看完python这段爬虫代码,java流泪了c#沉默了,,哈哈,其实很简单,寥
看完python这段爬虫代码,java流泪了c#沉默了,,哈哈,其实很简单,寥
哈哈,其实很简单,寥寥几行代码网页爬一部小说,不卖关子,立刻开始。
首先安装所需的包,requests,BeautifulSoup4
控制台执行
pip installrequests
pip installBeautifulSoup4
如果不能正确安装,请检查你的环境变量,至于环境变量配置,在这里不再赘述,相关文章有很多。
两个包的安装命令都结束后,输入pip list
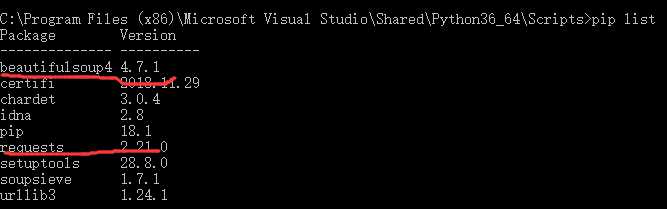
可以看到,两个包都成功安装了。
好的,我们立刻开始编写代码。
我们的目标是抓取这个链接下所有小说的章节https://book.qidian.com/info/1013646681#Catalog
我们访问页面,用chrome调试工具查看元素,查看各章节的html属性。我们发现所有章节父元素是<ul class="cf">这个元素,章节的链接以及标题,在子<li>下的<a>标签内。
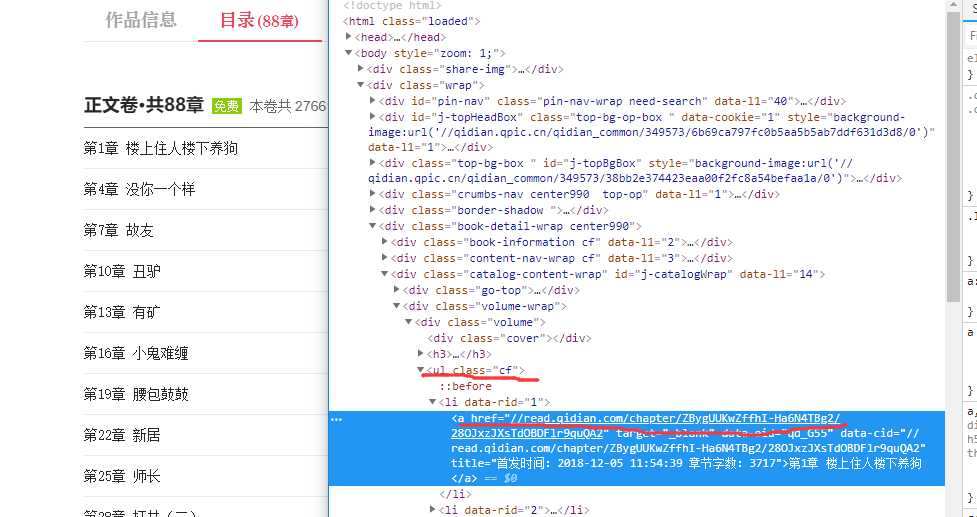
那我们第一步要做的事,就是要提取所有章节的链接。
‘用于进行网络请求‘import requestschapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")print(chapter.text)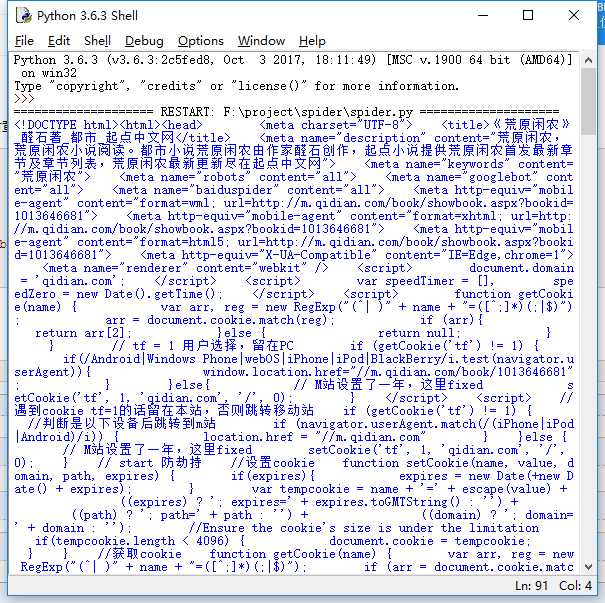
页面顺利的请求到了,接下来我们从页面中抓取相应的元素
‘用于进行网络请求‘import requests‘用于解析html‘from bs4 import BeautifulSoupchapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")ul_bs = BeautifulSoup(chapter.text)‘提取class为cf的ul标签‘ul = ul_bs.find_all("ul",class_="cf")print(ul)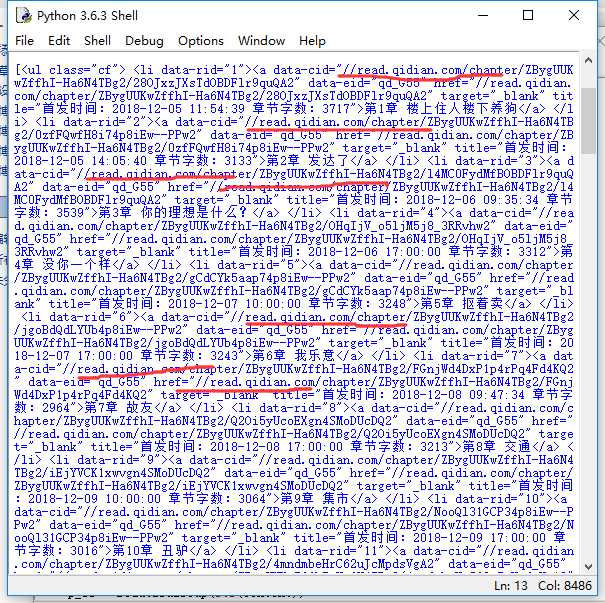
ul也顺利抓取到了,接下来我们遍历<ul>下的<a>标签取得所有章节的章节名与链接
