Python 入门学习第二部分:,,一、初识模块 Pyh
Python 入门学习第二部分:,,一、初识模块 Pyh
一、初识模块
Pyhon具有非常丰富和强大的标准库与第三方库,几乎能实现你想要的任何功能。python中的模块分为两种类型,一种是标准库,不需要了另外安装,直接在写程序的时候通过import指令导入就行;还有一种是第三方库,必须要下载安装到对应的文件目录下,才能使用。具体的呢下面最下简单的介绍。
1、两个例子
1)Sysm模块
当运行如下代码的时候,sys的path功能输出的结果是python 的全局环境变量,即python调用该模块时进行索引的路径。argv的功能则是打印模块的相对位置,同时可以用来调用参数。
1 import sys2 print(sys.path)#打印环境变量3 print(sys.argv)
2)os模块
1 import os #调用模块2 cmd_res1=os.system("dir") #system线路是让系统执行一条命令,但是这个命令只能执行不能储存3 cmd_res1=os.popen("dir").read() #popen线路就是可以储存的,但是这里在执行了之后实际上是相当于暂时放在内存的一个地方, #需要通过read()来调用出来,否则是一堆机器码4 print(cmd_res1)5 os.mkdir("new_dir")#这个用于创建一个新的目录,mkdirs则是用来创建一个新的多级目录。2、关于自己创建模块
最好不要用中文,另外要么放在和import的文件同一个目录下,要么放在前面提到过的site-packages里边,要么修改环境变量。还有在python3中有个问题:我们给Pyhon file命名的时候一定不要和模块的名字重到,否则Python会优先选择当前目录下的.py文件。二、关于pyc的一点小知识 我们在之前的第一部分当中已经提到过,编程语言分为编译型语言和解释型语言。 编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言,java等。 解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby,python等。 然后我们又提到,两种类型的语言在运行速度、内存要求等方面具有一些不同的差异,同时呢随着技术慢慢慢慢地发展,两者之间的界限呢也变得越来越模糊。好了下面说回到python。 当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。 说编译可能不太确切,准确地说应该是预编译。当Python程序开始运行时,预编译的结果被储存在了内存中的PyCodeObject文件当中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。 当Python程序第二次运行时,程序首先会在硬盘当中寻找pyc文件,如果能找到则直接载入,否则重复上面的过程。 那么如果当源代码发生了更改之后该怎么办?Python在执行文件之前会预先搜索pyc文件,在找到之后,它会通过算法(C)对pyc文件的保存时间和源代码的更改时间进行比较,然后由此决定是否运行pyc文件。 所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。.pyc实际上是预编译后的自解码文件(15%的半成品)。三、数据类型简单介绍常用的几种数据类型。1、数字 1)int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1, 即-21474836482147483647~21474836482147483647 在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1, 即-9223372036854775808~9223372036854775807 另外,在Python3当中不存在整型和和长整型之分,只有整型。 