4 import BeautifulSoupimport sysreload(sys)sys.setdefaultencoding(‘utf8‘)import datetime# 生成一年的日期def dateRange(start, end, step=1, format="%Y-%m-%d"): strptime, strftime = datetime.datetime.strptime, datetime.datetime.strftime days = (strptime(end, format) - strptime(start, format)).days return [strftime(strptime(start, format) + datetime.timedelta(i), format) for i in xrange(0, days, step)]def spider(): date_list = dateRange("2017-01-01", "2018-01-06")[::-1] print date_list for date in date_list: for page in range(1,5): #组合url url = "http://roll.mil.news.sina.com.cn/col/zgjq/" + str(date)+"_"+ str(page) +".shtml" # 伪装请求头 headers = { "Host":"roll.mil.news.sina.com.cn", "Cache-Control":"max-age=0", "Upgrade-Insecure-Requests":"1", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Accept-Encoding":"gzip, deflate", "Accept-Language":"zh-CN,zh;q=0.8", "If-Modified-Since":"Sat, 06 Jan 2018 09:57:24 GMT", } result = session.get(url=url,headers=headers).content #编码格式是 gb2312,使用BeautifulSoup解决编码格式 soup = BeautifulSoup(result,‘html.parser‘) #找到新闻列表 result_div = soup.find_all(‘div‘,attrs={"class":"fixList"})[0] #去下换行 result_replace = str(result_div).replace(‘\n‘,‘‘).replace(‘\r‘,‘‘).replace(‘\t‘,‘‘) #正则匹配信息 result_list = re.findall(‘<li>(.*?)</li>‘,result_replace) for i in result_list: #匹配出来新闻 url, name,time news_url = re.findall(‘<a href="(.*?)" target=‘,i)[0] news_name = re.findall(‘target="_blank">(.*?)</a>‘,i)[0] news_time = re.findall(‘<span class="time">\((.*?)\)</span>‘,i)[0] print news_url print news_name print news_timespider()Python 爬虫实例(7)—— 爬取 新浪军事新闻
相关内容
- 四则运算python版,四则运算python,a.需求分析1.教师
- python numpy中sum()时出现负值,pythonnumpy,import num
- Python+pandas+matplotlib数据分析与可视化案例,pandasmatplo
- 用Python实现邮件发送Hive明细数据,python邮件发送hive,代
- python flask+psutil 系统监控项目,flaskpsutil,一 安装第三方
- python爬虫笔记之re.compile.findall(),,re.compile
- 如何使用python查看视频的长度,python查看长度,import s
- 毕业设计 python opencv实现车牌识别 界面,pythonopencv,主要
- Jenkins简明入门(二) -- 利用Jenkins完成Python程序的build、
- python-day7--%s与%d的使用,python2中的input及raw_input,,#co
评论关闭