‘用于进行网络请求‘import requests‘用于解析html‘from bs4 import BeautifulSoupchapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")ul_bs = BeautifulSoup(chapter.text)‘提取class为cf的ul标签‘ul = ul_bs.find_all("ul",class_="cf")ul_bs = BeautifulSoup(str(ul[0]))‘找到<ul>下的<a>标签‘a_bs = ul_bs.find_all("a")‘遍历<a>的href属性跟text‘for a in a_bs: href = a.get("href") text = a.get_text() print(href) print(text)
ok,所有的章节链接搞定,我们去看想想章节详情页面长什么样,然后我们具体制定详情页面的爬取计划。
打开一个章节,用chrome调试工具审查一下。文章标题保存在<h3 class="j_chapterName">中,正文保存在<div class="read-content j_readContent">中。
我们需要从这两个标签中提取内容。
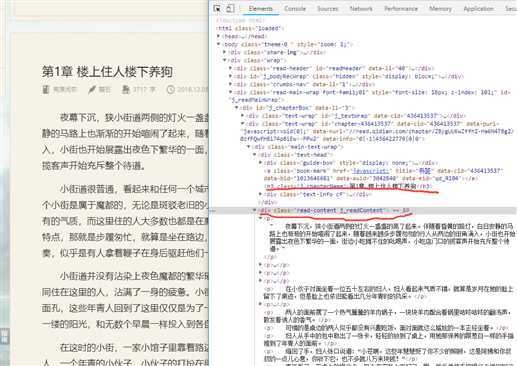
‘用于进行网络请求‘import requests‘用于解析html‘from bs4 import BeautifulSoupchapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")ul_bs = BeautifulSoup(chapter.text)‘提取class为cf的ul标签‘ul = ul_bs.find_all("ul",class_="cf")ul_bs = BeautifulSoup(str(ul[0]))‘找到<ul>下的<a>标签‘a_bs = ul_bs.find_all("a")detail = requests.get("https:"+a_bs[0].get("href"))text_bs = BeautifulSoup(detail.text)text = text_bs.find_all("div",class_ = "read-content j_readContent")print(text)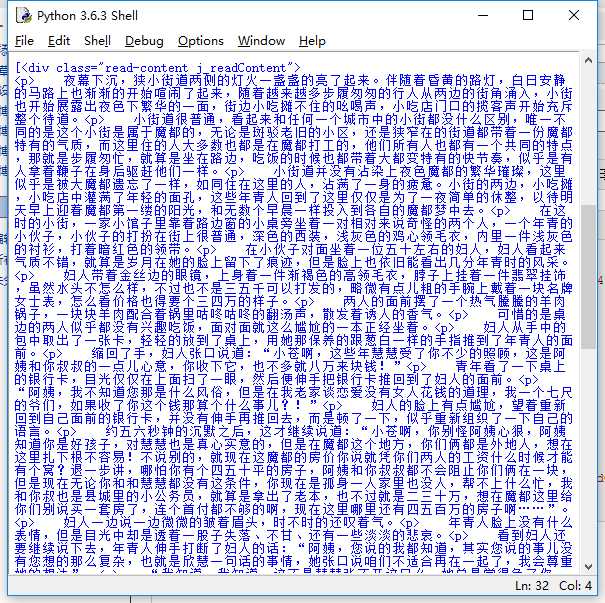
正文页很顺利就爬取到了,以上代码仅是用第一篇文章做示范,通过调试文章已经可以爬取成功,所有下一步我们只要把所有链接遍历逐个提取就好了