2)float(浮点型) 浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。浮点的表示形式是小数,但浮点≠小数3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。 3)complex(复数) 复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。实际上就是所谓的可以用来表示三维空间当中的向量的一系列数。2、布尔值 真或假 1 或 0 对--->true 1 不对-->false 03、字符串字符串的常用功能包括移除空白、分割、长度、索引、切片等,在后边的字符串操作部分中会详细介绍。四、数据运算 1、算术运算 常用的加减乘除,即“+”,“-”,“*”,“/”自不必多说。 “%”,取模返回x的余数,可以应用于相邻两个单位不同的循环情况; “**”,幂 x**y即表示x的y次幂; “//”,取整除,返回商的整数部分 2、比较运算 >、<、<=、>=不多说。 “!=”,不等于 “<>”,同上,不过不常用 “==”等于3、赋值运算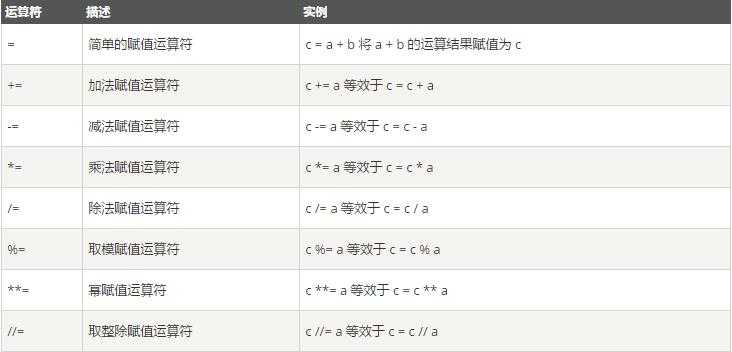 4、逻辑运算Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20
4、逻辑运算Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20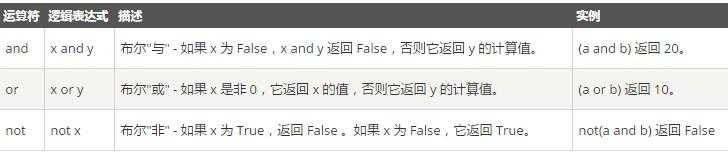 5、身份运算
5、身份运算 例子如下:
例子如下:1 a=[1,2,3,4]2 print(type(a))3 type(a) is list
这里最后的输出结果应该为“True”,即表明a确实是一个列表。
6、二进制位运算
计算机中能表示的最小单位,是一个二进制位;计算机中能存储的最小单位,是一个二进制位。(bit)8bit =1byte (字节)1024byte=1kbyte1024kbyte=1mbyte1024mb=1gb1024gb=1T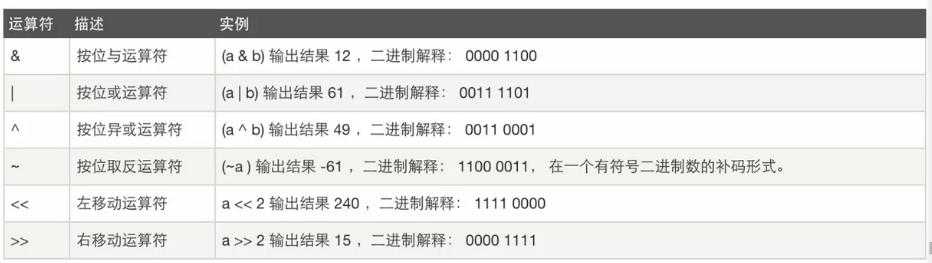 7、关于各个运算的优先级
7、关于各个运算的优先级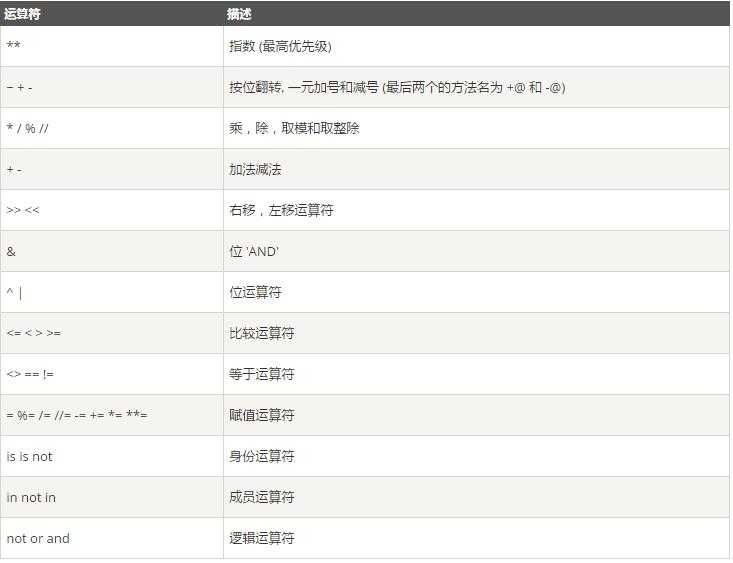 五、入门知识拾遗 1、三元运算
五、入门知识拾遗 1、三元运算1 a,b,c=3,6,72 d=a if a<b else c3 print(d)4 #输出结果5 3
2、进制
二进制,01八进制,01234567十进制,0123456789十六进制,0123456789ABCDEF二进制到十六进制的转化:
http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
十六进制的表示法:后缀为H——如BH表示十六进制数11前缀为0X——0x23表示16进制的23在进行从二进制到十六进制的转换过程中,在向左(或向右)取四位时,取到最高位(最低位)如果无法凑足四位,就可以在小数点的最左边(或最右边)补0,进行换算。3、bytes的数据类型在Python3当中,文本的unicode都有字符串数据(str)来表示;二进制的数据类型,诸如视频、音频等则都由bytes类型来表示。另外在Python3当中,所有的数据传输都采用二进制来进行。程序中string和bytes的转换示意图如下: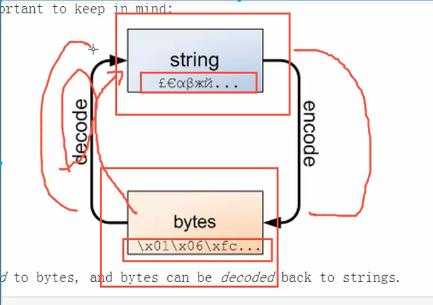
msg="你大爷"print(msg.encode("utf-8"))print(msg.encode("utf-8").decode("utf-8"))比如上面的代码。
