python3??????????????????????????????,,??????????
python3??????????????????????????????,,??????????
?????????
????????????????????????????????????https://www.zhiliti.com.cn/html/luoji/list7_1.html
?????????????????????????????????????????????
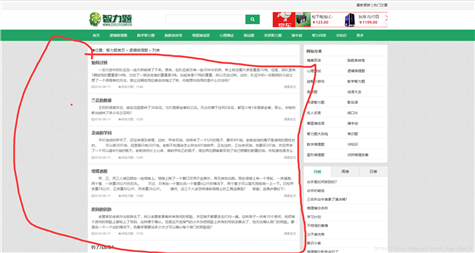
???????????????????????????????????????
?????????????????????
?????????
1????????????????????????????????????
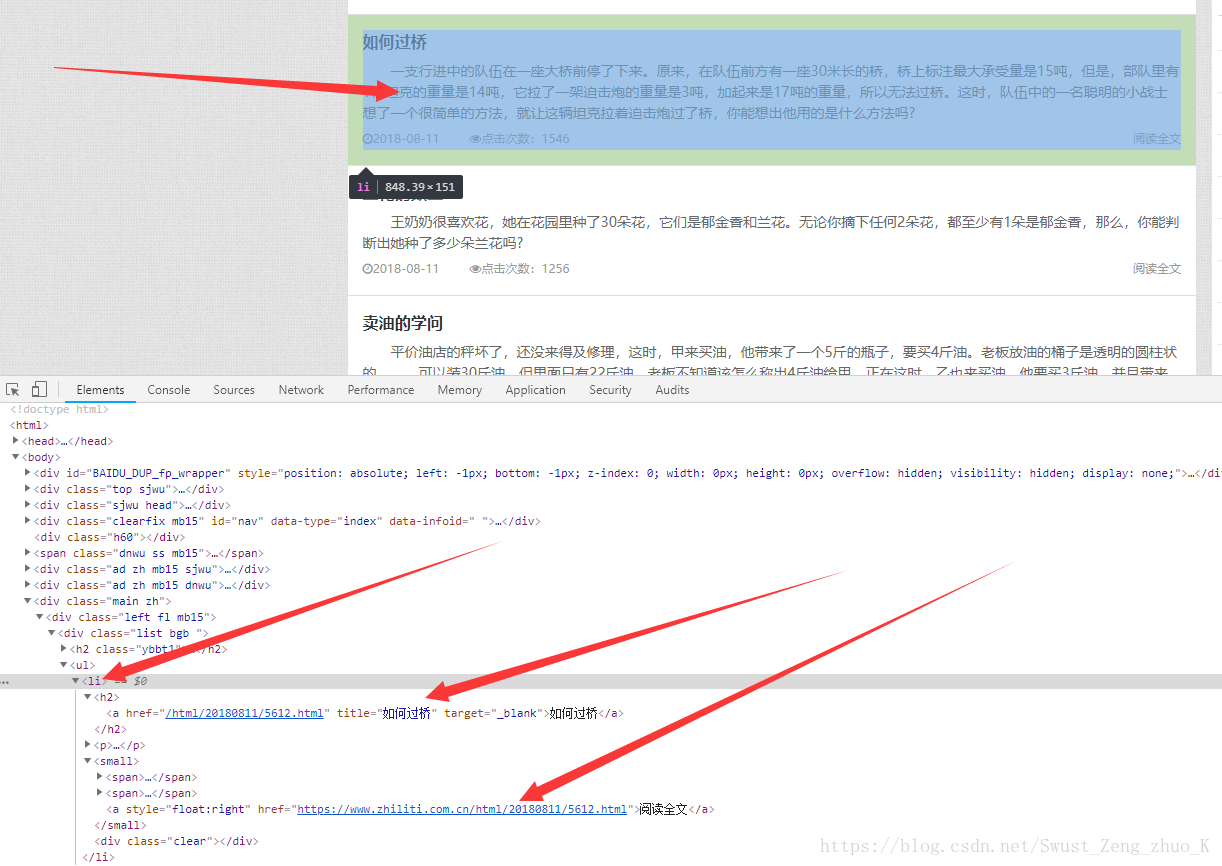
??????????????????????????????
????????????????????????????????????<li>?????????????????????????????????<small>???<a>???href??????
??????????????????????????????????????????????????????
?????????
?????????????????????????????????????????????????????????
