python解析PDF文档,,1.安装pip in
python解析PDF文档,,1.安装pip in
1.安装
pip install pdfminer3k
2. python读取PDF文档代码分析
PDF格式不是规范格式. 尽管它被叫做"PDF文档", 但并不像word或者html文档。PDF的表现更像一张图片。PDF更像是在一张纸的各个准确的位置上把内容都摆放出来。大部分情况下,没有逻辑结构,比如句子或段落,并且不能自适应页面大小的调整。PDFMiner尝试通过猜测它们的布局来重建它们的结构,但是不保证一定能工作。我知道这样很难看,但是,PDF确实不够规范。
下面这个图片是使用流程说明,我们将其分解来看
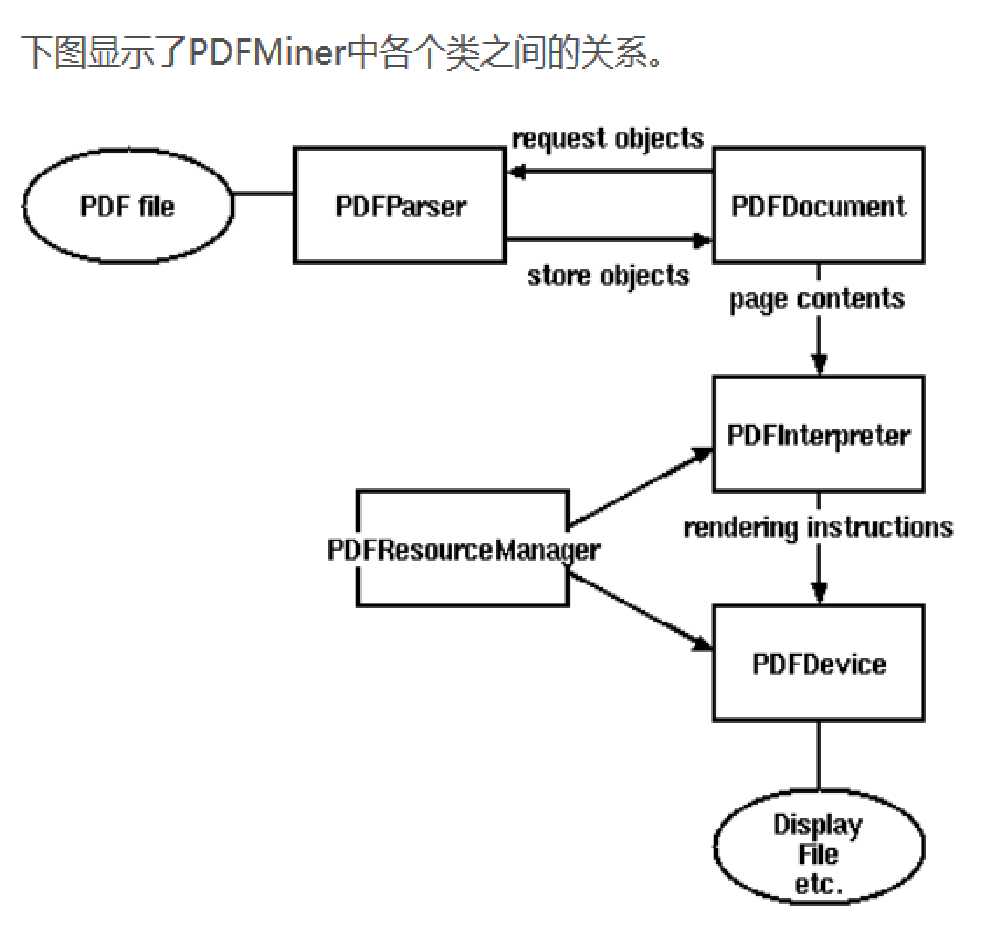
由于PDF文件有如此大和复杂的结构,完整解析PDF文件很费时费力。大多数PDF工作中,很多模块是不需要加进来的。因此 PDFMiner采用了一个懒惰分析的策略,就是只分析所需要的部分。解析时候,至少需要2个核心类,PDFParser 和 PDFDocument。这两个模块配合其他模块来使用。 PDFParser 从文件中获取数据 PDFDocument 存储文档数据结构到内存中 PDFPageInterpreter 解析page内容 PDFDevice 把解析到的内容转化为你需要的东西 PDFResourceManager存储共享资源,例如字体或图片
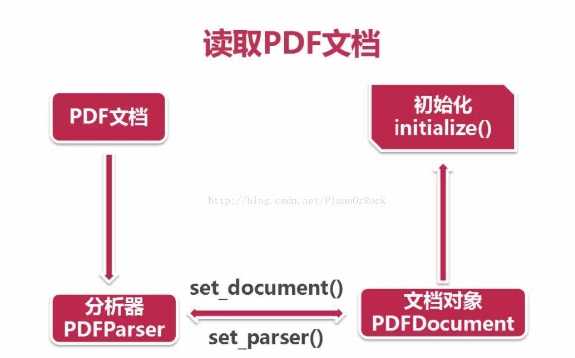
首先使用open方法或者urlopen打开本场文档或者网络文档(一般会这么做因为考虑到文档太大,对网络服务器负担也很大)生成文档对象,以下的方法之中的网络链接已经存在了。
# 获取文档对象 pdf0 = open(‘sampleFORtest.pdf‘,‘rb‘) # pdf1 = urlopen(‘http://www.tencent.com/20160321.pdf‘)
然后创建文档解析器和PDF文档对象并将他们相互关联
# 创建一个与文档关联的解析器 parser = PDFParser(pdf0) # 创建一个PDF文档对象 doc = PDFDocument() # 连接两者 parser.set_document(doc) doc.set_parser(parser)
对PDF文档对象进行初始化,如果文档本身进行了加密,则需要在加入password参数
# 文档初始化 doc.initialize(‘‘)
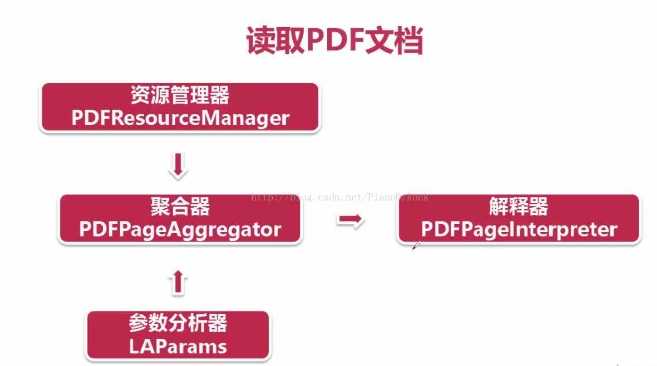
先创建PDF资源管理器和参数分析器