‘用于进行网络请求‘import requests‘用于解析html‘from bs4 import BeautifulSoupchapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")ul_bs = BeautifulSoup(chapter.text)‘提取class为cf的ul标签‘ul = ul_bs.find_all("ul",class_="cf")ul_bs = BeautifulSoup(str(ul[0]))‘找到<ul>下的<a>标签‘a_bs = ul_bs.find_all("a")‘遍历所有<href>进行提取‘for a in a_bs: detail = requests.get("https:"+a.get("href")) d_bs = BeautifulSoup(detail.text) ‘正文‘ content = d_bs.find_all("div",class_ = "read-content j_readContent") ‘标题‘ name = d_bs.find_all("h3",class_="j_chapterName")[0].get_text() 在上图中我们看到正文中的每一个<p>标签为一个段落,提取的文章包含很多<p>标签这也是我们不希望的,接下来去除p标签。
但是去除<p>标签后文章就没有段落格式了呀,这样的阅读体验很不爽的,我们只要在每个段落的结尾加一个换行符就好了
‘用于进行网络请求‘import requests‘用于解析html‘from bs4 import BeautifulSoupchapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")ul_bs = BeautifulSoup(chapter.text)‘提取class为cf的ul标签‘ul = ul_bs.find_all("ul",class_="cf")ul_bs = BeautifulSoup(str(ul[0]))‘找到<ul>下的<a>标签‘a_bs = ul_bs.find_all("a")‘遍历所有<href>进行提取‘for a in a_bs: detail = requests.get("https:"+a.get("href")) d_bs = BeautifulSoup(detail.text) ‘正文‘ content = d_bs.find_all("div",class_ = "read-content j_readContent") ‘标题‘ name = d_bs.find_all("h3",class_="j_chapterName")[0].get_text() txt = "" p_bs = BeautifulSoup(str(content)) ‘提取每个<p>标签的内容‘ for p in p_bs.find_all("p"): txt = txt + p.get_text()+"\r\n"去掉<p>标签了,所有的工作都做完了,我们只要把文章保存成一个txt就可以了,txt的文件名以章节来命名。