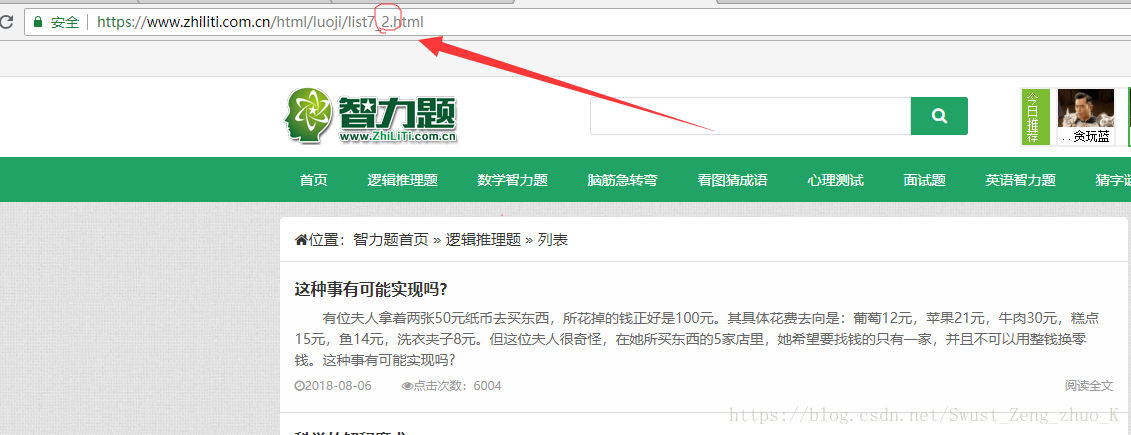
????????????????????????????????????????????????2
????????????????????????
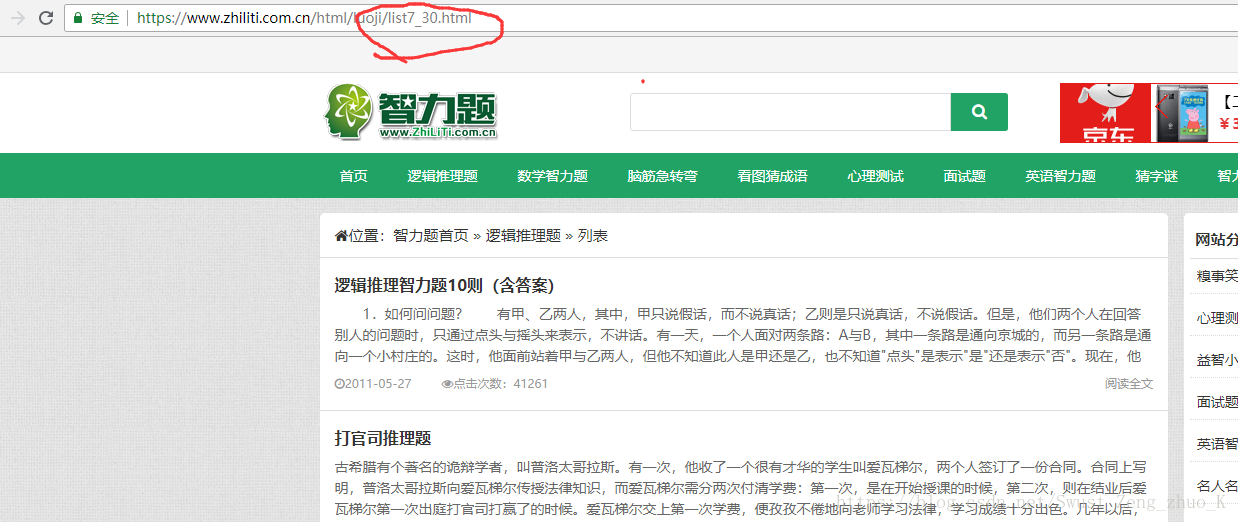
?????????????????????????????????????????????????????????????????????????????????????????????for??????????????????????????????
?????????????????????
??????????????????????????????????????????
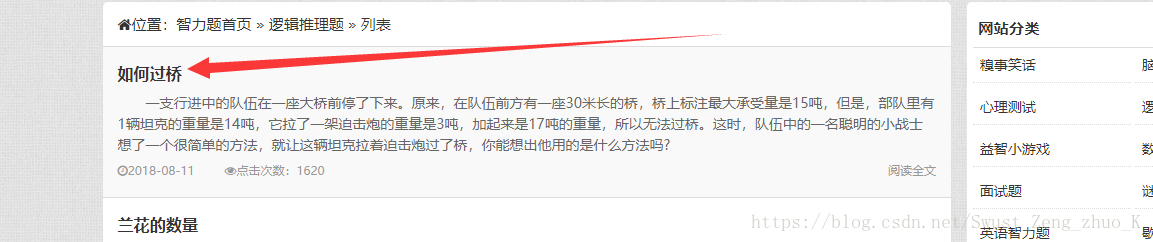
???????????????????????????