# 创建PDF资源管理器 resources = PDFResourceManager() # 创建参数分析器 laparam = LAParams()
再创建一个聚合器,并接收PDF资源管理器参数分析器作为参数
# 创建一个聚合器,并接收资源管理器,参数分析器作为参数 device = PDFPageAggregator(resources,laparams=laparam)
最后创建一个页面解释器,将PDF资源管理器和聚合器作为参数
# 创建一个页面解释器 interpreter = PDFPageInterpreter(resources,device)
这样页面解释器就具有对PDF文档进行编码,解释成Python能够识别的格式
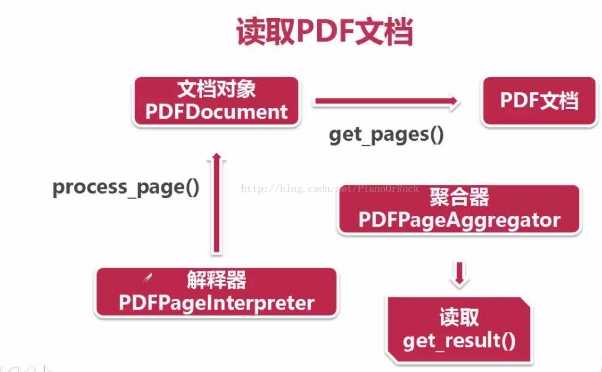
最后呢,使用PDF文档对象的get_pages()方法从PDF文档中读取出页面集合,接着使用页面解释器 对页面集合逐一读取,再调用聚合器的get_result()方法将页面逐一放置到layout之中,最后商用layout的get_text()方法获取每一页的text。
for page in doc.get_pages(): # 使用页面解释器读取页面 interpreter.process_page(page) # 使用聚合器读取页面页面内容 layout = device.get_result() for out in layout: if hasattr(out,‘get_text‘): # 因为文档中不只有text文本 print(out.get_text())
需要注意的是在PDF文档中不只有text还可能有图片等等,为了确保不出错先判断对象是否具有get_text()方法
3.结果分析
如果PDF文件中仅仅是文字,那么会完全解析出来,读出文字,存在一个TXT文档里面,但是要是出现了图片等东西,则不会读取到东西。
本文做了三个实验,分别是PDF文档里面只存在文字,只存在图片,存在文字和图片。
结果显示:
| 只存在文字的PDF | 此程序会全部读取出文字 |
| 只存在图片的PDF | 此程序不会读取出任何东西 |
| 存在图片和文字 | 此程序只会读出文字,不会识别图片 |
所以说,图片的文字识别,不能只单纯的使用pdfminer这个库,还需要图片处理等相关技术。
4.PDF解析模块
布局分析把pdf文档中每一页返回为一个 LTPage 对象. 该对象包含该页面中的子对象,格式化为树形结构。
下图显示了这些对象之间的关系。
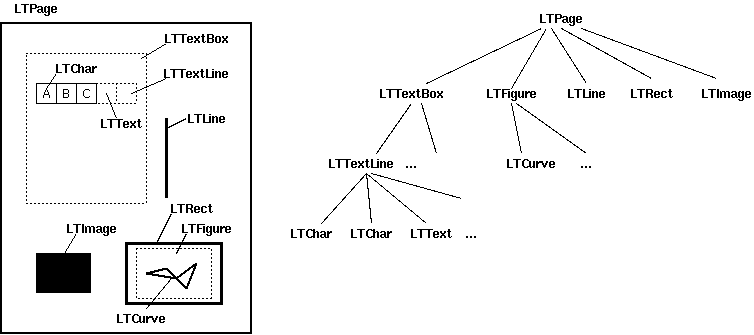
LTPage
代表一个完整的页面。可以包含子对象,例如LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine.