‘用于进行网络请求‘import requests‘用于解析html‘from bs4 import BeautifulSoupdef create_txt(path,txt): fd = None try: fd = open(path,‘w+‘,encoding=‘utf-8‘) fd.write(txt) except: print("error") finally: if (fd !=None): fd.close()chapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")ul_bs = BeautifulSoup(chapter.text)‘提取class为cf的ul标签‘ul = ul_bs.find_all("ul",class_="cf")ul_bs = BeautifulSoup(str(ul[0]))‘找到<ul>下的<a>标签‘a_bs = ul_bs.find_all("a")‘遍历所有<href>进行提取‘for a in a_bs: detail = requests.get("https:"+a.get("href")) d_bs = BeautifulSoup(detail.text) ‘正文‘ content = d_bs.find_all("div",class_ = "read-content j_readContent") ‘标题‘ name = d_bs.find_all("h3",class_="j_chapterName")[0].get_text() path = ‘F:\\test\\‘ path = path + name+".txt" txt = "" p_bs = BeautifulSoup(str(content)) ‘提取每个<p>标签的内容‘ for p in p_bs.find_all("p"): txt = txt + p.get_text()+"\r\n" create_txt(path,txt) print(path+"保存成功")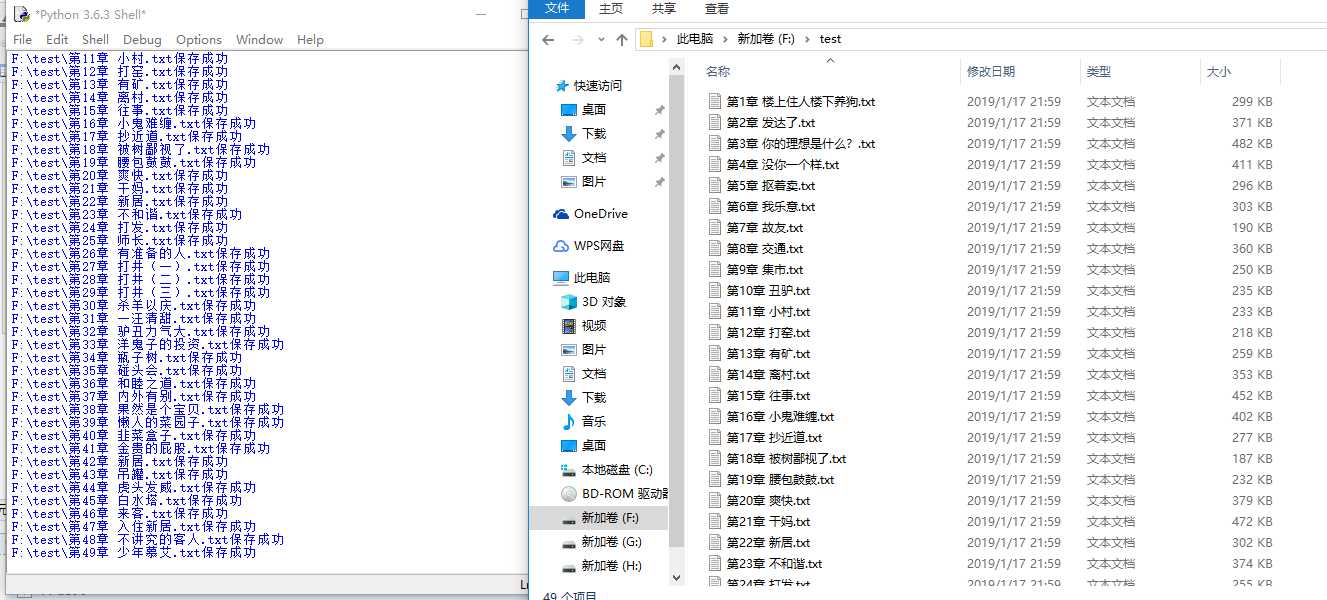
文章成功爬取,文件成功保存,搞定。就这么简单的几行代码搞定。
看完python这段爬虫代码,java流泪了c#沉默了
评论关闭