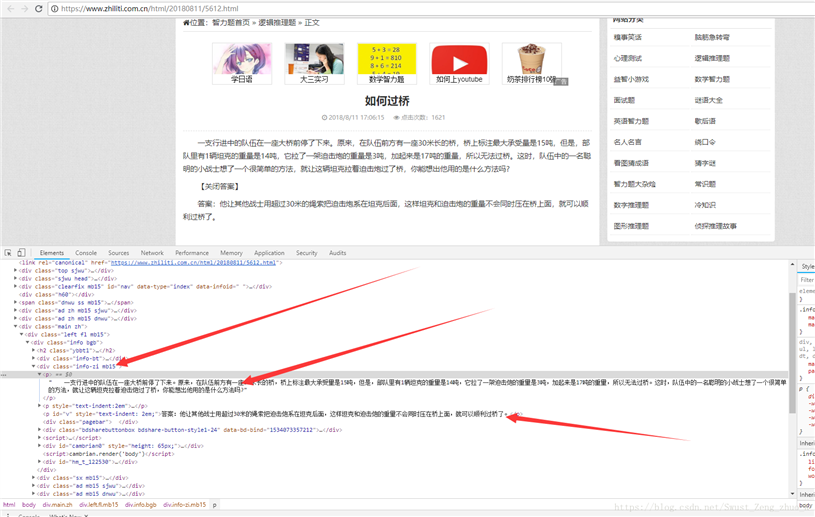
????????????????????????????????????<divclass="info-zi mb15"/>???<p>???????????????????????????????????????????????????????????????
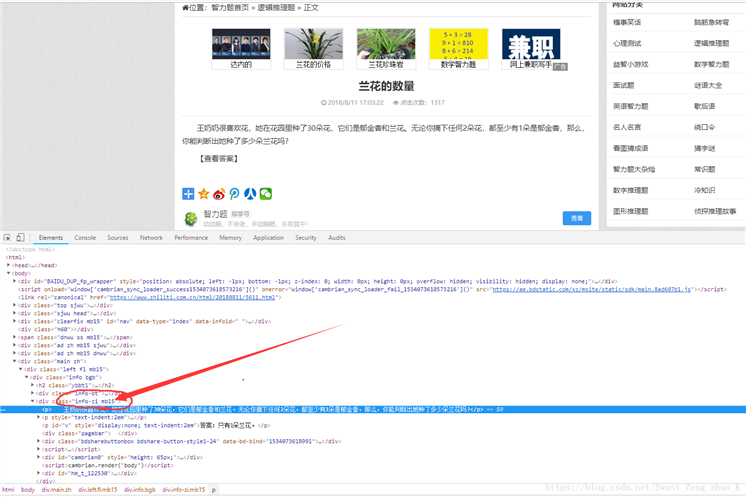
???????????????????????????????????????????????????class???info-zi mb15??????<p>???????????????????????????
????????????????????????????????????
Let???s Go
?????????