在encode当中,一定要写明原先是哪一种数据类型,如果不写的话,默认是按照utf-8来进行。
六、列表的使用 1、列表的基本格式1 names=["a","b","c","d","e","b"]
2、对于列表的对象查询
1 print(names[3])#调用列表中的对象,从左到右依次为0,1,2,3...2 print(names[1:3])#切片,从左边开始的话,顾头不顾尾3 print(names[-1])#切片,调用最后一位,从右开始数4 print(names[-3:-1])#切片,按照从最后开始数的方法,但是切片还是从左往右并且顾头不顾尾的。5 print(names[-3:])#如果要取最后一位,那么:后边应该不写东西6 print(names[:2])#同理,如果说是从第一个开始,前面是0,也可以不写。7 print(names[0:-1:2])#跳着切片,最后一个2为步长
3、对于列表的一些拓展功能的使用
1)增加元素
1 names.append("F")#添加元素到后边2 names.insert(1,"F")#添加元素到指定位置,想到那个位置就写那个位置的下标2)更改元素
1 names[1]="B" #更改对应位置上的元素
3)删除元素
1 names.remove("c")#这种方式直接写要删除对象的内容2 del names[2]#这个就是指定位置下标来删3 names.pop(2) #pop和del起的作用其实基本是一样的,不过要是默认不写下标的话就会删除最后一个对象。4)查询元素
1 print (names.index("c"))#对于已知内容的对象,打印其位置。2 print(names.count("b"))#打印相同对象在列表中出现的次数5)其他的一些
1 names.clear()#清空整个表格2 names.reverse()#反转整个表格3 names.sort()#排序,按照ASCII码的顺序进行排列4 names2=["1","2","3"]5 names.extend(names2)#拓展表格6 print(names)
6)关于list_.copy()的一些用法
a.在只有一级列表的情况下,直接用copy是能够实现完全copy的,并且当names列表当中有元素变化时,names2是不会变化的。names=["a","b","c","d","e","b"]names2=names.copy()print(names)print(names2)#输出结果:[‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘b‘][‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘b‘]
b.在这里有两级列表,然后更改原始列表中的第一级的一个元素,names2当中并不会发生变化。
names=["a","b","c",[1,2,3],"d","e","b"]names2=names.copy()names[1]="B"print(names)print(names2)#输出结果:[‘a‘, ‘B‘, ‘c‘, [1, 2, 3], ‘d‘, ‘e‘, ‘b‘][‘a‘, ‘b‘, ‘c‘, [1, 2, 3], ‘d‘, ‘e‘, ‘b‘]
c、但是看下边,当二级列表中的元素发生改变时,names2也变了。
names=["a","b","c",[1,2,3],"d","e","b"]names2=names.copy()names[1]="B"names[3][1]="贰"print(names)print(names2)#输出结果:[‘a‘, ‘B‘, ‘c‘, [1, ‘贰‘, 3], ‘d‘, ‘e‘, ‘b‘][‘a‘, ‘b‘, ‘c‘, [1, ‘贰‘, 3], ‘d‘, ‘e‘, ‘b‘]
Python 入门学习第二部分:
评论关闭