LTTextBox
它包含 LTTextLine 对象的列表
代表一组被包含在矩形区域中的文本
需要注意的是,该box是根据几何学分析得到的,并不一定准确地表现为该文本的逻辑范围
get_text()方法可以返回文本内容
LTTextLine
包含一个LTChar对象的列表,表现为单行文本
字符表现为一行或一列,取决于文本书写方式
get_text()方法返回文本内容
LTChar / LTAnno
代表一个在文本中的真实的字母,作为一个unicode字符串
LTChar 对象有真实的分隔符
LTAnno 对象没有,是虚拟分隔符,按照两个字符之间的关系,布局分析器插入虚拟分隔符
LTFigure
代表一个被PDF Form对象使用的区域
pdf form适用于目前的图表(present figures)或者页面中植入的另一个pdf文档图片。LTFigure对象可以递归
LTImage
代表一个图形对象。可以是JPEG或者其他格式,但PDFMiner目前没有花太多精力在图形对象上。
LTLine
代表一根直线。用来分割文本或图表(figures)。
LTRect
代表一个矩形。
用来框住别的图片或者图表。
LTCurve
代表一个贝塞尔曲线。
5.实例
################### 读取PDF文档 ############################ #pip install pdfminer3k from pdfminer.pdfparser import PDFDocument,PDFParser,PDFPagefrom pdfminer.pdfinterp import PDFResourceManager,PDFPageInterpreterfrom pdfminer.converter import PDFPageAggregator,PDFConverterfrom pdfminer.layout import LTLayoutContainer,LAParamsfrom pdfminer.pdfinterp import PDFTextExtractionNotAllowed# PDFParser #PDF文档分析器:从一个文件中获取数据# PDFDocument #PDF文档对象:保存获取的数据,和PDFParser是相互关联的## PDFPageAggregator #PDF聚合器,读取获取的文档对象# PDFResourceManager #PDF资源管理器:用于存储共享资源,如字体或图像# LAParams #pdf参数分析器:分析PDF文件参数# PDFPageInterpreter #PDF解释器,处理页面内容变成Python可以解析## 思路:构建文档对象---》解析文档对象---》提取所需内容import osdef pdf_to_word(floder,password): files=os.listdir(floder) pdffiles=[f for f in files if f.endswith(‘.pdf‘)] for pdffile in pdffiles: # pdfPath=os.path.join(floder,pdffile) wdPath=pdfPath.split(‘.‘)[0] worldPath=wdPath + ‘.txt‘ # 获取文档对象 fn=open(pdfPath,‘rb‘) # 创建一个PDF文档解释器 parser=PDFParser(fn) fn.close() # PDF文档的对象 docx=PDFDocument() # 连接解释器和文档对象 parser.set_document(docx) docx.set_parser(parser) # 初始化文档 docx.initialize() #检测文档是否提供txt转换,不提供就忽略 if not docx.is_extractable: raise PDFTextExtractionNotAllowed else: # 创建PDF资源管理器 resource=PDFResourceManager() # 参数分析器 laparams=LAParams() # 创建一个聚合器 device=PDFPageAggregator(resource,laparams=laparams) # 创建PDF页面解释器 interpreter=PDFPageInterpreter(resource,device) f = open(worldPath, ‘w‘,encoding=‘utf-8‘) print(‘正在写入。。。。‘) # 使用文档对象得到页面的集合 for page in docx.get_pages(): # 使用页面解释器来读取 interpreter.process_page(page=page) # 使用聚合器来获取页面内容 ,接受该页面的LTPage对象 layout=device.get_result() # 这里layout是一个LTPage对象 里面存放着这个page解析出的各种对象 # 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 # 想要获取文本就获得对象的text属性 for out in layout: # if (isinstance(out,LTLayoutContainer)): # print(out.get_text()) # 因为文档中不只有text文本 if hasattr(out, "get_text"): f.write(out.get_text()) f.close()# 是否打印日志import logginglogging.Logger.propagate = Falselogging.getLogger().setLevel(logging.ERROR)pdf_to_word(r‘C:\Users\Administrator\Desktop\picture‘,‘ll‘)
python解析PDF文档
评论关闭