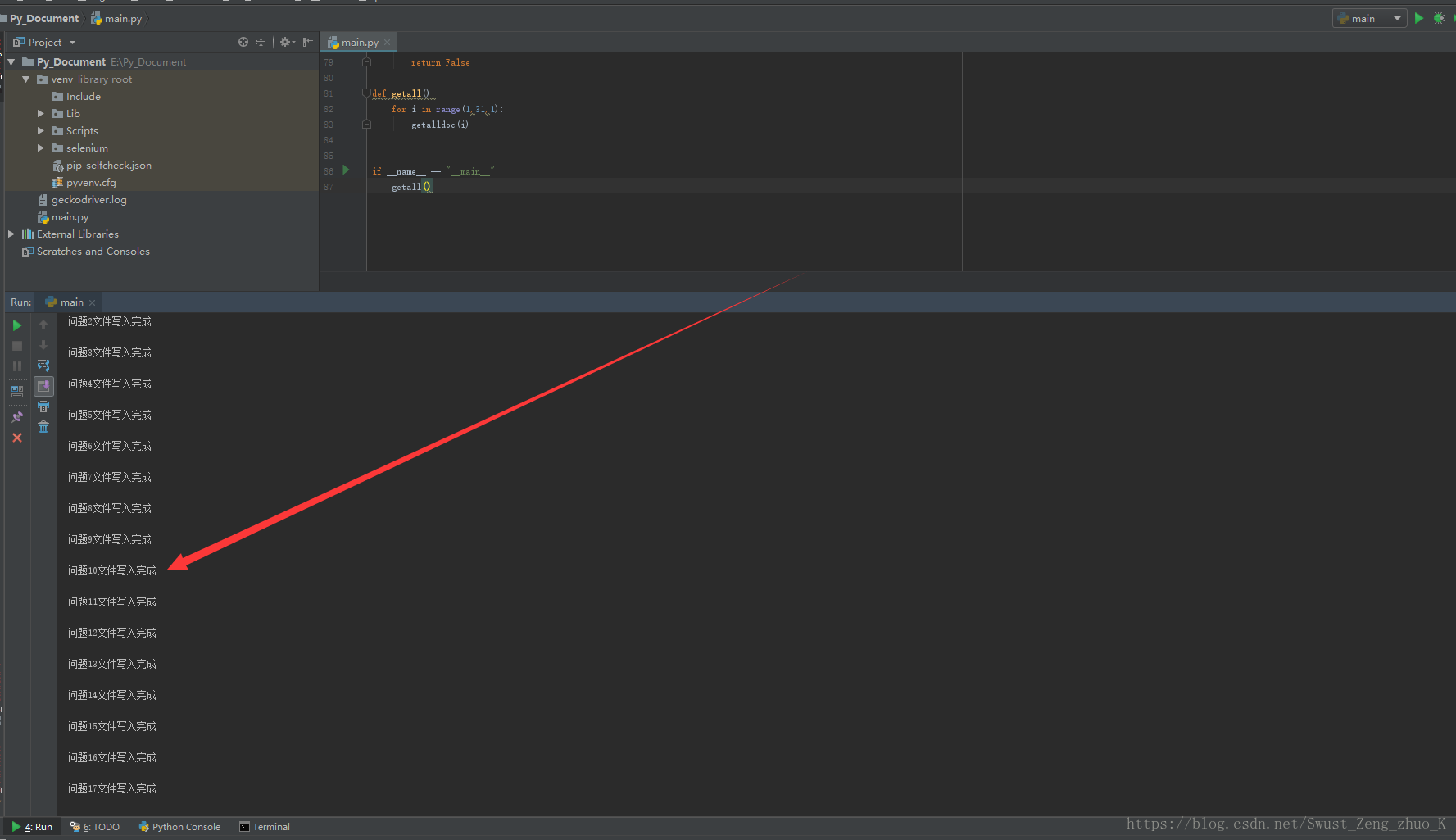
1??????????????????
def getall(): for i in range(1,31,1): getalldoc(i)
i?????????i????????????30?????????i???1?????????30???????????????1???
2???????????????????????????????????????
#???????????????????????????def getalldoc(ii):#??????????????????????????????testurl = "https://www.zhiliti.com.cn/html/luoji/list7_"+str(ii)+".html"#??????request???get????????????res = requests.get(testurl,headers=headers)#??????????????????--------???????????????res.encoding="GB2312"#????????????BeautifulSoup??????soup = BeautifulSoup(res.text,"html.parser")#??????????????????????????????small??????#????????????????????????listans = soup.find_all("small")#??????????????????cnt = 1#???????????????mkdir("E:\\Python???????????????\\??????\\???" + str(ii) + "???\\")for tag in ans: #??????a????????????href?????? string_ans=str(tag.a.get("href")) #?????????????????? #???????????????????????????????????? string_write = geturl(string_ans) #?????????????????? writedoc(string_write,cnt,ii) cnt = cnt+1print("???",ii,"???????????????")
????????????????????????url???????????????request???????????????????????????????????????BeautifulSoup???html?????????????????????????????????<small>?????????????????????list??????????????????list??????????????????<small>????????????<a>?????????href????????????????????????????????????string_ans???
?????????????????????url??????????????????geturl???????????????????????????????????????????????????????????????????????????????????????writedoc???????????????
3????????????????????????url????????????????????????
#??????????????????url?????????????????????def geturl(url): #?????????????????? r = requests.get(url, headers=headers) #????????? r.encoding = "GB2312" soup = BeautifulSoup(r.text, "html.parser") #??????????????? info-zi mb15 ????????????p?????? ans = soup.find_all(["p", ".info-zi mb15"]) #???????????????????????????????????????????????? mlist = "" for tag in ans: #??????p????????????string??????????????????????????????????????? mlist=mlist+str(tag.string) #????????????????????? return mlist
??????????????????????????????BeautifulSoup??????????????????class=info-zi mb15???????????????<p>??????????????????????????????list?????????list????????????item???string????????????????????????????????????
