爬虫(六):XPath、lxml模块,
爬虫(六):XPath、lxml模块,
1. XPath
1.1 什么是XPath
XPath(XML Path Language) 是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。
1.2 XPath开发工具
1.2.1 Chrome插件XPath Helper
https://jingyan.baidu.com/article/1e5468f94694ac484861b77d.html
1.2.2 Firefox插件XPath Checker
https://blog.csdn.net/menofgod/article/details/75646443
1.3 Xpath语法
这个就要看我写的selenium基础中的文章了。
https://www.cnblogs.com/liuhui0308/p/11937139.html
2. lxml模块
lxml是一个HTML/XML的解析库,主要功能是如何解析和提取HTML/XML数据。
lxml和正则是一样,也是用C语言实现的,是一款高性能的Python HTML/XML解析器,可以利用之前学习的XPath语法,来快速定位特定元素以及节点信息。
可通过 pip 安装:
pip install lxml -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
2.1 基本使用
我们可以利用它来解析HTML 代码,且在解析 HTML 代码的时候,如果 HTML 代码不规范,他会自动进行补全。
from lxml.html import etree htmlText = ''' <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> ''' # 利用 etree.HTML,将字符串解析为 HTML 文档 html = etree.HTML(htmlText) # 按字符串序列化 HTML 文档 result = etree.tostring(html, encoding='utf-8', pretty_print=True).decode('utf-8') print(result)
2.2 在文件中读取html代码
除了直接使用字符串进行解析,lxml 还支持从文件中读取内容。
html代码:
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="utf-8"> <title></title> </head> <body> <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </body> </html>
然后利用etree.parse()方法来读取文件。
from lxml.html import etree html = etree.parse('./hello.html') result = etree.tostring(html, encoding='utf-8', pretty_print=True).decode('utf-8') print(result)
结果:
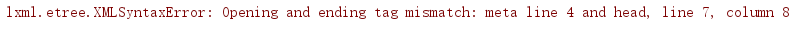
我们看到居然报错了,为什么呢?
之所以使用etree.parse()方法解析 html 内容时,会报lxml.etree.XMLSyntaxError的错,是因为etree.parse()默认使用的是XML的解析器,所以当html内容不规范,比如出现某个标签缺少闭合标签时,就会报这个错误。这时,可使用etree.HTMLParser()创建一个HTML的解析器,然后作为etree.parse()方法的参数即可。
from lxml.html import etree htmlParser = etree.HTMLParser(encoding='utf-8') html = etree.parse('./hello.html', parser=htmlParser) result = etree.tostring(html, encoding='utf-8', pretty_print=True).decode('utf-8') print(result)
2.3 在lxml中使用XPath语法
使用XPath语法,应该使用Element.xpath语法,来执行XPath的选择。
xpath函数返回的永远是一个列表。
我们先来匹配下li标签和a标签
from lxml.html import etree htmlParser = etree.HTMLParser(encoding='utf-8') html = etree.parse('./hello.html', parser=htmlParser) lis = html.xpath('//li') for li in lis: print(etree.tostring(li, encoding='utf-8', pretty_print=True).decode('utf-8'), end='') aList = html.xpath('//a/@href') for a in aList: print(a)

获得li标签下a标签的href属性和内容:
from lxml.html import etree htmlParser = etree.HTMLParser(encoding='utf-8') html = etree.parse('./hello.html', parser=htmlParser) lis = html.xpath('//li') for li in lis: # . 号表示在当前的 li 元素下去匹配 href = li.xpath('.//a/@href')[0] #获取 a 标签的 href 属性 txt = li.xpath('.//a/text()')[0] #获取 a 标签的文本 print(href, txt)

相关内容
- 暂无相关文章
评论关闭