4?????????????????????????????????
#?????????def writedoc(ss, i,ii): #???????????? #?????????utf-8 with open("E:\\Python???????????????\\??????\\???" + str(ii) + "???\\"+"??????" + str(i) + ".txt", ???w???, encoding=???utf-8???) as f: #????????? f.write(ss) print("??????" + str(i) + "??????????????????" + "\n")5?????????????????????
def mkdir(path): # ?????????????????? path = path.strip() # ???????????? \ ?????? path = path.rstrip("\\") # ???????????????????????? # ?????? True # ????????? False isExists = os.path.exists(path) # ???????????? if not isExists: # ?????????????????????????????? # ???????????????????????? os.makedirs(path) return True else: # ????????????????????????????????????????????????????????? return False????????????python??????
import requestsfrom bs4 import BeautifulSoupimport os # ?????????????????????????????????????????????????????????User-Agent??????????????????????????????????????????????????????Requests???????????????UA??????????????????????????????headers = {???user-agent???: ???Mozilla/5.0???} #?????????def writedoc(ss, i,ii): #???????????? #?????????utf-8 with open("E:\\Python???????????????\\??????\\???" + str(ii) + "???\\"+"??????" + str(i) + ".txt", ???w???, encoding=???utf-8???) as f: #????????? f.write(ss) print("??????" + str(i) + "??????????????????" + "\n") #??????????????????url?????????????????????def geturl(url): #?????????????????? r = requests.get(url, headers=headers) #????????? r.encoding = "GB2312" soup = BeautifulSoup(r.text, "html.parser") #??????????????? info-zi mb15 ????????????p?????? ans = soup.find_all(["p", ".info-zi mb15"]) #???????????????????????????????????????????????? mlist = "" for tag in ans: #??????p????????????string??????????????????????????????????????? mlist=mlist+str(tag.string) #????????????????????? return mlist #???????????????????????????def getalldoc(ii): #?????????????????????????????? testurl = "https://www.zhiliti.com.cn/html/luoji/list7_"+str(ii)+".html" #??????request???get???????????? res = requests.get(testurl,headers=headers) #??????????????????--------??????????????? res.encoding="GB2312" #????????????BeautifulSoup?????? soup = BeautifulSoup(res.text,"html.parser") #??????????????????????????????small?????? #????????????????????????list ans = soup.find_all("small") #?????????????????? cnt = 1 #??????????????? mkdir("E:\\Python???????????????\\??????\\???" + str(ii) + "???\\") for tag in ans: #??????a????????????href?????? string_ans=str(tag.a.get("href")) #?????????????????? #???????????????????????????????????? string_write = geturl(string_ans) #?????????????????? writedoc(string_write,cnt,ii) cnt = cnt+1 print("???",ii,"???????????????") def mkdir(path): # ?????????????????? path = path.strip() # ???????????? \ ?????? path = path.rstrip("\\") # ???????????????????????? # ?????? True # ????????? False isExists = os.path.exists(path) # ???????????? if not isExists: # ?????????????????????????????? # ???????????????????????? os.makedirs(path) return True else: # ????????????????????????????????????????????????????????? return False def getall(): for i in range(1,31,1): getalldoc(i) if __name__ == "__main__": getall()??????????????????
????????????
????????????????????????utf-8????????????????????????????????????????????????GB2312????????????????????????????????????????????????python??????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????
# ?????????????????????????????????????????????????????????User-Agent??????????????????????????????????????????????????????Requests???????????????UA??????????????????????????????headers = {???user-agent???: ???Mozilla/5.0???}python3??????????????????????????????
?????????
???????????????https://www.cnblogs.com/Anderson-An/p/10226854.html
相关内容
- ???????????????????????? -Python???Python split()??????,python字符串
- ???Python????????????Linux????????????Windows???????,,?????????P
- python-????????????,python有什么用,?????????1
- Python ?????????????????????,python有什么用,??????????
- python????????????__reduce__()?????????,pythonreduce函数,????????
- python基础01,python基础教程,第一章 Pytho
- python对话框,并选择yes/no,python弹出对话框,python 自带的
- LRU算法Python实现,遗传算法python代码,LRU 算法描述LR
- python基础_代码控制,,1.代码块 : 以冒
- PTA的Python练习题(七),,不知不觉一个星期过去
评论关闭